 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Block Coordinate Ascent Algorithm for Mean-Variance Optimization
Nov 01, 2018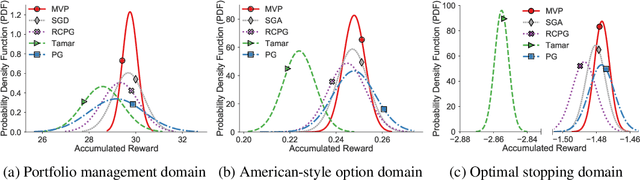
Risk management in dynamic decision problems is a primary concern in many fields, including financial investment, autonomous driving, and healthcare. The mean-variance function is one of the most widely used objective functions in risk management due to its simplicity and interpretability. Existing algorithms for mean-variance optimization are based on multi-time-scale stochastic approximation, whose learning rate schedules are often hard to tune, and have only asymptotic convergence proof. In this paper, we develop a model-free policy search framework for mean-variance optimization with finite-sample error bound analysis (to local optima). Our starting point is a reformulation of the original mean-variance function with its Fenchel dual, from which we propose a stochastic block coordinate ascent policy search algorithm. Both the asymptotic convergence guarantee of the last iteration's solution and the convergence rate of the randomly picked solution are provided, and their applicability is demonstrated on several benchmark domains.
Risk-Sensitive Generative Adversarial Imitation Learning
Aug 13, 2018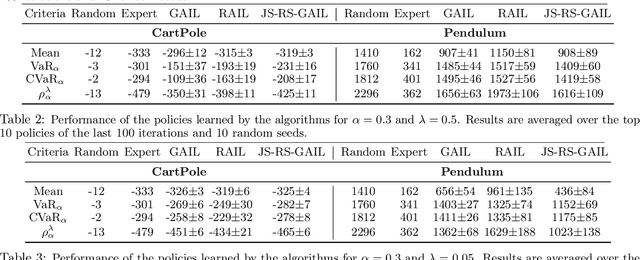
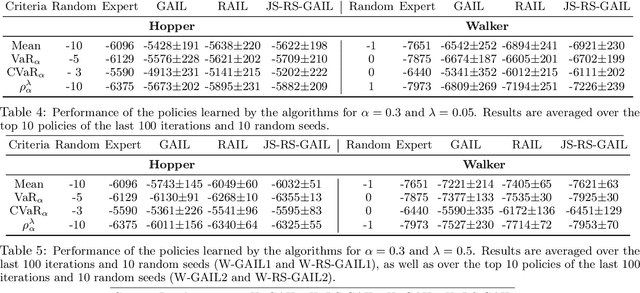
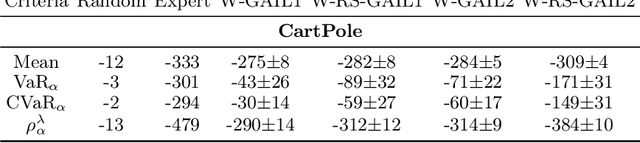
We study risk-sensitive imitation learning where the agent's goal is to perform at least as well as the expert in terms of a risk profile. We first formulate our risk-sensitive imitation learning setting. We consider the generative adversarial approach to imitation learning (GAIL) and derive an optimization problem for our formulation, which we call risk-sensitive GAIL (RS-GAIL). We then derive two different versions of our RS-GAIL optimization problem that aim at matching the risk profiles of the agent and the expert w.r.t. Jensen-Shannon (JS) divergence and Wasserstein distance, and develop risk-sensitive generative adversarial imitation learning algorithms based on these optimization problems. We evaluate the performance of our JS-based algorithm and compare it with GAIL and the risk-averse imitation learning (RAIL) algorithm in two MuJoCo tasks.
