 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does Gradient Descent Learn Features -- A Local Analysis for Regularized Two-Layer Neural Networks
Jun 03, 2024
The ability of learning useful features is one of the major advantages of neural networks. Although recent works show that neural network can operate in a neural tangent kernel (NTK) regime that does not allow feature learning, many works also demonstrate the potential for neural networks to go beyond NTK regime and perform feature learning. Recently, a line of work highlighted the feature learning capabilities of the early stages of gradient-based training. In this paper we consider another mechanism for feature learning via gradient descent through a local convergence analysis. We show that once the loss is below a certain threshold, gradient descent with a carefully regularized objective will capture ground-truth directions. Our results demonstrate that feature learning not only happens at the initial gradient steps, but can also occur towards the end of training.
Deployment Prior Injection for Run-time Calibratable Object Detection
Feb 27, 2024



With a strong alignment between the training and test distributions, object relation as a context prior facilitates object detection. Yet, it turns into a harmful but inevitable training set bias upon test distributions that shift differently across space and time. Nevertheless, the existing detectors cannot incorporate deployment context prior during the test phase without parameter update. Such kind of capability requires the model to explicitly learn disentangled representations with respect to context prior. To achieve this, we introduce an additional graph input to the detector, where the graph represents the deployment context prior, and its edge values represent object relations. Then, the detector behavior is trained to bound to the graph with a modified training objective. As a result, during the test phase, any suitable deployment context prior can be injected into the detector via graph edits, hence calibrating, or "re-biasing" the detector towards the given prior at run-time without parameter update. Even if the deployment prior is unknown, the detector can self-calibrate using deployment prior approximated using its own predictions. Comprehensive experimental results on the COCO dataset, as well as cross-dataset testing on the Objects365 dataset, demonstrate the effectiveness of the run-time calibratable detector.
MixedNUTS: Training-Free Accuracy-Robustness Balance via Nonlinearly Mixed Classifiers
Feb 03, 2024



Adversarial robustness often comes at the cost of degraded accuracy, impeding the real-life application of robust classification models. Training-based solutions for better trade-offs are limited by incompatibilities with already-trained high-performance large models, necessitating the exploration of training-free ensemble approaches. Observing that robust models are more confident in correct predictions than in incorrect ones on clean and adversarial data alike, we speculate amplifying this "benign confidence property" can reconcile accuracy and robustness in an ensemble setting. To achieve so, we propose "MixedNUTS", a training-free method where the output logits of a robust classifier and a standard non-robust classifier are processed by nonlinear transformations with only three parameters, which are optimized through an efficient algorithm. MixedNUTS then converts the transformed logits into probabilities and mixes them as the overall output. On CIFAR-10, CIFAR-100, and ImageNet datasets, experimental results with custom strong adaptive attacks demonstrate MixedNUTS's vastly improved accuracy and near-SOTA robustness -- it boosts CIFAR-100 clean accuracy by 7.86 points, sacrificing merely 0.87 points in robust accuracy.
Securing Deep Generative Models with Universal Adversarial Signature
May 25, 2023Recent advances in deep generative models have led to the development of methods capable of synthesizing high-quality, realistic images. These models pose threats to society due to their potential misuse. Prior research attempted to mitigate these threats by detecting generated images, but the varying traces left by different generative models make it challenging to create a universal detector capable of generalizing to new, unseen generative models. In this paper, we propose to inject a universal adversarial signature into an arbitrary pre-trained generative model, in order to make its generated contents more detectable and traceable. First, the imperceptible optimal signature for each image can be found by a signature injector through adversarial training. Subsequently, the signature can be incorporated into an arbitrary generator by fine-tuning it with the images processed by the signature injector. In this way, the detector corresponding to the signature can be reused for any fine-tuned generator for tracking the generator identity. The proposed method is validated on the FFHQ and ImageNet datasets with various state-of-the-art generative models, consistently showing a promising detection rate. Code will be made publicly available at \url{https://github.com/zengxianyu/genwm}.
