 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimCS: Simulation for Online Domain-Incremental Continual Segmentation
Nov 29, 2022



Continual Learning is a step towards lifelong intelligence where models continuously learn from recently collected data without forgetting previous knowledge. Existing continual learning approaches mostly focus on image classification in the class-incremental setup with clear task boundaries and unlimited computational budget. This work explores Online Domain-Incremental Continual Segmentation~(ODICS), a real-world problem that arises in many applications, \eg, autonomous driving. In ODICS, the model is continually presented with batches of densely labeled images from different domains; computation is limited and no information about the task boundaries is available. In autonomous driving, this may correspond to the realistic scenario of training a segmentation model over time on a sequence of cities. We analyze several existing continual learning methods and show that they do not perform well in this setting despite working well in class-incremental segmentation. We propose SimCS, a parameter-free method complementary to existing ones that leverages simulated data as a continual learning regularizer. Extensive experiments show consistent improvements over different types of continual learning methods that use regularizers and even replay.
Generalizability of Adversarial Robustness Under Distribution Shifts
Sep 29, 2022
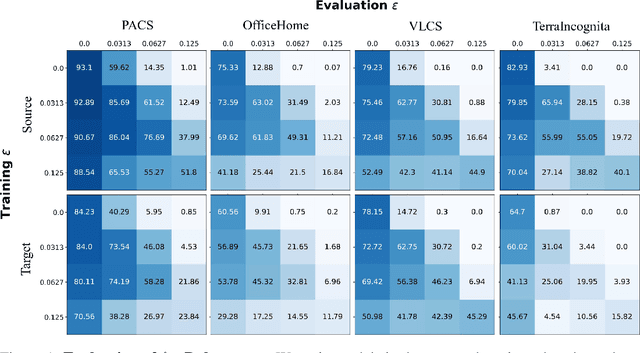
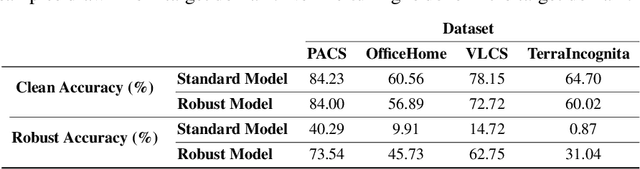
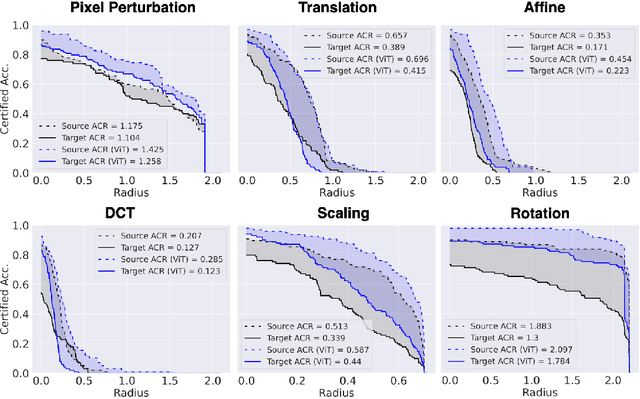
Recent progress in empirical and certified robustness promises to deliver reliable and deployable Deep Neural Networks (DNNs). Despite that success, most existing evaluations of DNN robustness have been done on images sampled from the same distribution that the model was trained on. Yet, in the real world, DNNs may be deployed in dynamic environments that exhibit significant distribution shifts. In this work, we take a first step towards thoroughly investigating the interplay between empirical and certified adversarial robustness on one hand and domain generalization on another. To do so, we train robust models on multiple domains and evaluate their accuracy and robustness on an unseen domain. We observe that: (1) both empirical and certified robustness generalize to unseen domains, and (2) the level of generalizability does not correlate well with input visual similarity, measured by the FID between source and target domains. We also extend our study to cover a real-world medical application, in which adversarial augmentation enhances both the robustness and generalization accuracy in unseen domains.
