 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShadowRemovalNet: Efficient Real-Time Shadow Removal
Mar 13, 2024Shadows significantly impact computer vision tasks, particularly in outdoor environments. State-of-the-art shadow removal methods are typically too computationally intensive for real-time image processing on edge hardware. We propose ShadowRemovalNet, a novel method designed for real-time image processing on resource-constrained hardware. ShadowRemovalNet achieves significantly higher frame rates compared to existing methods, making it suitable for real-time computer vision pipelines like those used in field robotics. Beyond speed, ShadowRemovalNet offers advantages in efficiency and simplicity, as it does not require a separate shadow mask during inference. ShadowRemovalNet also addresses challenges associated with Generative Adversarial Networks (GANs) for shadow removal, including artefacts, inaccurate mask estimations, and inconsistent supervision between shadow and boundary pixels. To address these limitations, we introduce a novel loss function that substantially reduces shadow removal errors. ShadowRemovalNet's efficiency and straightforwardness make it a robust and effective solution for real-time shadow removal in outdoor robotics and edge computing applications.
Stress Monitoring Using Low-Cost Electroencephalogram Devices: A Systematic Literature Review
Feb 28, 2024



Introduction. Low-cost health monitoring devices are increasingly being used for mental health related studies including stress. While cortisol response magnitude remains the gold standard indicator for stress assessment, a growing number of studies have started to use low-cost EEG devices as primary recorders of biomarker data. Methods. This study reviews published works contributing and/or using EEG devices for detecting stress and their associated machine learning methods. The reviewed works are selected to answer three general research questions and are then synthesized into four categories of stress assessment using EEG, low-cost EEG devices, available datasets for EEG-based stress measurement, and machine learning techniques for EEG-based stress measurement. Results. A number of studies were identified where low-cost EEG devices were utilized to record brain function during phases of stress and relaxation. These studies generally reported a high predictive accuracy rate, verified using a number of different machine learning validation methods and statistical approaches. Of these studies, 60% can be considered low-powered studies based on the small number of test subjects used during experimentation. Conclusion. Low-cost consumer grade wearable devices including EEG and wrist-based monitors are increasingly being used in stress-related studies. Standardization of EEG signal processing and importance of sensor location still requires further study, and research in this area will continue to provide improvements as more studies become available.
Precise Robotic Weed Spot-Spraying for Reduced Herbicide Usage and Improved Environmental Outcomes -- A Real-World Case Study
Jan 25, 2024



Precise robotic weed control plays an essential role in precision agriculture. It can help significantly reduce the environmental impact of herbicides while reducing weed management costs for farmers. In this paper, we demonstrate that a custom-designed robotic spot spraying tool based on computer vision and deep learning can significantly reduce herbicide usage on sugarcane farms. We present results from field trials that compare robotic spot spraying against industry-standard broadcast spraying, by measuring the weed control efficacy, the reduction in herbicide usage, and the water quality improvements in irrigation runoff. The average results across 25 hectares of field trials show that spot spraying on sugarcane farms is 97% as effective as broadcast spraying and reduces herbicide usage by 35%, proportionally to the weed density. For specific trial strips with lower weed pressure, spot spraying reduced herbicide usage by up to 65%. Water quality measurements of irrigation-induced runoff, three to six days after spraying, showed reductions in the mean concentration and mean load of herbicides of 39% and 54%, respectively, compared to broadcast spraying. These promising results reveal the capability of spot spraying technology to reduce herbicide usage on sugarcane farms without impacting weed control and potentially providing sustained water quality benefits.
WeedCLR: Weed Contrastive Learning through Visual Representations with Class-Optimized Loss in Long-Tailed Datasets
Oct 19, 2023Image classification is a crucial task in modern weed management and crop intervention technologies. However, the limited size, diversity, and balance of existing weed datasets hinder the development of deep learning models for generalizable weed identification. In addition, the expensive labelling requirements of mainstream fully-supervised weed classifiers make them cost- and time-prohibitive to deploy widely, for new weed species, and in site-specific weed management. This paper proposes a novel method for Weed Contrastive Learning through visual Representations (WeedCLR), that uses class-optimized loss with Von Neumann Entropy of deep representation for weed classification in long-tailed datasets. WeedCLR leverages self-supervised learning to learn rich and robust visual features without any labels and applies a class-optimized loss function to address the class imbalance problem in long-tailed datasets. WeedCLR is evaluated on two public weed datasets: CottonWeedID15, containing 15 weed species, and DeepWeeds, containing 8 weed species. WeedCLR achieves an average accuracy improvement of 4.3\% on CottonWeedID15 and 5.6\% on DeepWeeds over previous methods. It also demonstrates better generalization ability and robustness to different environmental conditions than existing methods without the need for expensive and time-consuming human annotations. These significant improvements make WeedCLR an effective tool for weed classification in long-tailed datasets and allows for more rapid and widespread deployment of site-specific weed management and crop intervention technologies.
