 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Feature Generator for Few-Shot Learning
Sep 21, 2024



Few-shot learning (FSL) aims to enable models to recognize novel objects or classes with limited labelled data. Feature generators, which synthesize new data points to augment limited datasets, have emerged as a promising solution to this challenge. This paper investigates the effectiveness of feature generators in enhancing the embedding process for FSL tasks. To address the issue of inaccurate embeddings due to the scarcity of images per class, we introduce a feature generator that creates visual features from class-level textual descriptions. By training the generator with a combination of classifier loss, discriminator loss, and distance loss between the generated features and true class embeddings, we ensure the generation of accurate same-class features and enhance the overall feature representation. Our results show a significant improvement in accuracy over baseline methods, with our approach outperforming the baseline model by 10% in 1-shot and around 5% in 5-shot approaches. Additionally, both visual-only and visual + textual generators have also been tested in this paper.
Revisiting Kernel Temporal Segmentation as an Adaptive Tokenizer for Long-form Video Understanding
Sep 20, 2023



While most modern video understanding models operate on short-range clips, real-world videos are often several minutes long with semantically consistent segments of variable length. A common approach to process long videos is applying a short-form video model over uniformly sampled clips of fixed temporal length and aggregating the outputs. This approach neglects the underlying nature of long videos since fixed-length clips are often redundant or uninformative. In this paper, we aim to provide a generic and adaptive sampling approach for long-form videos in lieu of the de facto uniform sampling. Viewing videos as semantically consistent segments, we formulate a task-agnostic, unsupervised, and scalable approach based on Kernel Temporal Segmentation (KTS) for sampling and tokenizing long videos. We evaluate our method on long-form video understanding tasks such as video classification and temporal action localization, showing consistent gains over existing approaches and achieving state-of-the-art performance on long-form video modeling.
3DLatNav: Navigating Generative Latent Spaces for Semantic-Aware 3D Object Manipulation
Nov 17, 2022



3D generative models have been recently successful in generating realistic 3D objects in the form of point clouds. However, most models do not offer controllability to manipulate the shape semantics of component object parts without extensive semantic attribute labels or other reference point clouds. Moreover, beyond the ability to perform simple latent vector arithmetic or interpolations, there is a lack of understanding of how part-level semantics of 3D shapes are encoded in their corresponding generative latent spaces. In this paper, we propose 3DLatNav; a novel approach to navigating pretrained generative latent spaces to enable controlled part-level semantic manipulation of 3D objects. First, we propose a part-level weakly-supervised shape semantics identification mechanism using latent representations of 3D shapes. Then, we transfer that knowledge to a pretrained 3D object generative latent space to unravel disentangled embeddings to represent different shape semantics of component parts of an object in the form of linear subspaces, despite the unavailability of part-level labels during the training. Finally, we utilize those identified subspaces to show that controllable 3D object part manipulation can be achieved by applying the proposed framework to any pretrained 3D generative model. With two novel quantitative metrics to evaluate the consistency and localization accuracy of part-level manipulations, we show that 3DLatNav outperforms existing unsupervised latent disentanglement methods in identifying latent directions that encode part-level shape semantics of 3D objects. With multiple ablation studies and testing on state-of-the-art generative models, we show that 3DLatNav can implement controlled part-level semantic manipulations on an input point cloud while preserving other features and the realistic nature of the object.