Certified Robustness in Federated Learning
Jun 06, 2022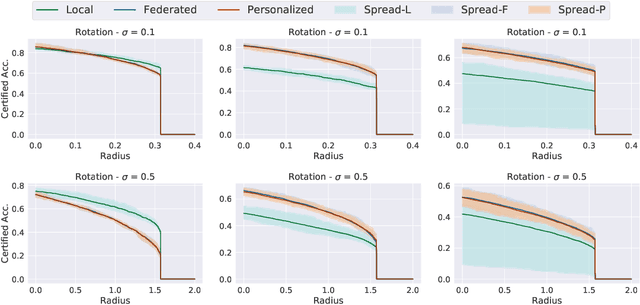
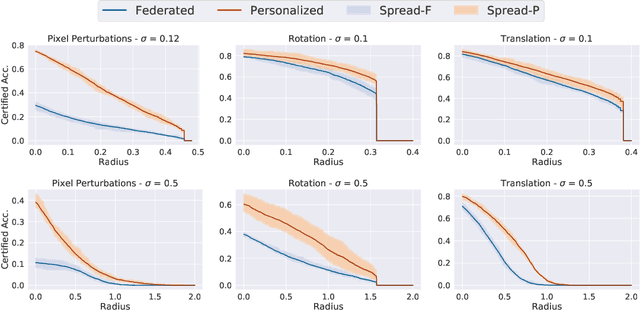

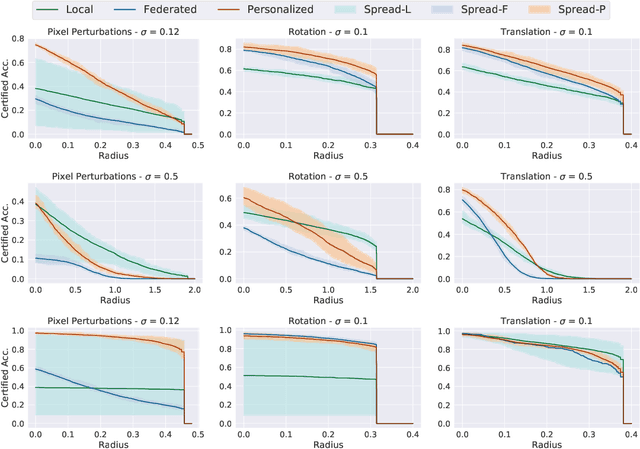
Federated learning has recently gained significant attention and popularity due to its effectiveness in training machine learning models on distributed data privately. However, as in the single-node supervised learning setup, models trained in federated learning suffer from vulnerability to imperceptible input transformations known as adversarial attacks, questioning their deployment in security-related applications. In this work, we study the interplay between federated training, personalization, and certified robustness. In particular, we deploy randomized smoothing, a widely-used and scalable certification method, to certify deep networks trained on a federated setup against input perturbations and transformations. We find that the simple federated averaging technique is effective in building not only more accurate, but also more certifiably-robust models, compared to training solely on local data. We further analyze personalization, a popular technique in federated training that increases the model's bias towards local data, on robustness. We show several advantages of personalization over both~(that is, only training on local data and federated training) in building more robust models with faster training. Finally, we explore the robustness of mixtures of global and local~(\ie personalized) models, and find that the robustness of local models degrades as they diverge from the global model
3DeformRS: Certifying Spatial Deformations on Point Clouds
Apr 12, 2022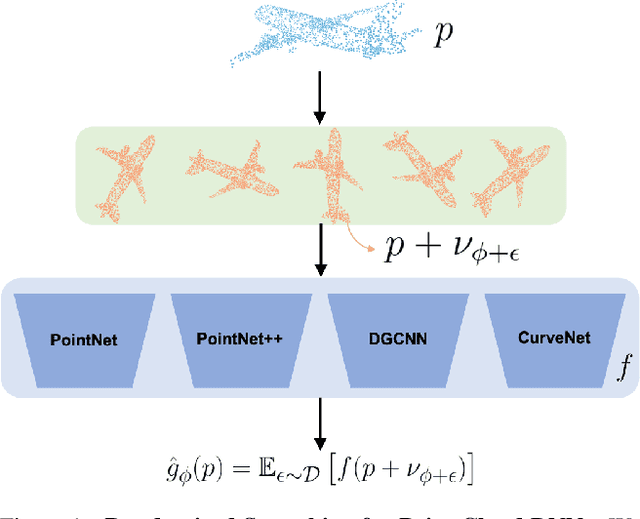



3D computer vision models are commonly used in security-critical applications such as autonomous driving and surgical robotics. Emerging concerns over the robustness of these models against real-world deformations must be addressed practically and reliably. In this work, we propose 3DeformRS, a method to certify the robustness of point cloud Deep Neural Networks (DNNs) against real-world deformations. We developed 3DeformRS by building upon recent work that generalized Randomized Smoothing (RS) from pixel-intensity perturbations to vector-field deformations. In particular, we specialized RS to certify DNNs against parameterized deformations (e.g. rotation, twisting), while enjoying practical computational costs. We leverage the virtues of 3DeformRS to conduct a comprehensive empirical study on the certified robustness of four representative point cloud DNNs on two datasets and against seven different deformations. Compared to previous approaches for certifying point cloud DNNs, 3DeformRS is fast, scales well with point cloud size, and provides comparable-to-better certificates. For instance, when certifying a plain PointNet against a 3{\deg} z-rotation on 1024-point clouds, 3DeformRS grants a certificate 3x larger and 20x faster than previous work.