V2X Cooperative Perception for Autonomous Driving: Recent Advances and Challenges
Oct 05, 2023



Accurate perception is essential for advancing autonomous driving and addressing safety challenges in modern transportation systems. Despite significant advancements in computer vision for object recognition, current perception methods still face difficulties in complex real-world traffic environments. Challenges such as physical occlusion and limited sensor field of view persist for individual vehicle systems. Cooperative Perception (CP) with Vehicle-to-Everything (V2X) technologies has emerged as a solution to overcome these obstacles and enhance driving automation systems. While some research has explored CP's fundamental architecture and critical components, there remains a lack of comprehensive summaries of the latest innovations, particularly in the context of V2X communication technologies. To address this gap, this paper provides a comprehensive overview of the evolution of CP technologies, spanning from early explorations to recent developments, including advancements in V2X communication technologies. Additionally, a contemporary generic framework is proposed to illustrate the V2X-based CP workflow, aiding in the structured understanding of CP system components. Furthermore, this paper categorizes prevailing V2X-based CP methodologies based on the critical issues they address. An extensive literature review is conducted within this taxonomy, evaluating existing datasets and simulators. Finally, open challenges and future directions in CP for autonomous driving are discussed by considering both perception and V2X communication advancements.
Prawn Morphometrics and Weight Estimation from Images using Deep Learning for Landmark Localization
Jul 15, 2023



Accurate weight estimation and morphometric analyses are useful in aquaculture for optimizing feeding, predicting harvest yields, identifying desirable traits for selective breeding, grading processes, and monitoring the health status of production animals. However, the collection of phenotypic data through traditional manual approaches at industrial scales and in real-time is time-consuming, labour-intensive, and prone to errors. Digital imaging of individuals and subsequent training of prediction models using Deep Learning (DL) has the potential to rapidly and accurately acquire phenotypic data from aquaculture species. In this study, we applied a novel DL approach to automate weight estimation and morphometric analysis using the black tiger prawn (Penaeus monodon) as a model crustacean. The DL approach comprises two main components: a feature extraction module that efficiently combines low-level and high-level features using the Kronecker product operation; followed by a landmark localization module that then uses these features to predict the coordinates of key morphological points (landmarks) on the prawn body. Once these landmarks were extracted, weight was estimated using a weight regression module based on the extracted landmarks using a fully connected network. For morphometric analyses, we utilized the detected landmarks to derive five important prawn traits. Principal Component Analysis (PCA) was also used to identify landmark-derived distances, which were found to be highly correlated with shape features such as body length, and width. We evaluated our approach on a large dataset of 8164 images of the Black tiger prawn (Penaeus monodon) collected from Australian farms. Our experimental results demonstrate that the novel DL approach outperforms existing DL methods in terms of accuracy, robustness, and efficiency.
Security and Privacy Problems in Voice Assistant Applications: A Survey
Apr 19, 2023Voice assistant applications have become omniscient nowadays. Two models that provide the two most important functions for real-life applications (i.e., Google Home, Amazon Alexa, Siri, etc.) are Automatic Speech Recognition (ASR) models and Speaker Identification (SI) models. According to recent studies, security and privacy threats have also emerged with the rapid development of the Internet of Things (IoT). The security issues researched include attack techniques toward machine learning models and other hardware components widely used in voice assistant applications. The privacy issues include technical-wise information stealing and policy-wise privacy breaches. The voice assistant application takes a steadily growing market share every year, but their privacy and security issues never stopped causing huge economic losses and endangering users' personal sensitive information. Thus, it is important to have a comprehensive survey to outline the categorization of the current research regarding the security and privacy problems of voice assistant applications. This paper concludes and assesses five kinds of security attacks and three types of privacy threats in the papers published in the top-tier conferences of cyber security and voice domain.
