 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Sequence-Level Training for Visual Tracking
Aug 11, 2022
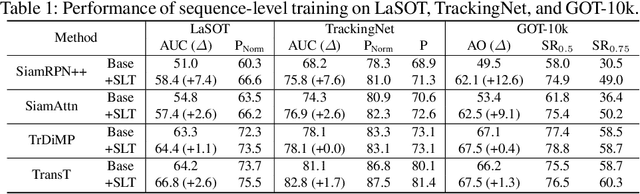
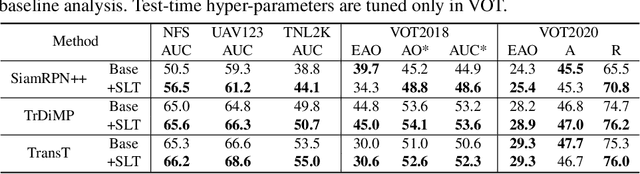

Despite the extensive adoption of machine learning on the task of visual object tracking, recent learning-based approaches have largely overlooked the fact that visual tracking is a sequence-level task in its nature; they rely heavily on frame-level training, which inevitably induces inconsistency between training and testing in terms of both data distributions and task objectives. This work introduces a sequence-level training strategy for visual tracking based on reinforcement learning and discusses how a sequence-level design of data sampling, learning objectives, and data augmentation can improve the accuracy and robustness of tracking algorithms. Our experiments on standard benchmarks including LaSOT, TrackingNet, and GOT-10k demonstrate that four representative tracking models, SiamRPN++, SiamAttn, TransT, and TrDiMP, consistently improve by incorporating the proposed methods in training without modifying architectures.
Revisiting Self-Distillation
Jun 17, 2022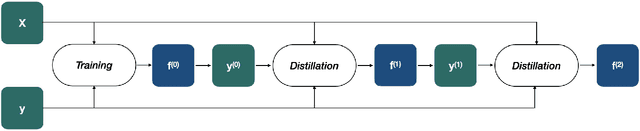
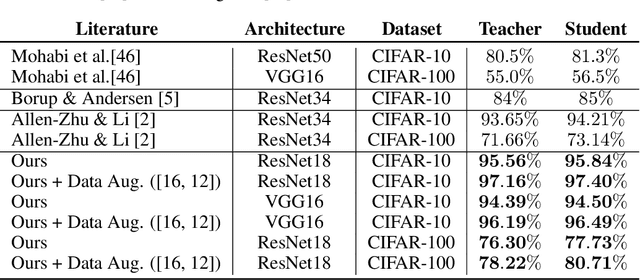
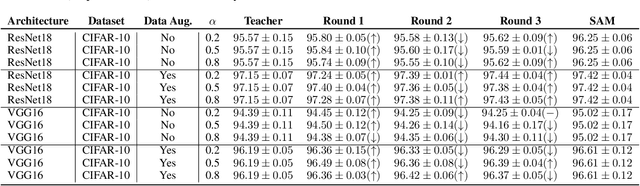
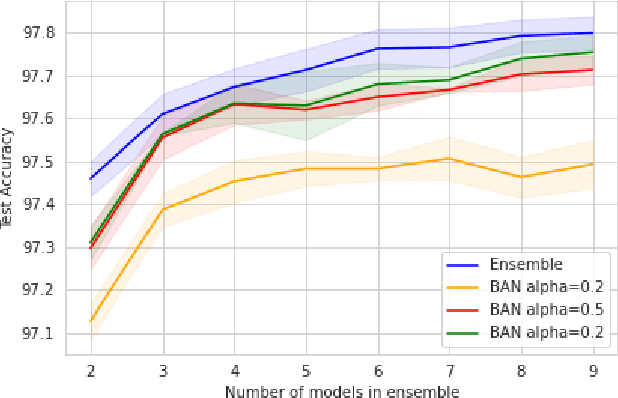
Knowledge distillation is the procedure of transferring "knowledge" from a large model (the teacher) to a more compact one (the student), often being used in the context of model compression. When both models have the same architecture, this procedure is called self-distillation. Several works have anecdotally shown that a self-distilled student can outperform the teacher on held-out data. In this work, we systematically study self-distillation in a number of settings. We first show that even with a highly accurate teacher, self-distillation allows a student to surpass the teacher in all cases. Secondly, we revisit existing theoretical explanations of (self) distillation and identify contradicting examples, revealing possible drawbacks of these explanations. Finally, we provide an alternative explanation for the dynamics of self-distillation through the lens of loss landscape geometry. We conduct extensive experiments to show that self-distillation leads to flatter minima, thereby resulting in better generalization.