Model-Independent Online Learning for Influence Maximization
May 24, 2018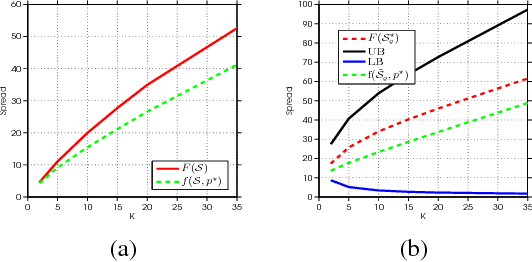
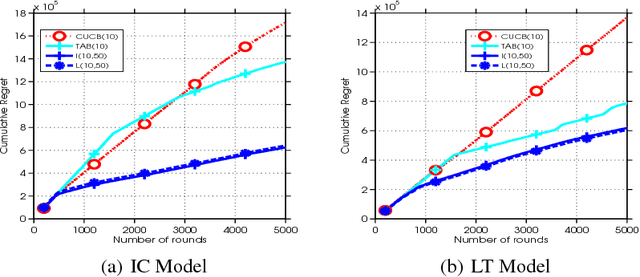
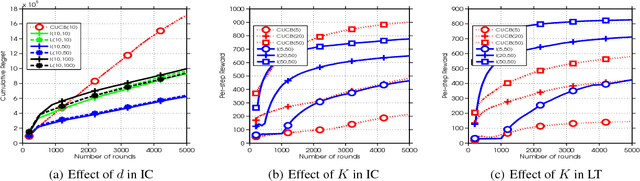
We consider influence maximization (IM) in social networks, which is the problem of maximizing the number of users that become aware of a product by selecting a set of "seed" users to expose the product to. While prior work assumes a known model of information diffusion, we propose a novel parametrization that not only makes our framework agnostic to the underlying diffusion model, but also statistically efficient to learn from data. We give a corresponding monotone, submodular surrogate function, and show that it is a good approximation to the original IM objective. We also consider the case of a new marketer looking to exploit an existing social network, while simultaneously learning the factors governing information propagation. For this, we propose a pairwise-influence semi-bandit feedback model and develop a LinUCB-based bandit algorithm. Our model-independent analysis shows that our regret bound has a better (as compared to previous work) dependence on the size of the network. Experimental evaluation suggests that our framework is robust to the underlying diffusion model and can efficiently learn a near-optimal solution.
More Robust Doubly Robust Off-policy Evaluation
May 23, 2018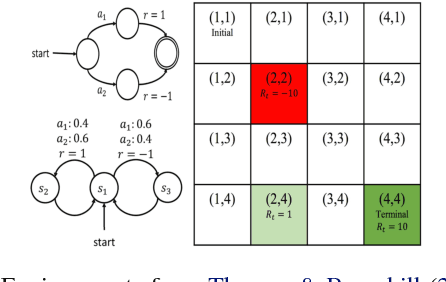