Adaptive Uncertainty Distribution in Deep Learning for Unsupervised Underwater Image Enhancement
Dec 18, 2022One of the main challenges in deep learning-based underwater image enhancement is the limited availability of high-quality training data. Underwater images are difficult to capture and are often of poor quality due to the distortion and loss of colour and contrast in water. This makes it difficult to train supervised deep learning models on large and diverse datasets, which can limit the model's performance. In this paper, we explore an alternative approach to supervised underwater image enhancement. Specifically, we propose a novel unsupervised underwater image enhancement framework that employs a conditional variational autoencoder (cVAE) to train a deep learning model with probabilistic adaptive instance normalization (PAdaIN) and statistically guided multi-colour space stretch that produces realistic underwater images. The resulting framework is composed of a U-Net as a feature extractor and a PAdaIN to encode the uncertainty, which we call UDnet. To improve the visual quality of the images generated by UDnet, we use a statistically guided multi-colour space stretch module that ensures visual consistency with the input image and provides an alternative to training using a ground truth image. The proposed model does not need manual human annotation and can learn with a limited amount of data and achieves state-of-the-art results on underwater images. We evaluated our proposed framework on eight publicly-available datasets. The results show that our proposed framework yields competitive performance compared to other state-of-the-art approaches in quantitative as well as qualitative metrics. Code available at https://github.com/alzayats/UDnet .
Ensemble Machine Learning Model Trained on a New Synthesized Dataset Generalizes Well for Stress Prediction Using Wearable Devices
Sep 30, 2022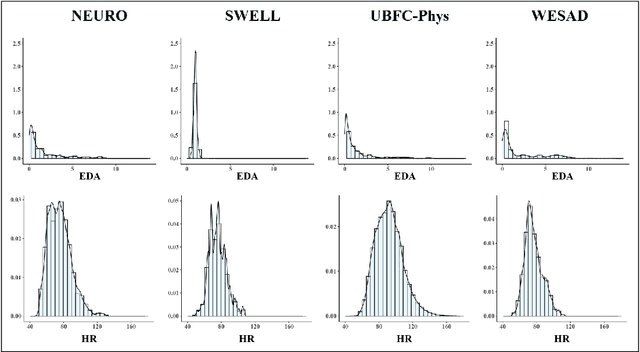
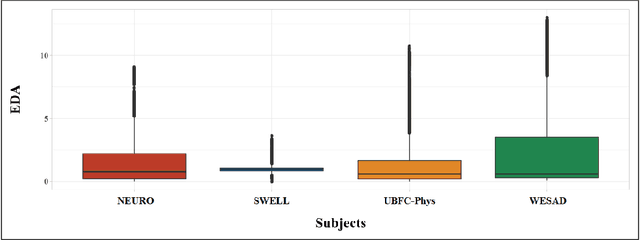
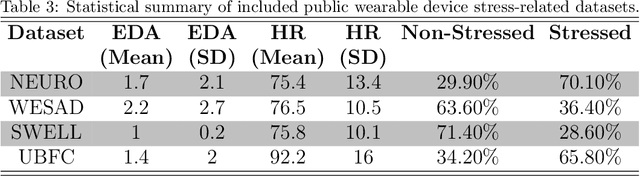
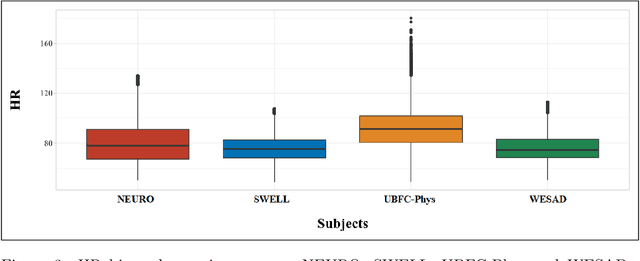
Introduction. We investigate the generalization ability of models built on datasets containing a small number of subjects, recorded in single study protocols. Next, we propose and evaluate methods combining these datasets into a single, large dataset. Finally, we propose and evaluate the use of ensemble techniques by combining gradient boosting with an artificial neural network to measure predictive power on new, unseen data. Methods. Sensor biomarker data from six public datasets were utilized in this study. To test model generalization, we developed a gradient boosting model trained on one dataset (SWELL), and tested its predictive power on two datasets previously used in other studies (WESAD, NEURO). Next, we merged four small datasets, i.e. (SWELL, NEURO, WESAD, UBFC-Phys), to provide a combined total of 99 subjects,. In addition, we utilized random sampling combined with another dataset (EXAM) to build a larger training dataset consisting of 200 synthesized subjects,. Finally, we developed an ensemble model that combines our gradient boosting model with an artificial neural network, and tested it on two additional, unseen publicly available stress datasets (WESAD and Toadstool). Results. Our method delivers a robust stress measurement system capable of achieving 85% predictive accuracy on new, unseen validation data, achieving a 25% performance improvement over single models trained on small datasets. Conclusion. Models trained on small, single study protocol datasets do not generalize well for use on new, unseen data and lack statistical power. Ma-chine learning models trained on a dataset containing a larger number of varied study subjects capture physiological variance better, resulting in more robust stress detection.