T1: Scaling Diffusion Probabilistic Fields to High-Resolution on Unified Visual Modalities
May 24, 2023Diffusion Probabilistic Field (DPF) models the distribution of continuous functions defined over metric spaces. While DPF shows great potential for unifying data generation of various modalities including images, videos, and 3D geometry, it does not scale to a higher data resolution. This can be attributed to the ``scaling property'', where it is difficult for the model to capture local structures through uniform sampling. To this end, we propose a new model comprising of a view-wise sampling algorithm to focus on local structure learning, and incorporating additional guidance, e.g., text description, to complement the global geometry. The model can be scaled to generate high-resolution data while unifying multiple modalities. Experimental results on data generation in various modalities demonstrate the effectiveness of our model, as well as its potential as a foundation framework for scalable modality-unified visual content generation.
Depth Separation with Multilayer Mean-Field Networks
Apr 03, 2023

Depth separation -- why a deeper network is more powerful than a shallower one -- has been a major problem in deep learning theory. Previous results often focus on representation power. For example, arXiv:1904.06984 constructed a function that is easy to approximate using a 3-layer network but not approximable by any 2-layer network. In this paper, we show that this separation is in fact algorithmic: one can learn the function constructed by arXiv:1904.06984 using an overparameterized network with polynomially many neurons efficiently. Our result relies on a new way of extending the mean-field limit to multilayer networks, and a decomposition of loss that factors out the error introduced by the discretization of infinite-width mean-field networks.
A Policy Gradient Framework for Stochastic Optimal Control Problems with Global Convergence Guarantee
Feb 11, 2023In this work, we consider the stochastic optimal control problem in continuous time and a policy gradient method to solve it. In particular, we study the gradient flow for the control, viewed as a continuous time limit of the policy gradient. We prove the global convergence of the gradient flow and establish a convergence rate under some regularity assumptions. The main novelty in the analysis is the notion of local optimal control function, which is introduced to compare the local optimality of the iterate.
Implicit Regularization Leads to Benign Overfitting for Sparse Linear Regression
Feb 01, 2023In deep learning, often the training process finds an interpolator (a solution with 0 training loss), but the test loss is still low. This phenomenon, known as benign overfitting, is a major mystery that received a lot of recent attention. One common mechanism for benign overfitting is implicit regularization, where the training process leads to additional properties for the interpolator, often characterized by minimizing certain norms. However, even for a simple sparse linear regression problem $y = \beta^{*\top} x +\xi$ with sparse $\beta^*$, neither minimum $\ell_1$ or $\ell_2$ norm interpolator gives the optimal test loss. In this work, we give a different parametrization of the model which leads to a new implicit regularization effect that combines the benefit of $\ell_1$ and $\ell_2$ interpolators. We show that training our new model via gradient descent leads to an interpolator with near-optimal test loss. Our result is based on careful analysis of the training dynamics and provides another example of implicit regularization effect that goes beyond norm minimization.
A Neural Network Warm-Start Approach for the Inverse Acoustic Obstacle Scattering Problem
Dec 16, 2022We consider the inverse acoustic obstacle problem for sound-soft star-shaped obstacles in two dimensions wherein the boundary of the obstacle is determined from measurements of the scattered field at a collection of receivers outside the object. One of the standard approaches for solving this problem is to reformulate it as an optimization problem: finding the boundary of the domain that minimizes the $L^2$ distance between computed values of the scattered field and the given measurement data. The optimization problem is computationally challenging since the local set of convexity shrinks with increasing frequency and results in an increasing number of local minima in the vicinity of the true solution. In many practical experimental settings, low frequency measurements are unavailable due to limitations of the experimental setup or the sensors used for measurement. Thus, obtaining a good initial guess for the optimization problem plays a vital role in this environment. We present a neural network warm-start approach for solving the inverse scattering problem, where an initial guess for the optimization problem is obtained using a trained neural network. We demonstrate the effectiveness of our method with several numerical examples. For high frequency problems, this approach outperforms traditional iterative methods such as Gauss-Newton initialized without any prior (i.e., initialized using a unit circle), or initialized using the solution of a direct method such as the linear sampling method. The algorithm remains robust to noise in the scattered field measurements and also converges to the true solution for limited aperture data. However, the number of training samples required to train the neural network scales exponentially in frequency and the complexity of the obstacles considered. We conclude with a discussion of this phenomenon and potential directions for future research.