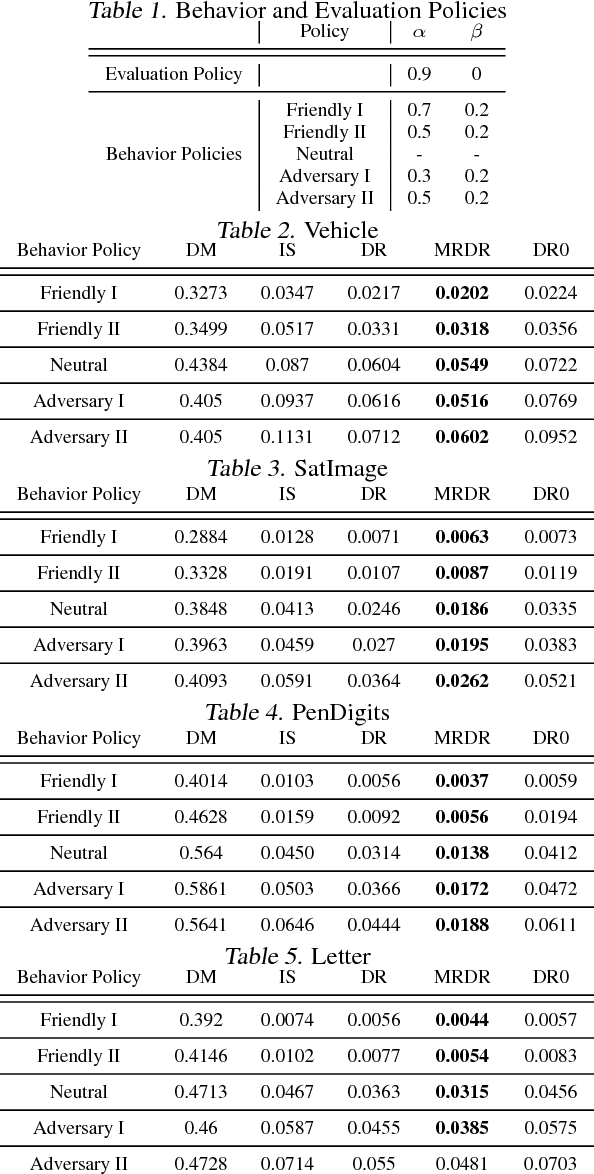
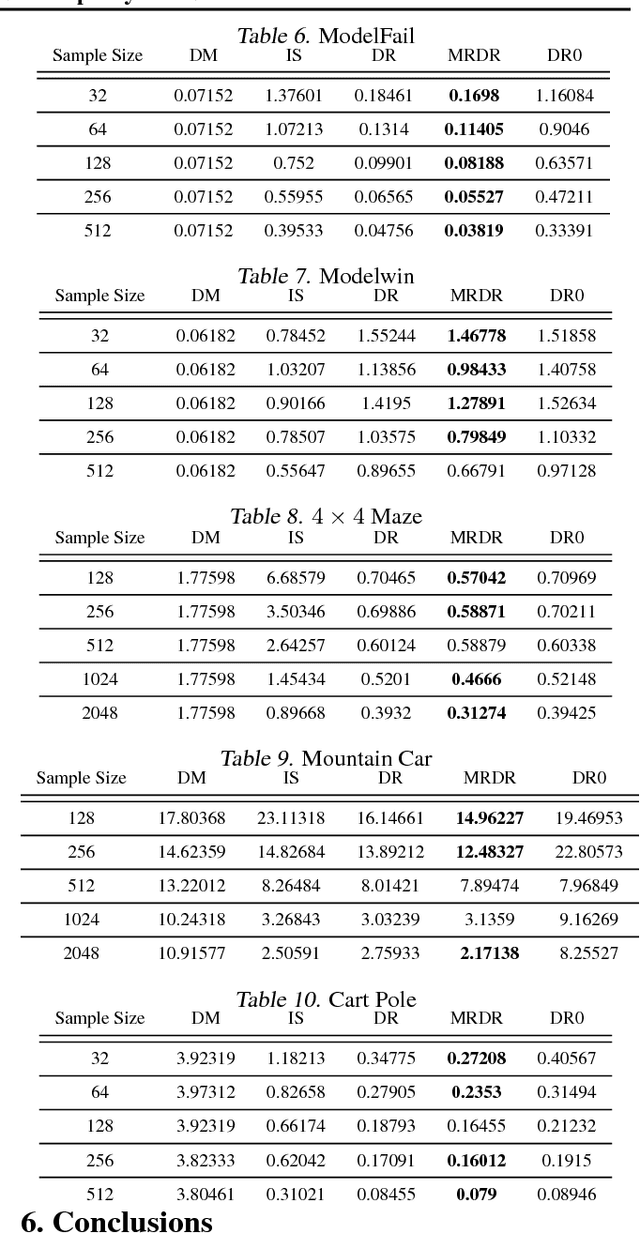

We study the problem of off-policy evaluation (OPE) in reinforcement learning (RL), where the goal is to estimate the performance of a policy from the data generated by another policy(ies). In particular, we focus on the doubly robust (DR) estimators that consist of an importance sampling (IS) component and a performance model, and utilize the low (or zero) bias of IS and low variance of the model at the same time. Although the accuracy of the model has a huge impact on the overall performance of DR, most of the work on using the DR estimators in OPE has been focused on improving the IS part, and not much on how to learn the model. In this paper, we propose alternative DR estimators, called more robust doubly robust (MRDR), that learn the model parameter by minimizing the variance of the DR estimator. We first present a formulation for learning the DR model in RL. We then derive formulas for the variance of the DR estimator in both contextual bandits and RL, such that their gradients w.r.t.~the model parameters can be estimated from the samples, and propose methods to efficiently minimize the variance. We prove that the MRDR estimators are strongly consistent and asymptotically optimal. Finally, we evaluate MRDR in bandits and RL benchmark problems, and compare its performance with the existing methods.