Towards Assessing and Characterizing the Semantic Robustness of Face Recognition
Feb 10, 2022Deep Neural Networks (DNNs) lack robustness against imperceptible perturbations to their input. Face Recognition Models (FRMs) based on DNNs inherit this vulnerability. We propose a methodology for assessing and characterizing the robustness of FRMs against semantic perturbations to their input. Our methodology causes FRMs to malfunction by designing adversarial attacks that search for identity-preserving modifications to faces. In particular, given a face, our attacks find identity-preserving variants of the face such that an FRM fails to recognize the images belonging to the same identity. We model these identity-preserving semantic modifications via direction- and magnitude-constrained perturbations in the latent space of StyleGAN. We further propose to characterize the semantic robustness of an FRM by statistically describing the perturbations that induce the FRM to malfunction. Finally, we combine our methodology with a certification technique, thus providing (i) theoretical guarantees on the performance of an FRM, and (ii) a formal description of how an FRM may model the notion of face identity.
On the Robustness of Quality Measures for GANs
Jan 31, 2022
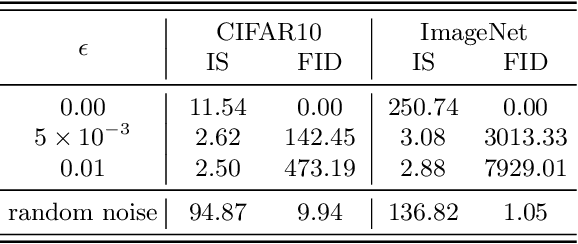


This work evaluates the robustness of quality measures of generative models such as Inception Score (IS) and Fr\'echet Inception Distance (FID). Analogous to the vulnerability of deep models against a variety of adversarial attacks, we show that such metrics can also be manipulated by additive pixel perturbations. Our experiments indicate that one can generate a distribution of images with very high scores but low perceptual quality. Conversely, one can optimize for small imperceptible perturbations that, when added to real world images, deteriorate their scores. Furthermore, we extend our evaluation to generative models themselves, including the state of the art network StyleGANv2. We show the vulnerability of both the generative model and the FID against additive perturbations in the latent space. Finally, we show that the FID can be robustified by directly replacing the Inception model by a robustly trained Inception. We validate the effectiveness of the robustified metric through extensive experiments, which show that it is more robust against manipulation.