Machine Learning for Stress Monitoring from Wearable Devices: A Systematic Literature Review
Sep 29, 2022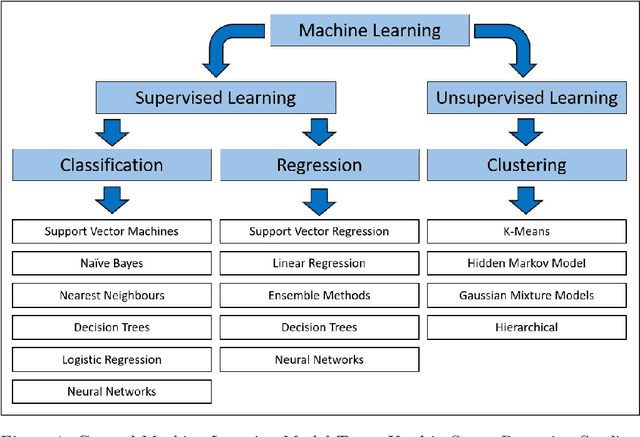
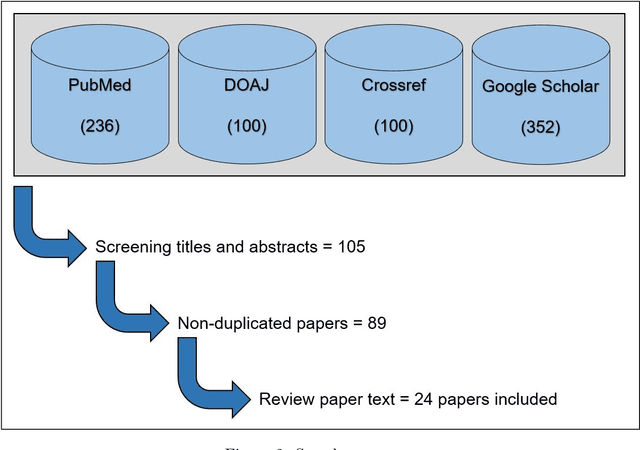
Introduction. The stress response has both subjective, psychological and objectively measurable, biological components. Both of them can be expressed differently from person to person, complicating the development of a generic stress measurement model. This is further compounded by the lack of large, labeled datasets that can be utilized to build machine learning models for accurately detecting periods and levels of stress. The aim of this review is to provide an overview of the current state of stress detection and monitoring using wearable devices, and where applicable, machine learning techniques utilized. Methods. This study reviewed published works contributing and/or using datasets designed for detecting stress and their associated machine learning methods, with a systematic review and meta-analysis of those that utilized wearable sensor data as stress biomarkers. The electronic databases of Google Scholar, Crossref, DOAJ and PubMed were searched for relevant articles and a total of 24 articles were identified and included in the final analysis. The reviewed works were synthesized into three categories of publicly available stress datasets, machine learning, and future research directions. Results. A wide variety of study-specific test and measurement protocols were noted in the literature. A number of public datasets were identified that are labeled for stress detection. In addition, we discuss that previous works show shortcomings in areas such as their labeling protocols, lack of statistical power, validity of stress biomarkers, and generalization ability. Conclusion. Generalization of existing machine learning models still require further study, and research in this area will continue to provide improvements as newer and more substantial datasets become available for study.