 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainFuzz: Explainable and Constraint-Conditioned Test Generation with Probabilistic Circuits
Apr 08, 2026Understanding and explaining the structure of generated test inputs is essential for effective software testing and debugging. Existing approaches--including grammar-based fuzzers, probabilistic Context-Free Grammars (pCFGs), and Large Language Models (LLMs)--suffer from critical limitations. They frequently produce ill-formed inputs that fail to reflect realistic data distributions, struggle to capture context-sensitive probabilistic dependencies, and lack explainability. We introduce ExplainFuzz, a test generation framework that leverages Probabilistic Circuits (PCs) to learn and query structured distributions over grammar-based test inputs interpretably and controllably. Starting from a Context-Free Grammar (CFG), ExplainFuzz compiles a grammar-aware PC and trains it on existing inputs. New inputs are then generated via sampling. ExplainFuzz utilizes the conditioning capability of PCs to incorporate test-specific constraints (e.g., a query must have GROUP BY), enabling constrained probabilistic sampling to generate inputs satisfying grammar and user-provided constraints. Our results show that ExplainFuzz improves the coherence and realism of generated inputs, achieving significant perplexity reduction compared to pCFGs, grammar-unaware PCs, and LLMs. By leveraging its native conditioning capability, ExplainFuzz significantly enhances the diversity of inputs that satisfy a user-provided constraint. Compared to grammar-aware mutational fuzzing, ExplainFuzz increases bug-triggering rates from 35% to 63% in SQL and from 10% to 100% in XML. These results demonstrate the power of a learned input distribution over mutational fuzzing, which is often limited to exploring the local neighborhood of seed inputs. These capabilities highlight the potential of PCs to serve as a foundation for grammar-aware, controllable test generation that captures context-sensitive, probabilistic dependencies.
ConServe: Harvesting GPUs for Low-Latency and High-Throughput Large Language Model Serving
Oct 02, 2024



Many applications are leveraging large language models (LLMs) for complex tasks, and they generally demand low inference latency and high serving throughput for interactive online jobs such as chatbots. However, the tight latency requirement and high load variance of applications pose challenges to serving systems in achieving high GPU utilization. Due to the high costs of scheduling and preemption, today's systems generally use separate clusters to serve online and offline inference tasks, and dedicate GPUs for online inferences to avoid interference. This approach leads to underutilized GPUs because one must reserve enough GPU resources for the peak expected load, even if the average load is low. This paper proposes to harvest stranded GPU resources for offline LLM inference tasks such as document summarization and LLM benchmarking. Unlike online inferences, these tasks usually run in a batch-processing manner with loose latency requirements, making them a good fit for stranded resources that are only available shortly. To enable safe and efficient GPU harvesting without interfering with online tasks, we built ConServe, an LLM serving system that contains (1) an execution engine that preempts running offline tasks upon the arrival of online tasks, (2) an incremental checkpointing mechanism that minimizes the amount of recomputation required by preemptions, and (3) a scheduler that adaptively batches offline tasks for higher GPU utilization. Our evaluation demonstrates that ConServe achieves strong performance isolation when co-serving online and offline tasks but at a much higher GPU utilization. When colocating practical online and offline workloads on popular models such as Llama-2-7B, ConServe achieves 2.35$\times$ higher throughput than state-of-the-art online serving systems and reduces serving latency by 84$\times$ compared to existing co-serving systems.
Human-in-the-Loop Synthetic Text Data Inspection with Provenance Tracking
Apr 29, 2024