A Lyapunov-based Approach to Safe Reinforcement Learning
May 20, 2018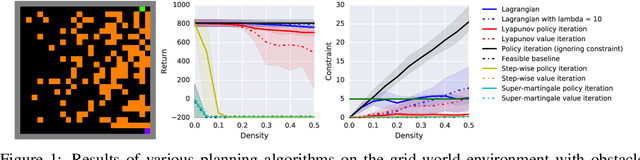
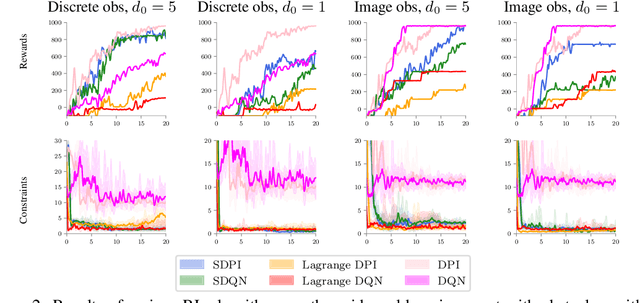
In many real-world reinforcement learning (RL) problems, besides optimizing the main objective function, an agent must concurrently avoid violating a number of constraints. In particular, besides optimizing performance it is crucial to guarantee the safety of an agent during training as well as deployment (e.g. a robot should avoid taking actions - exploratory or not - which irrevocably harm its hardware). To incorporate safety in RL, we derive algorithms under the framework of constrained Markov decision problems (CMDPs), an extension of the standard Markov decision problems (MDPs) augmented with constraints on expected cumulative costs. Our approach hinges on a novel \emph{Lyapunov} method. We define and present a method for constructing Lyapunov functions, which provide an effective way to guarantee the global safety of a behavior policy during training via a set of local, linear constraints. Leveraging these theoretical underpinnings, we show how to use the Lyapunov approach to systematically transform dynamic programming (DP) and RL algorithms into their safe counterparts. To illustrate their effectiveness, we evaluate these algorithms in several CMDP planning and decision-making tasks on a safety benchmark domain. Our results show that our proposed method significantly outperforms existing baselines in balancing constraint satisfaction and performance.
Optimizing over a Restricted Policy Class in Markov Decision Processes
Feb 26, 2018
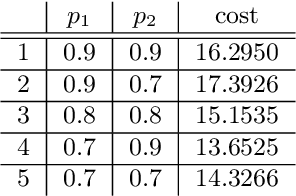
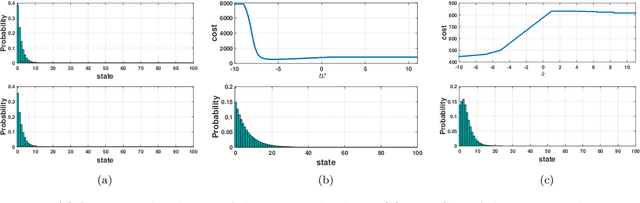
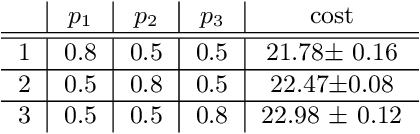
We address the problem of finding an optimal policy in a Markov decision process under a restricted policy class defined by the convex hull of a set of base policies. This problem is of great interest in applications in which a number of reasonably good (or safe) policies are already known and we are only interested in optimizing in their convex hull. We show that this problem is NP-hard to solve exactly as well as to approximate to arbitrary accuracy. However, under a condition that is akin to the occupancy measures of the base policies having large overlap, we show that there exists an efficient algorithm that finds a policy that is almost as good as the best convex combination of the base policies. The running time of the proposed algorithm is linear in the number of states and polynomial in the number of base policies. In practice, we demonstrate an efficient implementation for large state problems. Compared to traditional policy gradient methods, the proposed approach has the advantage that, apart from the computation of occupancy measures of some base policies, the iterative method need not interact with the environment during the optimization process. This is especially important in complex systems where estimating the value of a policy can be a time consuming process.