Enhancing Adversarial Robustness via Test-time Transformation Ensembling
Jul 29, 2021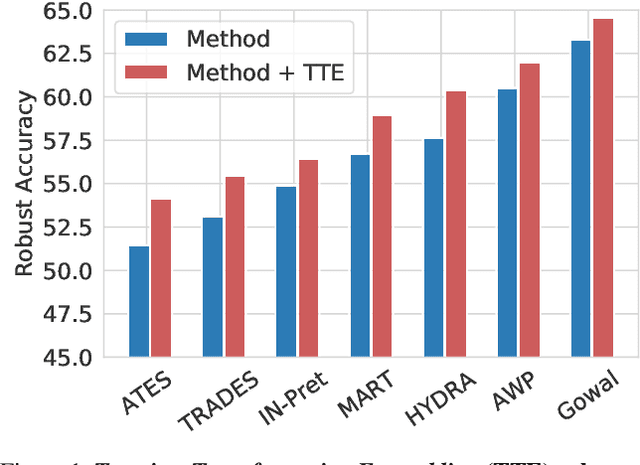
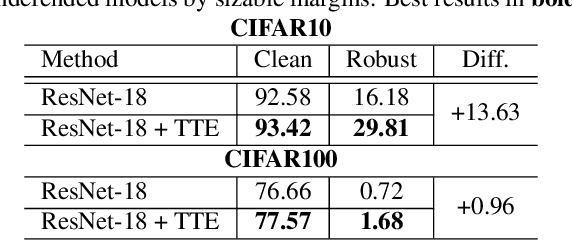
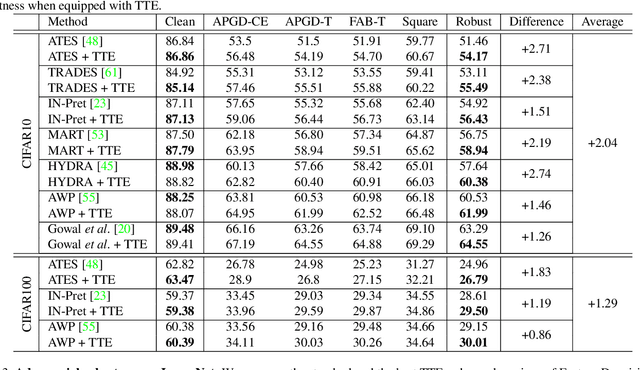
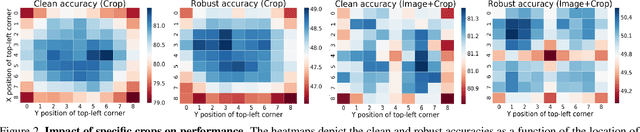
Deep learning models are prone to being fooled by imperceptible perturbations known as adversarial attacks. In this work, we study how equipping models with Test-time Transformation Ensembling (TTE) can work as a reliable defense against such attacks. While transforming the input data, both at train and test times, is known to enhance model performance, its effects on adversarial robustness have not been studied. Here, we present a comprehensive empirical study of the impact of TTE, in the form of widely-used image transforms, on adversarial robustness. We show that TTE consistently improves model robustness against a variety of powerful attacks without any need for re-training, and that this improvement comes at virtually no trade-off with accuracy on clean samples. Finally, we show that the benefits of TTE transfer even to the certified robustness domain, in which TTE provides sizable and consistent improvements.