Data augmentation techniques apply transformations to existing texts to generate additional data. The transformations may produce low-quality texts, where the meaning of the text is changed and the text may even be mangled beyond human comprehension. Analyzing the synthetically generated texts and their corresponding labels is slow and demanding. To winnow out texts with incorrect labels, we develop INSPECTOR, a human-in-the-loop data inspection technique. INSPECTOR combines the strengths of provenance tracking techniques with assistive labeling. INSPECTOR allows users to group related texts by their transformation provenance, i.e., the transformations applied to the original text, or feature provenance, the linguistic features of the original text. For assistive labeling, INSPECTOR computes metrics that approximate data quality, and allows users to compare the corresponding label of each text against the predictions of a large language model. In a user study, INSPECTOR increases the number of texts with correct labels identified by 3X on a sentiment analysis task and by 4X on a hate speech detection task. The participants found grouping the synthetically generated texts by their common transformation to be the most useful technique. Surprisingly, grouping texts by common linguistic features was perceived to be unhelpful. Contrary to prior work, our study finds that no single technique obviates the need for human inspection effort. This validates the design of INSPECTOR which combines both analysis of data provenance and assistive labeling to reduce human inspection effort.
Sibylvariant Transformations for Robust Text Classification
May 10, 2022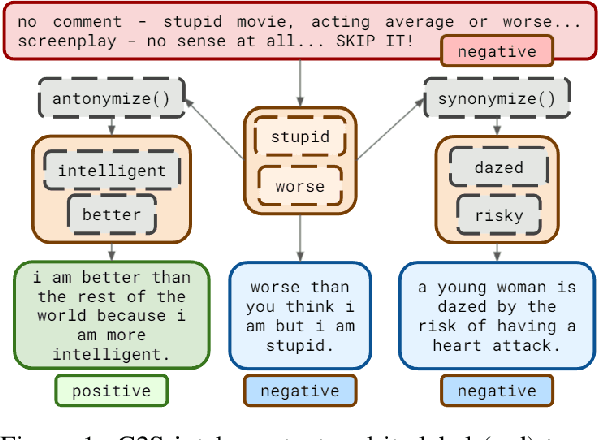
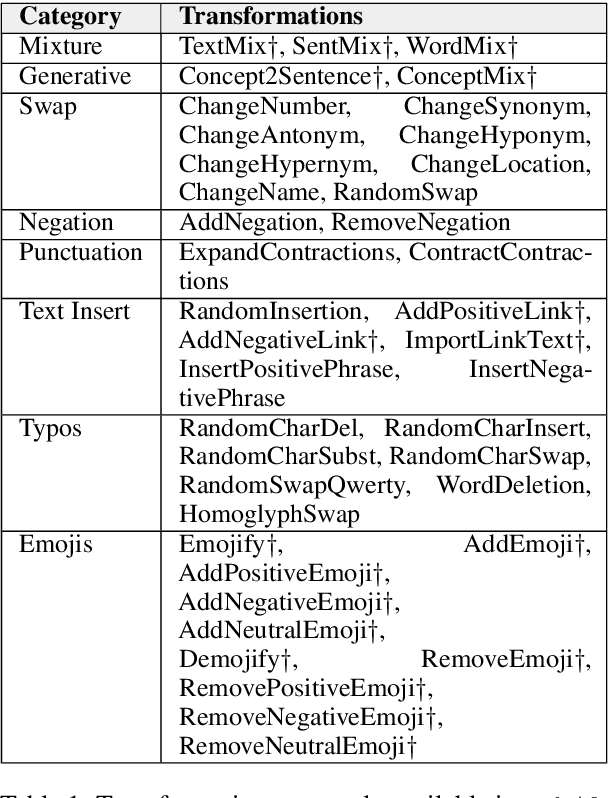

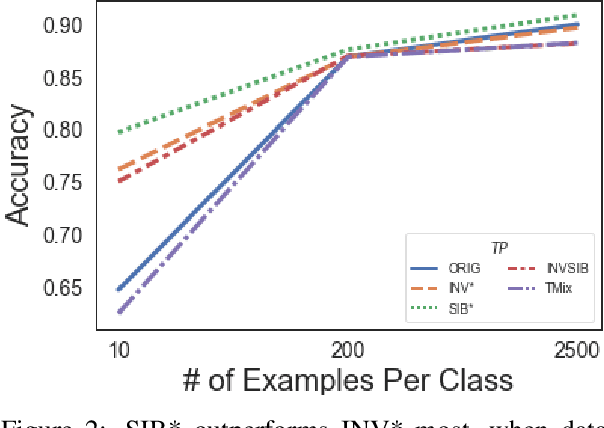
The vast majority of text transformation techniques in NLP are inherently limited in their ability to expand input space coverage due to an implicit constraint to preserve the original class label. In this work, we propose the notion of sibylvariance (SIB) to describe the broader set of transforms that relax the label-preserving constraint, knowably vary the expected class, and lead to significantly more diverse input distributions. We offer a unified framework to organize all data transformations, including two types of SIB: (1) Transmutations convert one discrete kind into another, (2) Mixture Mutations blend two or more classes together. To explore the role of sibylvariance within NLP, we implemented 41 text transformations, including several novel techniques like Concept2Sentence and SentMix. Sibylvariance also enables a unique form of adaptive training that generates new input mixtures for the most confused class pairs, challenging the learner to differentiate with greater nuance. Our experiments on six benchmark datasets strongly support the efficacy of sibylvariance for generalization performance, defect detection, and adversarial robustness.
Dorylus: Affordable, Scalable, and Accurate GNN Training with Distributed CPU Servers and Serverless Threads
May 25, 2021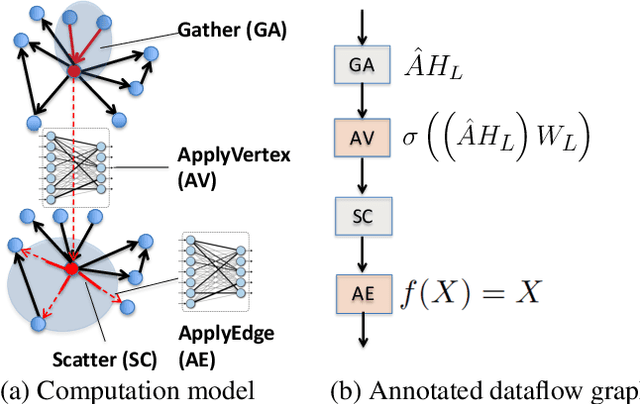