Self-Supervised Learning of Image Scale and Orientation
Jun 15, 2022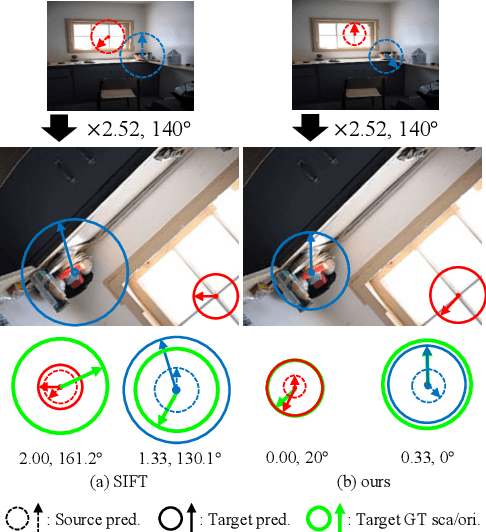
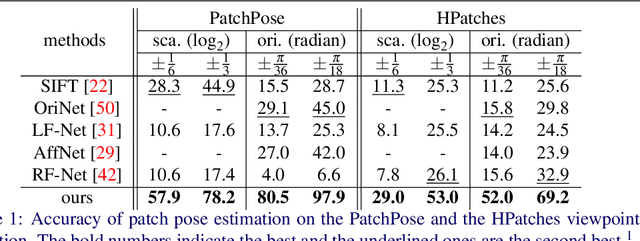
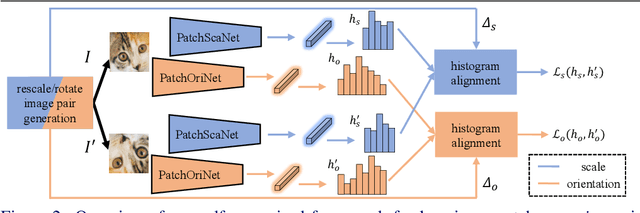
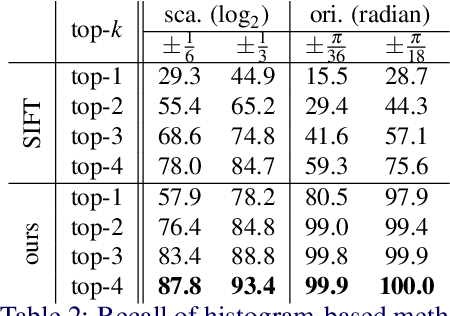
We study the problem of learning to assign a characteristic pose, i.e., scale and orientation, for an image region of interest. Despite its apparent simplicity, the problem is non-trivial; it is hard to obtain a large-scale set of image regions with explicit pose annotations that a model directly learns from. To tackle the issue, we propose a self-supervised learning framework with a histogram alignment technique. It generates pairs of image patches by random rescaling/rotating and then train an estimator to predict their scale/orientation values so that their relative difference is consistent with the rescaling/rotating used. The estimator learns to predict a non-parametric histogram distribution of scale/orientation without any supervision. Experiments show that it significantly outperforms previous methods in scale/orientation estimation and also improves image matching and 6 DoF camera pose estimation by incorporating our patch poses into a matching process.