Understanding Edge-of-Stability Training Dynamics with a Minimalist Example
Oct 07, 2022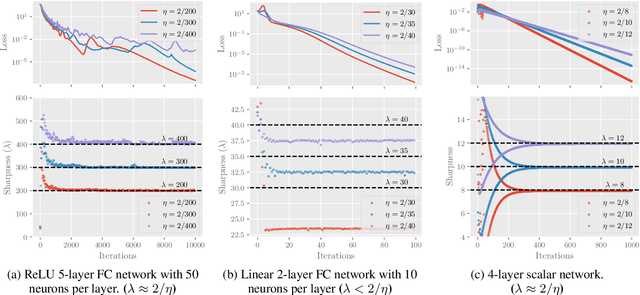
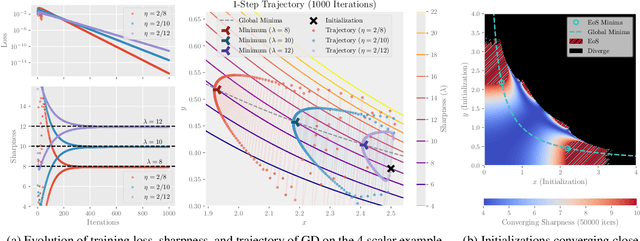
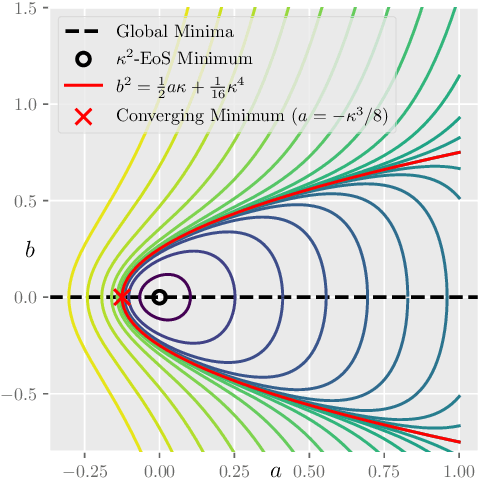
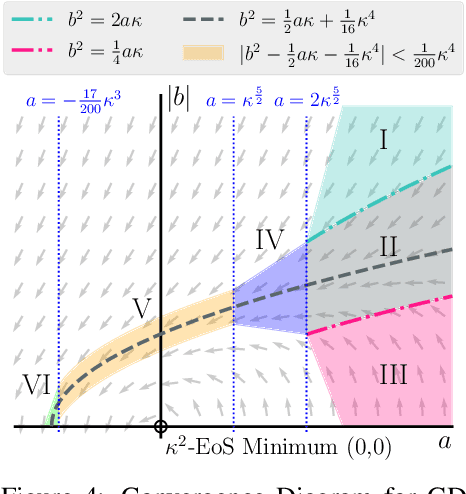
Recently, researchers observed that gradient descent for deep neural networks operates in an ``edge-of-stability'' (EoS) regime: the sharpness (maximum eigenvalue of the Hessian) is often larger than stability threshold 2/$\eta$ (where $\eta$ is the step size). Despite this, the loss oscillates and converges in the long run, and the sharpness at the end is just slightly below $2/\eta$. While many other well-understood nonconvex objectives such as matrix factorization or two-layer networks can also converge despite large sharpness, there is often a larger gap between sharpness of the endpoint and $2/\eta$. In this paper, we study EoS phenomenon by constructing a simple function that has the same behavior. We give rigorous analysis for its training dynamics in a large local region and explain why the final converging point has sharpness close to $2/\eta$. Globally we observe that the training dynamics for our example has an interesting bifurcating behavior, which was also observed in the training of neural nets.