ANCER: Anisotropic Certification via Sample-wise Volume Maximization
Jul 20, 2021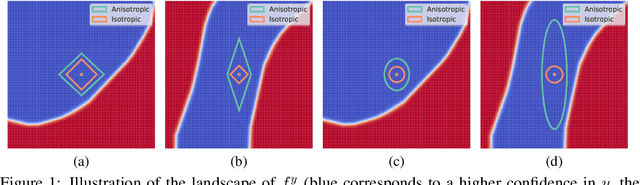
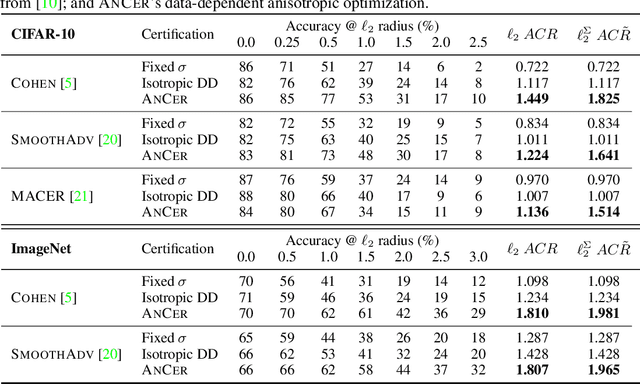

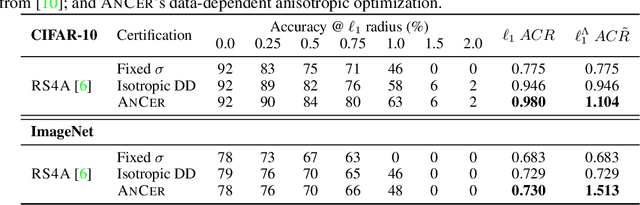
Randomized smoothing has recently emerged as an effective tool that enables certification of deep neural network classifiers at scale. All prior art on randomized smoothing has focused on isotropic $\ell_p$ certification, which has the advantage of yielding certificates that can be easily compared among isotropic methods via $\ell_p$-norm radius. However, isotropic certification limits the region that can be certified around an input to worst-case adversaries, i.e., it cannot reason about other "close", potentially large, constant prediction safe regions. To alleviate this issue, (i) we theoretically extend the isotropic randomized smoothing $\ell_1$ and $\ell_2$ certificates to their generalized anisotropic counterparts following a simplified analysis. Moreover, (ii) we propose evaluation metrics allowing for the comparison of general certificates - a certificate is superior to another if it certifies a superset region - with the quantification of each certificate through the volume of the certified region. We introduce ANCER, a practical framework for obtaining anisotropic certificates for a given test set sample via volume maximization. Our empirical results demonstrate that ANCER achieves state-of-the-art $\ell_1$ and $\ell_2$ certified accuracy on both CIFAR-10 and ImageNet at multiple radii, while certifying substantially larger regions in terms of volume, thus highlighting the benefits of moving away from isotropic analysis. Code used in our experiments is available in https://github.com/MotasemAlfarra/ANCER.
DeformRS: Certifying Input Deformations with Randomized Smoothing
Jul 02, 2021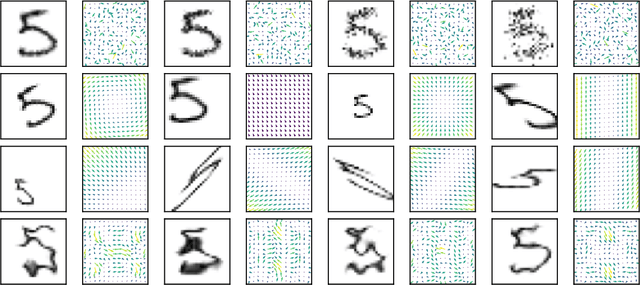


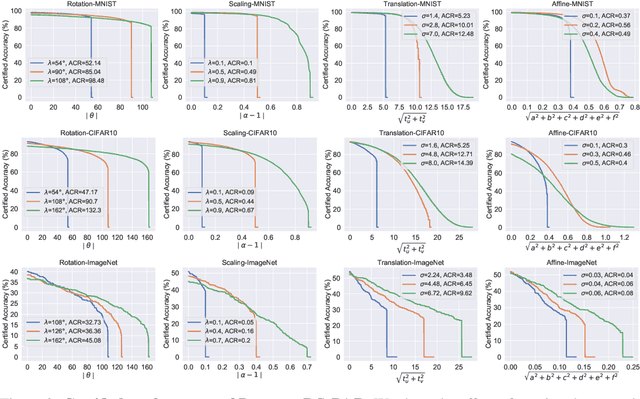
Deep neural networks are vulnerable to input deformations in the form of vector fields of pixel displacements and to other parameterized geometric deformations e.g. translations, rotations, etc. Current input deformation certification methods either (i) do not scale to deep networks on large input datasets, or (ii) can only certify a specific class of deformations, e.g. only rotations. We reformulate certification in randomized smoothing setting for both general vector field and parameterized deformations and propose DeformRS-VF and DeformRS-Par, respectively. Our new formulation scales to large networks on large input datasets. For instance, DeformRS-Par certifies rich deformations, covering translations, rotations, scaling, affine deformations, and other visually aligned deformations such as ones parameterized by Discrete-Cosine-Transform basis. Extensive experiments on MNIST, CIFAR10 and ImageNet show that DeformRS-Par outperforms existing state-of-the-art in certified accuracy, e.g. improved certified accuracy of 6% against perturbed rotations in the set [-10,10] degrees on ImageNet.