Robust Locally-Linear Controllable Embedding
Feb 21, 2018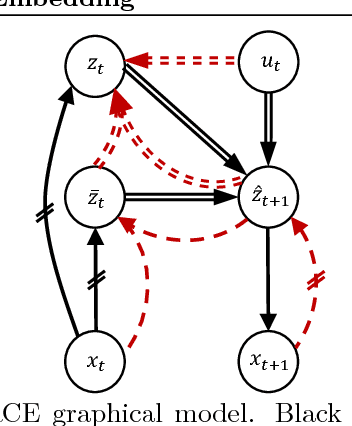
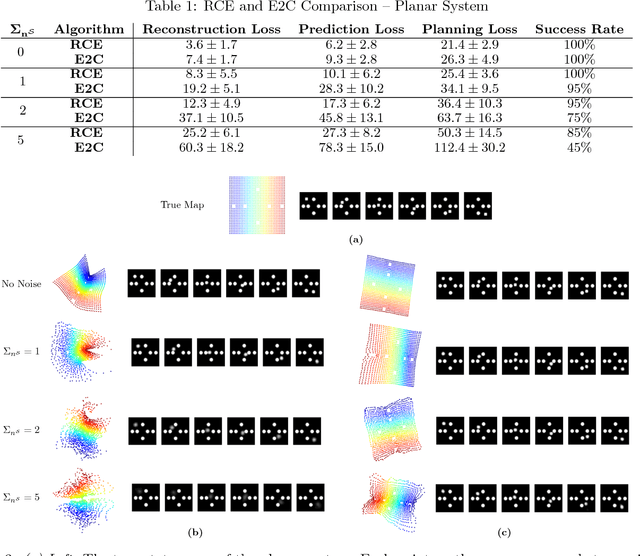
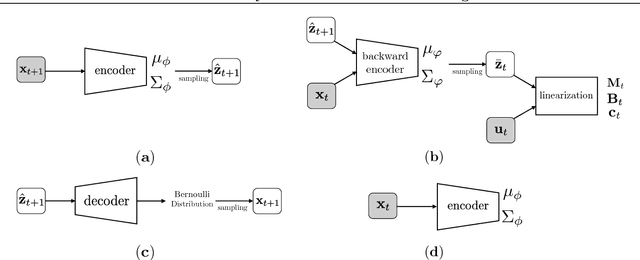
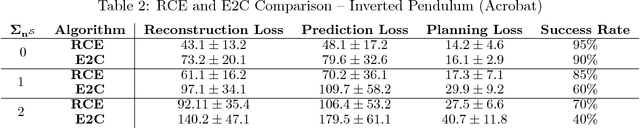
Embed-to-control (E2C) is a model for solving high-dimensional optimal control problems by combining variational auto-encoders with locally-optimal controllers. However, the E2C model suffers from two major drawbacks: 1) its objective function does not correspond to the likelihood of the data sequence and 2) the variational encoder used for embedding typically has large variational approximation error, especially when there is noise in the system dynamics. In this paper, we present a new model for learning robust locally-linear controllable embedding (RCE). Our model directly estimates the predictive conditional density of the future observation given the current one, while introducing the bottleneck between the current and future observations. Although the bottleneck provides a natural embedding candidate for control, our RCE model introduces additional specific structures in the generative graphical model so that the model dynamics can be robustly linearized. We also propose a principled variational approximation of the embedding posterior that takes the future observation into account, and thus, makes the variational approximation more robust against the noise. Experimental results show that RCE outperforms the E2C model, and does so significantly when the underlying dynamics is noisy.