Peripheral Vision Transformer
Jun 14, 2022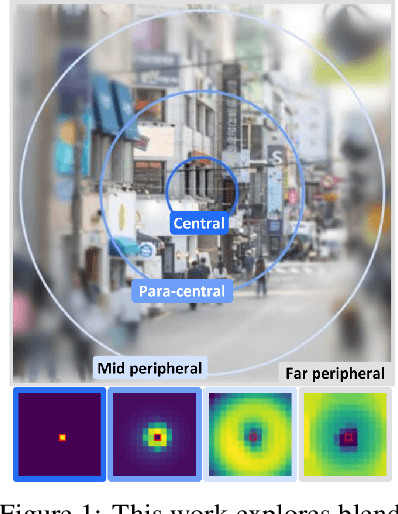
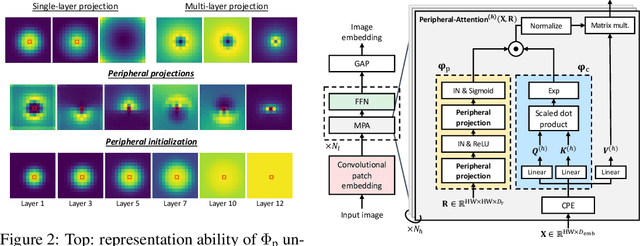
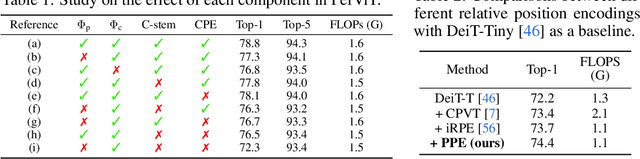

Human vision possesses a special type of visual processing systems called peripheral vision. Partitioning the entire visual field into multiple contour regions based on the distance to the center of our gaze, the peripheral vision provides us the ability to perceive various visual features at different regions. In this work, we take a biologically inspired approach and explore to model peripheral vision in deep neural networks for visual recognition. We propose to incorporate peripheral position encoding to the multi-head self-attention layers to let the network learn to partition the visual field into diverse peripheral regions given training data. We evaluate the proposed network, dubbed PerViT, on the large-scale ImageNet dataset and systematically investigate the inner workings of the model for machine perception, showing that the network learns to perceive visual data similarly to the way that human vision does. The state-of-the-art performance in image classification task across various model sizes demonstrates the efficacy of the proposed method.
Draft-and-Revise: Effective Image Generation with Contextual RQ-Transformer
Jun 09, 2022
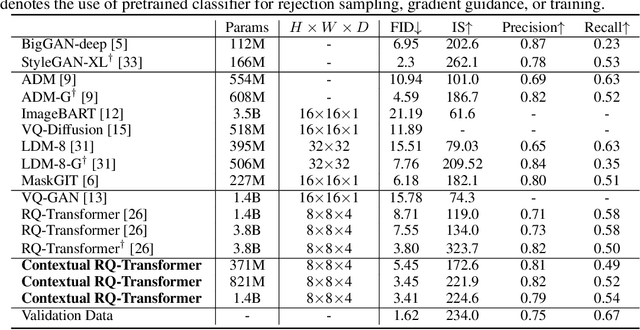
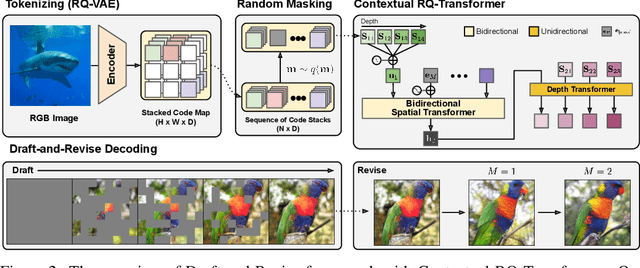
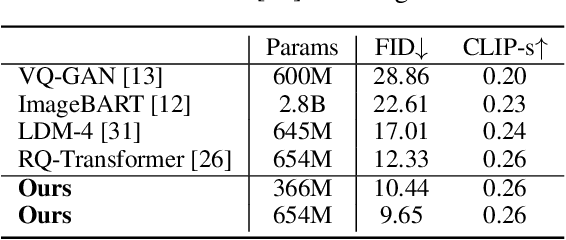
Although autoregressive models have achieved promising results on image generation, their unidirectional generation process prevents the resultant images from fully reflecting global contexts. To address the issue, we propose an effective image generation framework of Draft-and-Revise with Contextual RQ-transformer to consider global contexts during the generation process. As a generalized VQ-VAE, RQ-VAE first represents a high-resolution image as a sequence of discrete code stacks. After code stacks in the sequence are randomly masked, Contextual RQ-Transformer is trained to infill the masked code stacks based on the unmasked contexts of the image. Then, Contextual RQ-Transformer uses our two-phase decoding, Draft-and-Revise, and generates an image, while exploiting the global contexts of the image during the generation process. Specifically. in the draft phase, our model first focuses on generating diverse images despite rather low quality. Then, in the revise phase, the model iteratively improves the quality of images, while preserving the global contexts of generated images. In experiments, our method achieves state-of-the-art results on conditional image generation. We also validate that the Draft-and-Revise decoding can achieve high performance by effectively controlling the quality-diversity trade-off in image generation.