Combating Adversaries with Anti-Adversaries
Mar 26, 2021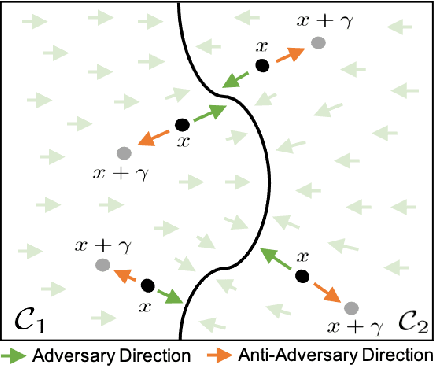
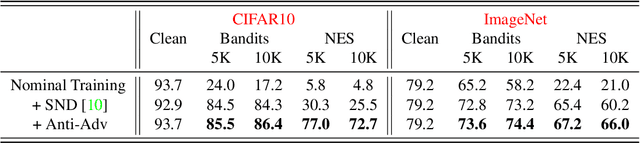
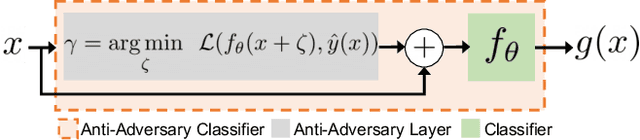
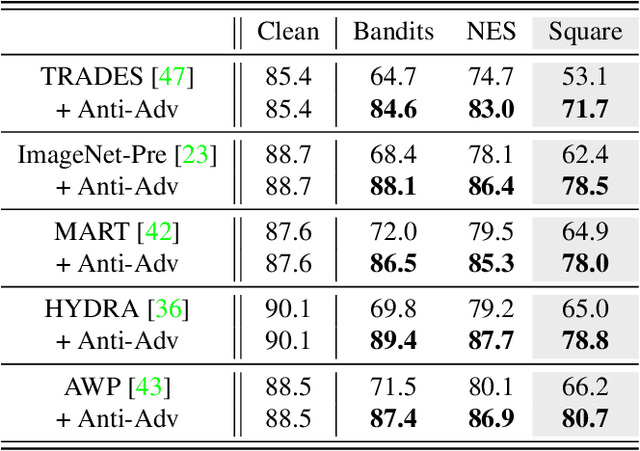
Deep neural networks are vulnerable to small input perturbations known as adversarial attacks. Inspired by the fact that these adversaries are constructed by iteratively minimizing the confidence of a network for the true class label, we propose the anti-adversary layer, aimed at countering this effect. In particular, our layer generates an input perturbation in the opposite direction of the adversarial one, and feeds the classifier a perturbed version of the input. Our approach is training-free and theoretically supported. We verify the effectiveness of our approach by combining our layer with both nominally and robustly trained models, and conduct large scale experiments from black-box to adaptive attacks on CIFAR10, CIFAR100 and ImageNet. Our anti-adversary layer significantly enhances model robustness while coming at no cost on clean accuracy.