Path Consistency Learning in Tsallis Entropy Regularized MDPs
Feb 10, 2018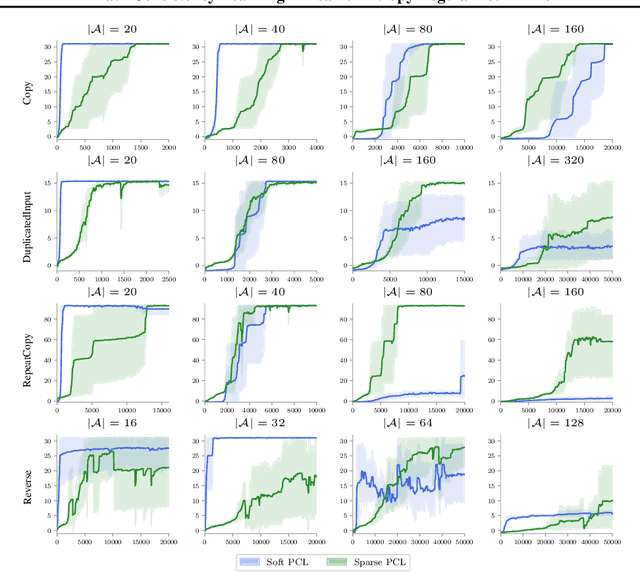
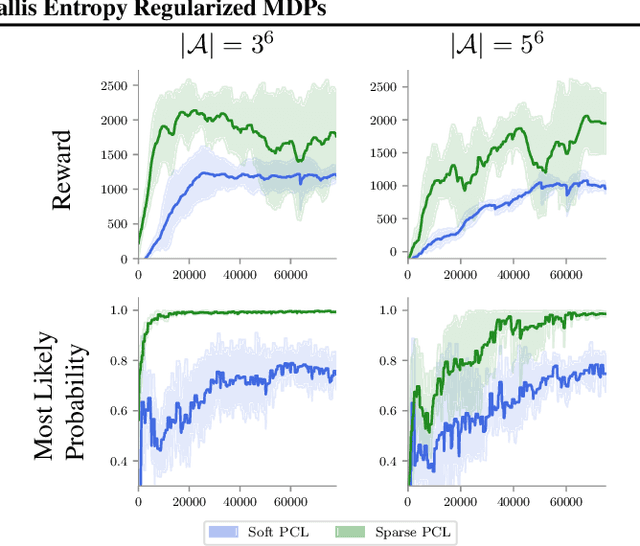
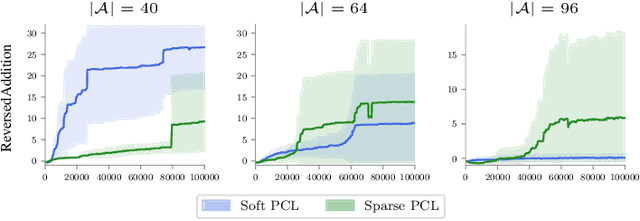
We study the sparse entropy-regularized reinforcement learning (ERL) problem in which the entropy term is a special form of the Tsallis entropy. The optimal policy of this formulation is sparse, i.e.,~at each state, it has non-zero probability for only a small number of actions. This addresses the main drawback of the standard Shannon entropy-regularized RL (soft ERL) formulation, in which the optimal policy is softmax, and thus, may assign a non-negligible probability mass to non-optimal actions. This problem is aggravated as the number of actions is increased. In this paper, we follow the work of Nachum et al. (2017) in the soft ERL setting, and propose a class of novel path consistency learning (PCL) algorithms, called {\em sparse PCL}, for the sparse ERL problem that can work with both on-policy and off-policy data. We first derive a {\em sparse consistency} equation that specifies a relationship between the optimal value function and policy of the sparse ERL along any system trajectory. Crucially, a weak form of the converse is also true, and we quantify the sub-optimality of a policy which satisfies sparse consistency, and show that as we increase the number of actions, this sub-optimality is better than that of the soft ERL optimal policy. We then use this result to derive the sparse PCL algorithms. We empirically compare sparse PCL with its soft counterpart, and show its advantage, especially in problems with a large number of actions.