CrossPoint: Self-Supervised Cross-Modal Contrastive Learning for 3D Point Cloud Understanding
Mar 24, 2022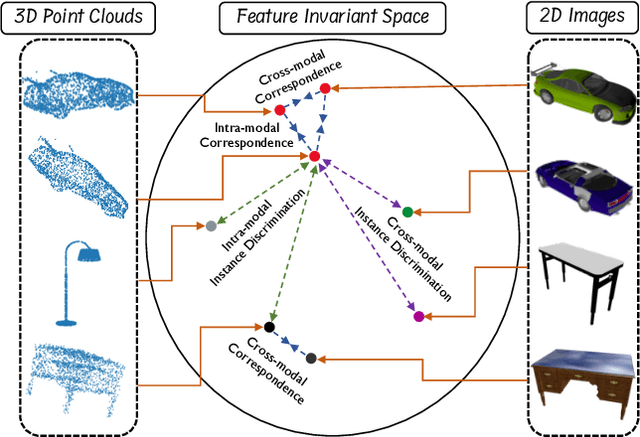
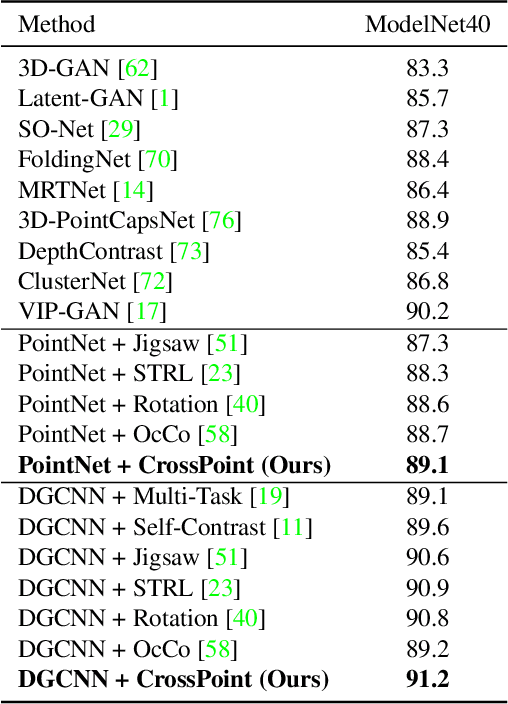
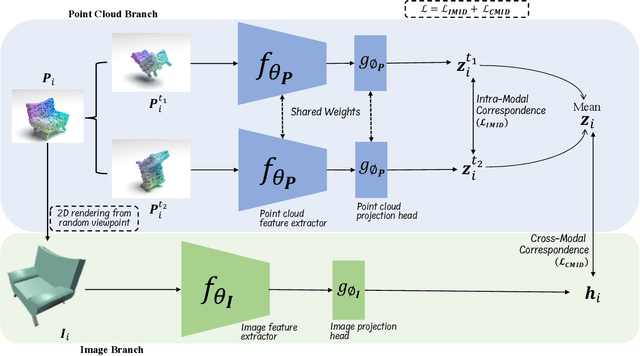
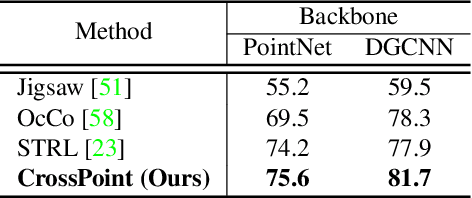
Manual annotation of large-scale point cloud dataset for varying tasks such as 3D object classification, segmentation and detection is often laborious owing to the irregular structure of point clouds. Self-supervised learning, which operates without any human labeling, is a promising approach to address this issue. We observe in the real world that humans are capable of mapping the visual concepts learnt from 2D images to understand the 3D world. Encouraged by this insight, we propose CrossPoint, a simple cross-modal contrastive learning approach to learn transferable 3D point cloud representations. It enables a 3D-2D correspondence of objects by maximizing agreement between point clouds and the corresponding rendered 2D image in the invariant space, while encouraging invariance to transformations in the point cloud modality. Our joint training objective combines the feature correspondences within and across modalities, thus ensembles a rich learning signal from both 3D point cloud and 2D image modalities in a self-supervised fashion. Experimental results show that our approach outperforms the previous unsupervised learning methods on a diverse range of downstream tasks including 3D object classification and segmentation. Further, the ablation studies validate the potency of our approach for a better point cloud understanding. Code and pretrained models are available at http://github.com/MohamedAfham/CrossPoint.