Future Transformer for Long-term Action Anticipation
May 27, 2022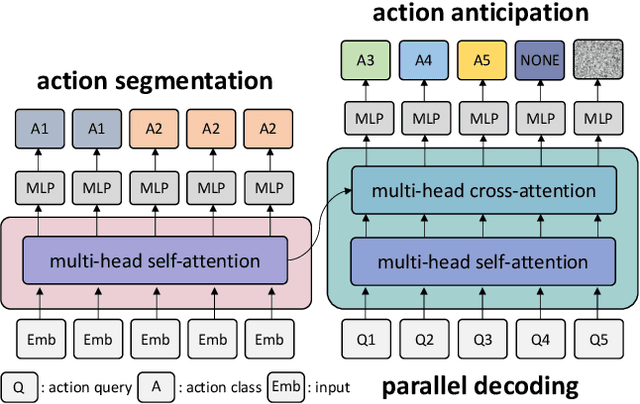
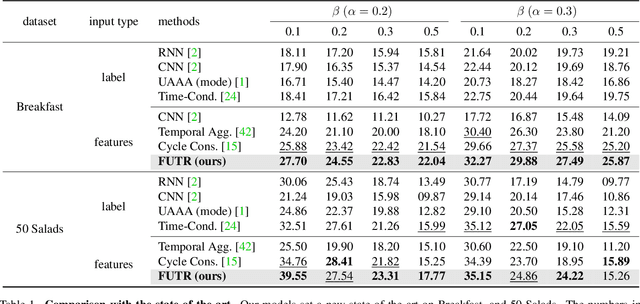
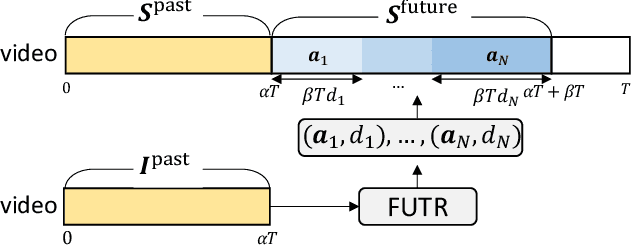
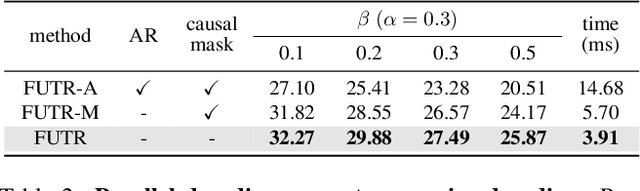
The task of predicting future actions from a video is crucial for a real-world agent interacting with others. When anticipating actions in the distant future, we humans typically consider long-term relations over the whole sequence of actions, i.e., not only observed actions in the past but also potential actions in the future. In a similar spirit, we propose an end-to-end attention model for action anticipation, dubbed Future Transformer (FUTR), that leverages global attention over all input frames and output tokens to predict a minutes-long sequence of future actions. Unlike the previous autoregressive models, the proposed method learns to predict the whole sequence of future actions in parallel decoding, enabling more accurate and fast inference for long-term anticipation. We evaluate our method on two standard benchmarks for long-term action anticipation, Breakfast and 50 Salads, achieving state-of-the-art results.