Disentangling Dynamics and Content for Control and Planning
Nov 24, 2017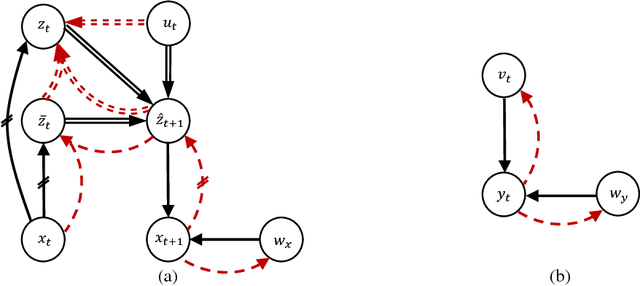
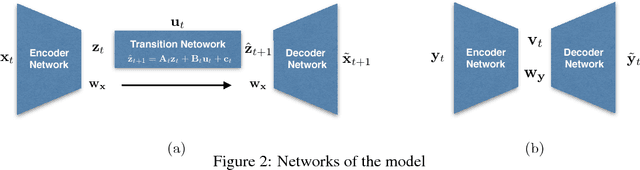
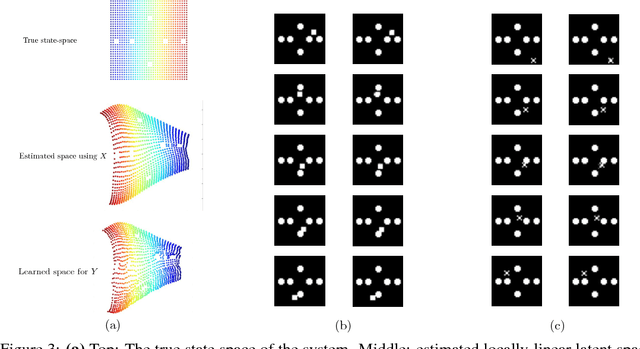
In this paper, We study the problem of learning a controllable representation for high-dimensional observations of dynamical systems. Specifically, we consider a situation where there are multiple sets of observations of dynamical systems with identical underlying dynamics. Only one of these sets has information about the effect of actions on the observation and the rest are just some random observations of the system. Our goal is to utilize the information in that one set and find a representation for the other sets that can be used for planning and ling-term prediction.
Active Learning for Accurate Estimation of Linear Models
Jul 29, 2017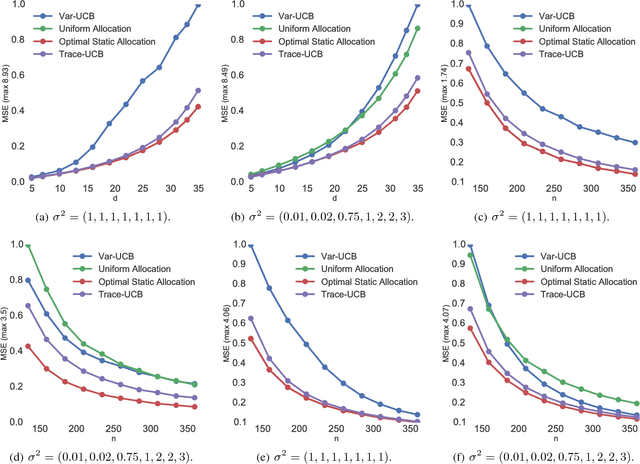
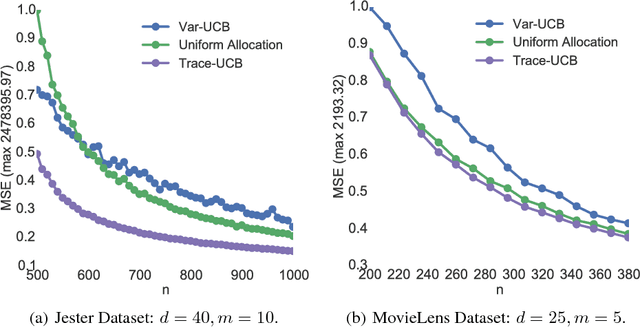
We explore the sequential decision making problem where the goal is to estimate uniformly well a number of linear models, given a shared budget of random contexts independently sampled from a known distribution. The decision maker must query one of the linear models for each incoming context, and receives an observation corrupted by noise levels that are unknown, and depend on the model instance. We present Trace-UCB, an adaptive allocation algorithm that learns the noise levels while balancing contexts accordingly across the different linear functions, and derive guarantees for simple regret in both expectation and high-probability. Finally, we extend the algorithm and its guarantees to high dimensional settings, where the number of linear models times the dimension of the contextual space is higher than the total budget of samples. Simulations with real data suggest that Trace-UCB is remarkably robust, outperforming a number of baselines even when its assumptions are violated.