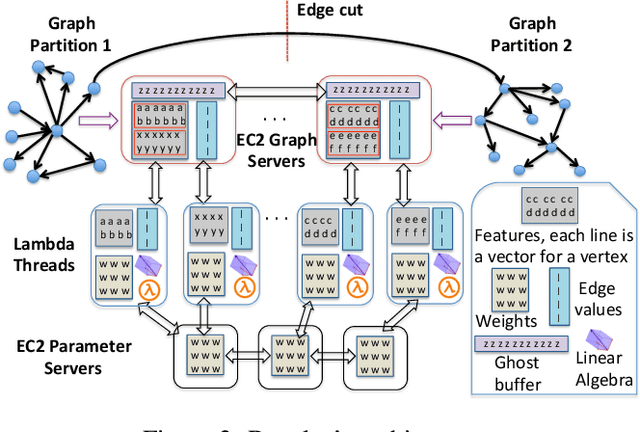

A graph neural network (GNN) enables deep learning on structured graph data. There are two major GNN training obstacles: 1) it relies on high-end servers with many GPUs which are expensive to purchase and maintain, and 2) limited memory on GPUs cannot scale to today's billion-edge graphs. This paper presents Dorylus: a distributed system for training GNNs. Uniquely, Dorylus can take advantage of serverless computing to increase scalability at a low cost. The key insight guiding our design is computation separation. Computation separation makes it possible to construct a deep, bounded-asynchronous pipeline where graph and tensor parallel tasks can fully overlap, effectively hiding the network latency incurred by Lambdas. With the help of thousands of Lambda threads, Dorylus scales GNN training to billion-edge graphs. Currently, for large graphs, CPU servers offer the best performance-per-dollar over GPU servers. Just using Lambdas on top of CPU servers offers up to 2.75x more performance-per-dollar than training only with CPU servers. Concretely, Dorylus is 1.22x faster and 4.83x cheaper than GPU servers for massive sparse graphs. Dorylus is up to 3.8x faster and 10.7x cheaper compared to existing sampling-based systems.
An Analysis of Adversarial Attacks and Defenses on Autonomous Driving Models
Feb 06, 2020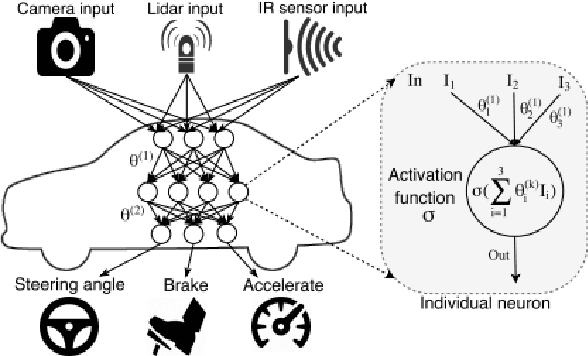
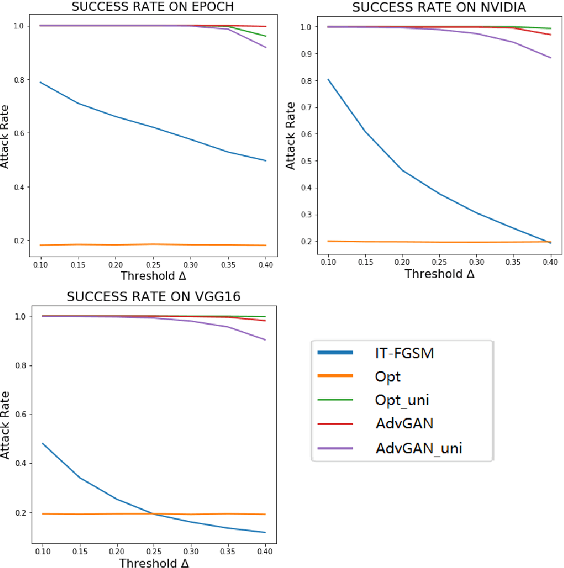

Nowadays, autonomous driving has attracted much attention from both industry and academia. Convolutional neural network (CNN) is a key component in autonomous driving, which is also increasingly adopted in pervasive computing such as smartphones, wearable devices, and IoT networks. Prior work shows CNN-based classification models are vulnerable to adversarial attacks. However, it is uncertain to what extent regression models such as driving models are vulnerable to adversarial attacks, the effectiveness of existing defense techniques, and the defense implications for system and middleware builders. This paper presents an in-depth analysis of five adversarial attacks and four defense methods on three driving models. Experiments show that, similar to classification models, these models are still highly vulnerable to adversarial attacks. This poses a big security threat to autonomous driving and thus should be taken into account in practice. While these defense methods can effectively defend against different attacks, none of them are able to provide adequate protection against all five attacks. We derive several implications for system and middleware builders: (1) when adding a defense component against adversarial attacks, it is important to deploy multiple defense methods in tandem to achieve a good coverage of various attacks, (2) a blackbox attack is much less effective compared with a white-box attack, implying that it is important to keep model details (e.g., model architecture, hyperparameters) confidential via model obfuscation, and (3) driving models with a complex architecture are preferred if computing resources permit as they are more resilient to adversarial attacks than simple models.