Learning to Assemble Geometric Shapes
May 24, 2022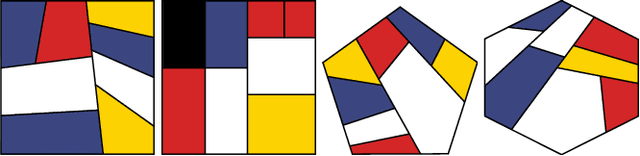
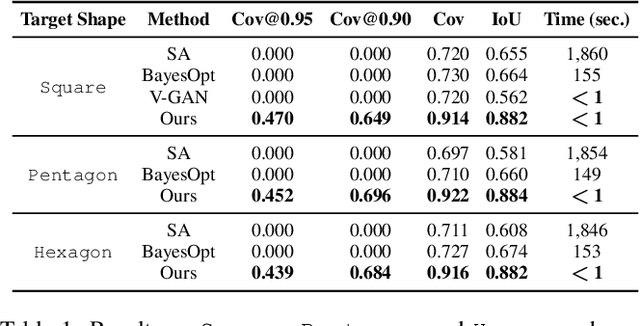
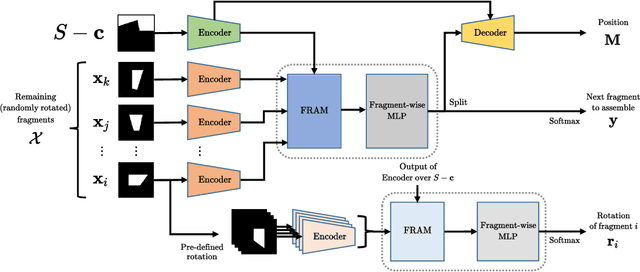
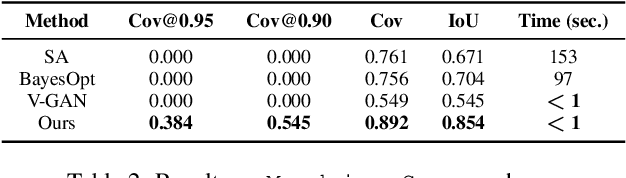
Assembling parts into an object is a combinatorial problem that arises in a variety of contexts in the real world and involves numerous applications in science and engineering. Previous related work tackles limited cases with identical unit parts or jigsaw-style parts of textured shapes, which greatly mitigate combinatorial challenges of the problem. In this work, we introduce the more challenging problem of shape assembly, which involves textureless fragments of arbitrary shapes with indistinctive junctions, and then propose a learning-based approach to solving it. We demonstrate the effectiveness on shape assembly tasks with various scenarios, including the ones with abnormal fragments (e.g., missing and distorted), the different number of fragments, and different rotation discretization.
TransforMatcher: Match-to-Match Attention for Semantic Correspondence
May 23, 2022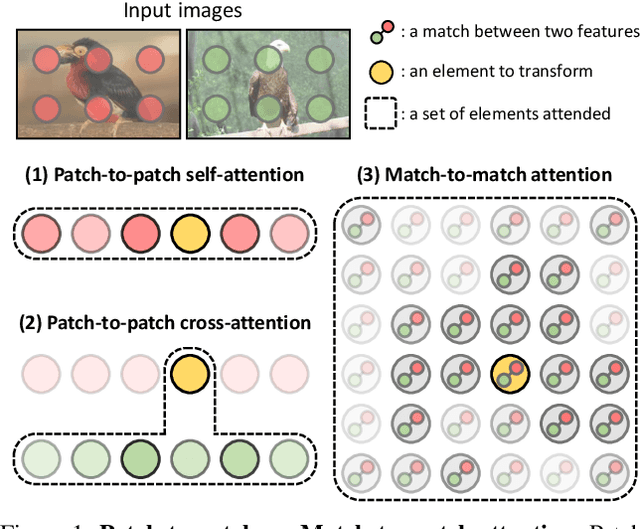
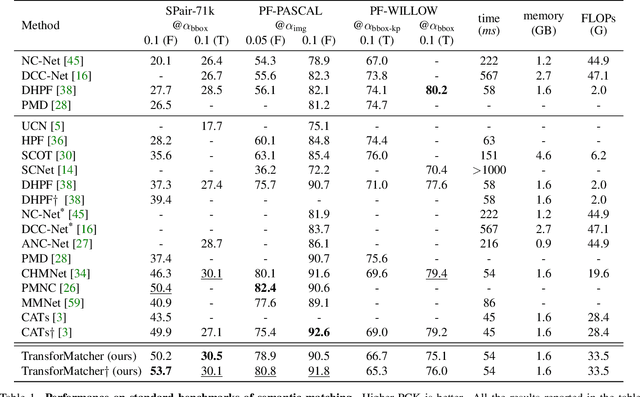
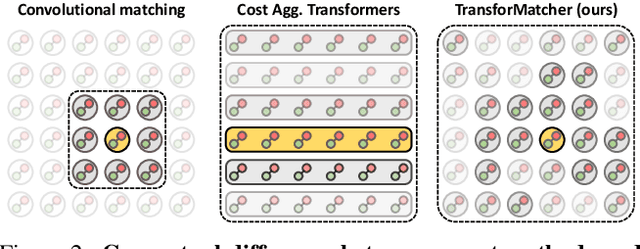
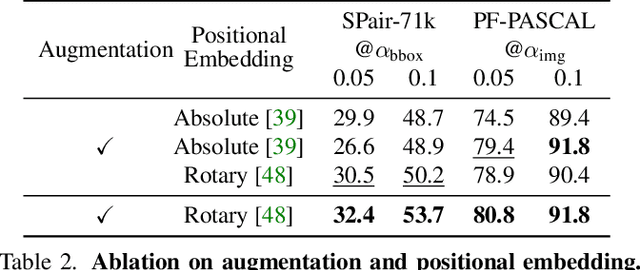
Establishing correspondences between images remains a challenging task, especially under large appearance changes due to different viewpoints or intra-class variations. In this work, we introduce a strong semantic image matching learner, dubbed TransforMatcher, which builds on the success of transformer networks in vision domains. Unlike existing convolution- or attention-based schemes for correspondence, TransforMatcher performs global match-to-match attention for precise match localization and dynamic refinement. To handle a large number of matches in a dense correlation map, we develop a light-weight attention architecture to consider the global match-to-match interactions. We also propose to utilize a multi-channel correlation map for refinement, treating the multi-level scores as features instead of a single score to fully exploit the richer layer-wise semantics. In experiments, TransforMatcher sets a new state of the art on SPair-71k while performing on par with existing SOTA methods on the PF-PASCAL dataset.