Towards Accurate Cross-Domain In-Bed Human Pose Estimation
Oct 07, 2021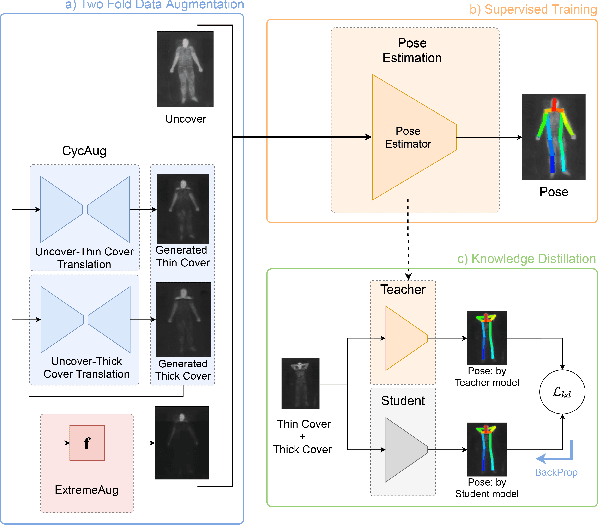
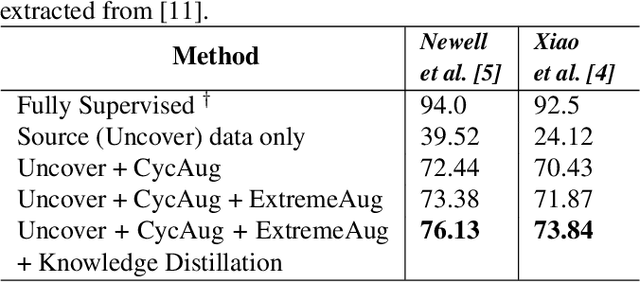
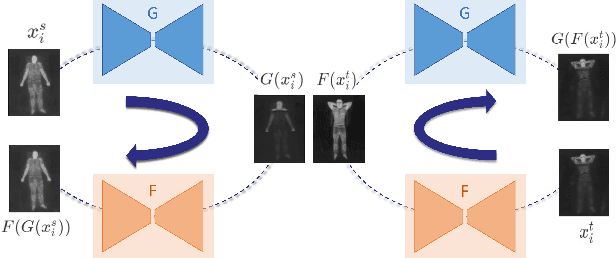
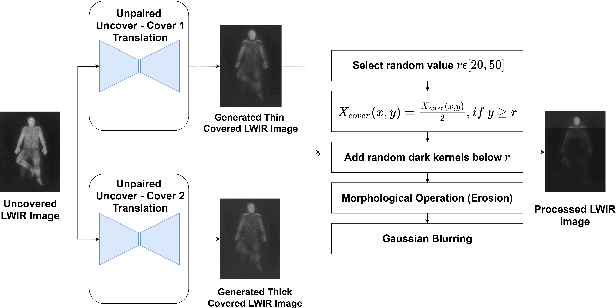
Human behavioral monitoring during sleep is essential for various medical applications. Majority of the contactless human pose estimation algorithms are based on RGB modality, causing ineffectiveness in in-bed pose estimation due to occlusions by blankets and varying illumination conditions. Long-wavelength infrared (LWIR) modality based pose estimation algorithms overcome the aforementioned challenges; however, ground truth pose generations by a human annotator under such conditions are not feasible. A feasible solution to address this issue is to transfer the knowledge learned from images with pose labels and no occlusions, and adapt it towards real world conditions (occlusions due to blankets). In this paper, we propose a novel learning strategy comprises of two-fold data augmentation to reduce the cross-domain discrepancy and knowledge distillation to learn the distribution of unlabeled images in real world conditions. Our experiments and analysis show the effectiveness of our approach over multiple standard human pose estimation baselines.