Smooth-Reduce: Leveraging Patches for Improved Certified Robustness
May 12, 2022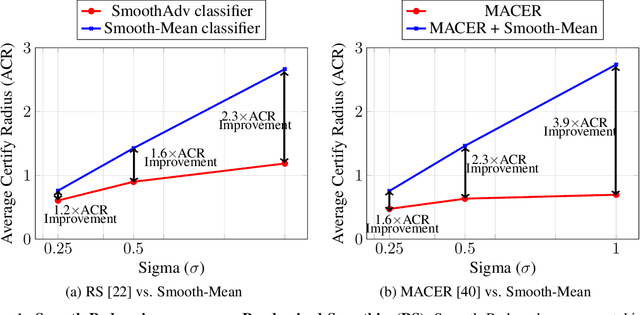
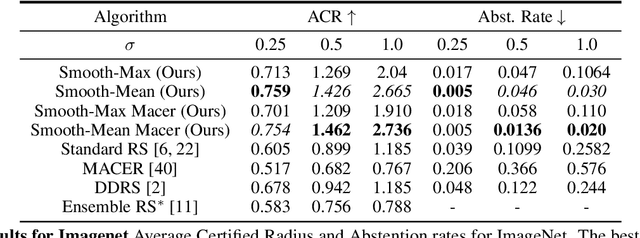
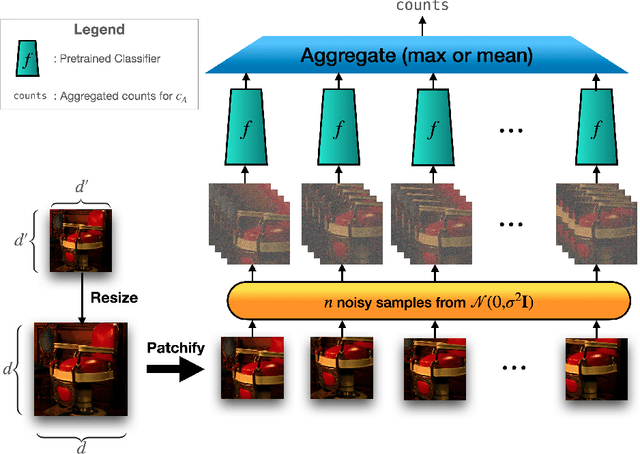
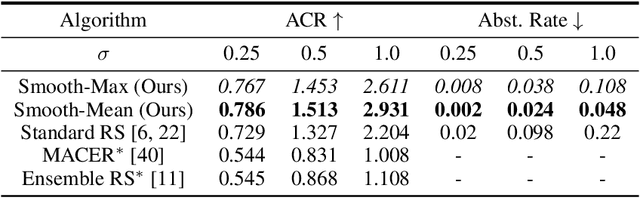
Randomized smoothing (RS) has been shown to be a fast, scalable technique for certifying the robustness of deep neural network classifiers. However, methods based on RS require augmenting data with large amounts of noise, which leads to significant drops in accuracy. We propose a training-free, modified smoothing approach, Smooth-Reduce, that leverages patching and aggregation to provide improved classifier certificates. Our algorithm classifies overlapping patches extracted from an input image, and aggregates the predicted logits to certify a larger radius around the input. We study two aggregation schemes -- max and mean -- and show that both approaches provide better certificates in terms of certified accuracy, average certified radii and abstention rates as compared to concurrent approaches. We also provide theoretical guarantees for such certificates, and empirically show significant improvements over other randomized smoothing methods that require expensive retraining. Further, we extend our approach to videos and provide meaningful certificates for video classifiers. A project page can be found at https://nyu-dice-lab.github.io/SmoothReduce/
Self-Taught Metric Learning without Labels
May 04, 2022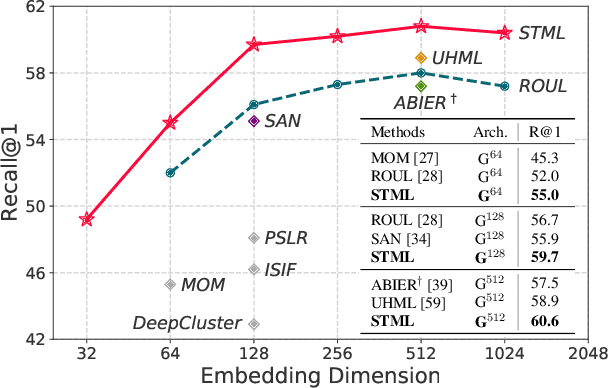
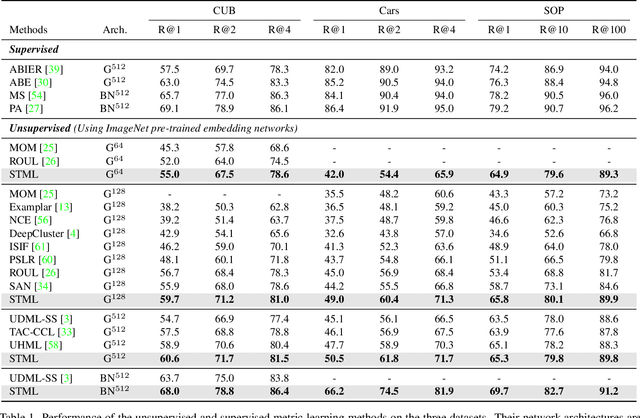
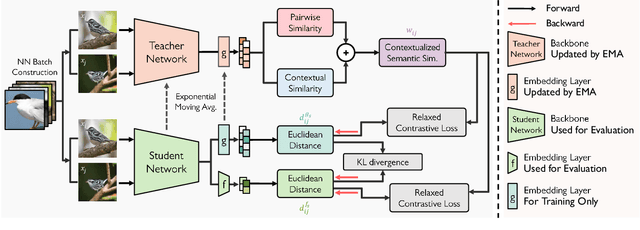
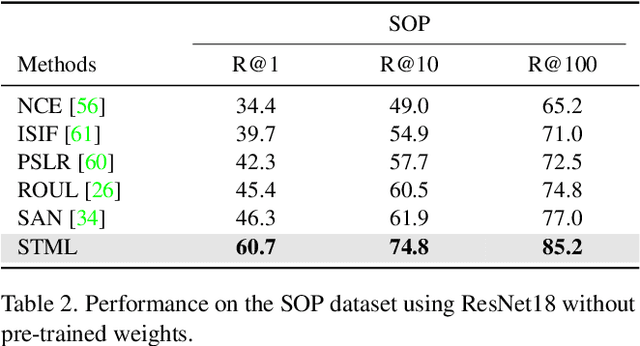
We present a novel self-taught framework for unsupervised metric learning, which alternates between predicting class-equivalence relations between data through a moving average of an embedding model and learning the model with the predicted relations as pseudo labels. At the heart of our framework lies an algorithm that investigates contexts of data on the embedding space to predict their class-equivalence relations as pseudo labels. The algorithm enables efficient end-to-end training since it demands no off-the-shelf module for pseudo labeling. Also, the class-equivalence relations provide rich supervisory signals for learning an embedding space. On standard benchmarks for metric learning, it clearly outperforms existing unsupervised learning methods and sometimes even beats supervised learning models using the same backbone network. It is also applied to semi-supervised metric learning as a way of exploiting additional unlabeled data, and achieves the state of the art by boosting performance of supervised learning substantially.