Rich Semantics Improve Few-shot Learning
Apr 26, 2021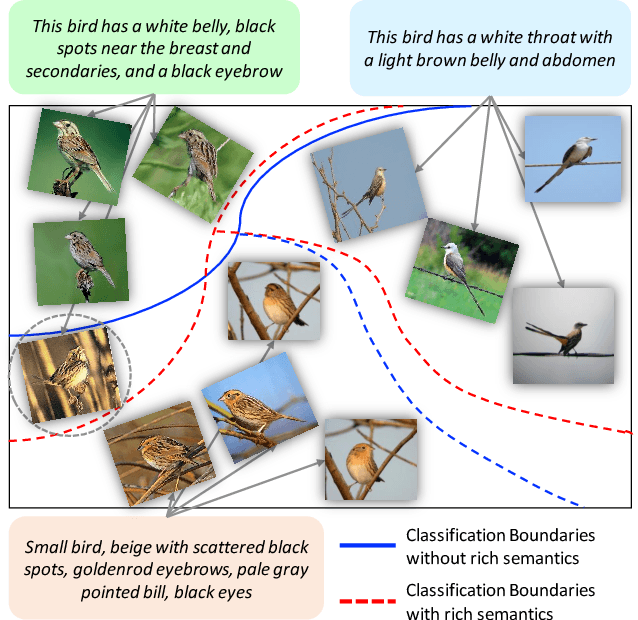
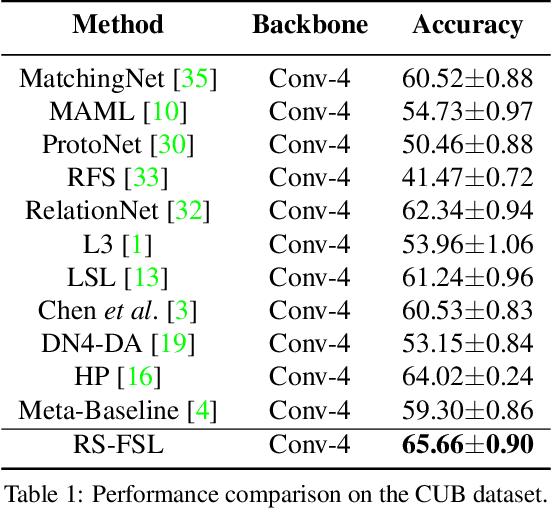
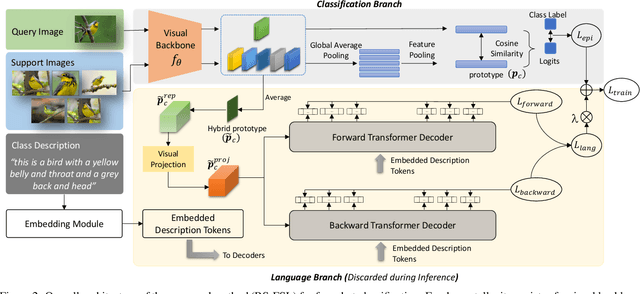
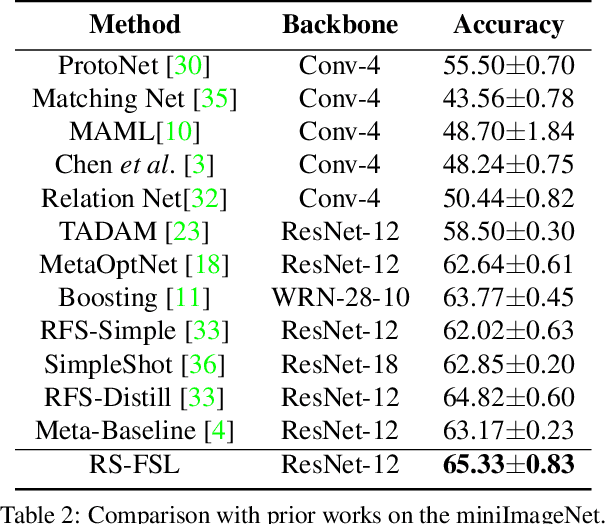
Human learning benefits from multi-modal inputs that often appear as rich semantics (e.g., description of an object's attributes while learning about it). This enables us to learn generalizable concepts from very limited visual examples. However, current few-shot learning (FSL) methods use numerical class labels to denote object classes which do not provide rich semantic meanings about the learned concepts. In this work, we show that by using 'class-level' language descriptions, that can be acquired with minimal annotation cost, we can improve the FSL performance. Given a support set and queries, our main idea is to create a bottleneck visual feature (hybrid prototype) which is then used to generate language descriptions of the classes as an auxiliary task during training. We develop a Transformer based forward and backward encoding mechanism to relate visual and semantic tokens that can encode intricate relationships between the two modalities. Forcing the prototypes to retain semantic information about class description acts as a regularizer on the visual features, improving their generalization to novel classes at inference. Furthermore, this strategy imposes a human prior on the learned representations, ensuring that the model is faithfully relating visual and semantic concepts, thereby improving model interpretability. Our experiments on four datasets and ablation studies show the benefit of effectively modeling rich semantics for FSL.