 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Video Quality Scoring and Justification via Large Multimodal Models
Jun 26, 2025Classical video quality assessment (VQA) methods generate a numerical score to judge a video's perceived visual fidelity and clarity. Yet, a score fails to describe the video's complex quality dimensions, restricting its applicability. Benefiting from the linguistic output, adapting video large multimodal models (LMMs) to VQA via instruction tuning has the potential to address this issue. The core of the approach lies in the video quality-centric instruction data. Previous explorations mainly focus on the image domain, and their data generation processes heavily rely on human quality annotations and proprietary systems, limiting data scalability and effectiveness. To address these challenges, we propose the Score-based Instruction Generation (SIG) pipeline. Specifically, SIG first scores multiple quality dimensions of an unlabeled video and maps scores to text-defined levels. It then explicitly incorporates a hierarchical Chain-of-Thought (CoT) to model the correlation between specific dimensions and overall quality, mimicking the human visual system's reasoning process. The automated pipeline eliminates the reliance on expert-written quality descriptions and proprietary systems, ensuring data scalability and generation efficiency. To this end, the resulting Score2Instruct (S2I) dataset contains over 320K diverse instruction-response pairs, laying the basis for instruction tuning. Moreover, to advance video LMMs' quality scoring and justification abilities simultaneously, we devise a progressive tuning strategy to fully unleash the power of S2I. Built upon SIG, we further curate a benchmark termed S2I-Bench with 400 open-ended questions to better evaluate the quality justification capacity of video LMMs. Experimental results on the S2I-Bench and existing benchmarks indicate that our method consistently improves quality scoring and justification capabilities across multiple video LMMs.
QPT V2: Masked Image Modeling Advances Visual Scoring
Jul 23, 2024



Quality assessment and aesthetics assessment aim to evaluate the perceived quality and aesthetics of visual content. Current learning-based methods suffer greatly from the scarcity of labeled data and usually perform sub-optimally in terms of generalization. Although masked image modeling (MIM) has achieved noteworthy advancements across various high-level tasks (e.g., classification, detection etc.). In this work, we take on a novel perspective to investigate its capabilities in terms of quality- and aesthetics-awareness. To this end, we propose Quality- and aesthetics-aware pretraining (QPT V2), the first pretraining framework based on MIM that offers a unified solution to quality and aesthetics assessment. To perceive the high-level semantics and fine-grained details, pretraining data is curated. To comprehensively encompass quality- and aesthetics-related factors, degradation is introduced. To capture multi-scale quality and aesthetic information, model structure is modified. Extensive experimental results on 11 downstream benchmarks clearly show the superior performance of QPT V2 in comparison with current state-of-the-art approaches and other pretraining paradigms. Code and models will be released at \url{https://github.com/KeiChiTse/QPT-V2}.
Ada-DQA: Adaptive Diverse Quality-aware Feature Acquisition for Video Quality Assessment
Aug 01, 2023Video quality assessment (VQA) has attracted growing attention in recent years. While the great expense of annotating large-scale VQA datasets has become the main obstacle for current deep-learning methods. To surmount the constraint of insufficient training data, in this paper, we first consider the complete range of video distribution diversity (\ie content, distortion, motion) and employ diverse pretrained models (\eg architecture, pretext task, pre-training dataset) to benefit quality representation. An Adaptive Diverse Quality-aware feature Acquisition (Ada-DQA) framework is proposed to capture desired quality-related features generated by these frozen pretrained models. By leveraging the Quality-aware Acquisition Module (QAM), the framework is able to extract more essential and relevant features to represent quality. Finally, the learned quality representation is utilized as supplementary supervisory information, along with the supervision of the labeled quality score, to guide the training of a relatively lightweight VQA model in a knowledge distillation manner, which largely reduces the computational cost during inference. Experimental results on three mainstream no-reference VQA benchmarks clearly show the superior performance of Ada-DQA in comparison with current state-of-the-art approaches without using extra training data of VQA.
Distraction-Aware Feature Learning for Human Attribute Recognition via Coarse-to-Fine Attention Mechanism
Nov 26, 2019
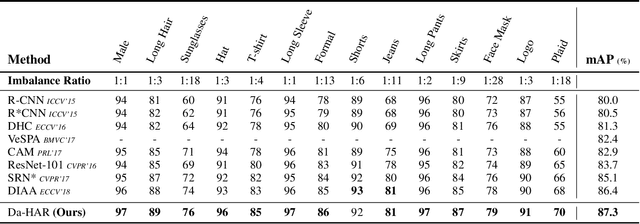

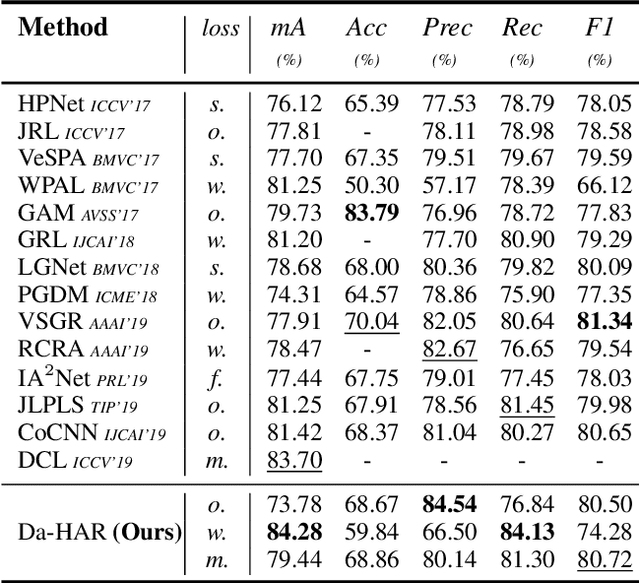
Recently, Human Attribute Recognition (HAR) has become a hot topic due to its scientific challenges and application potentials, where localizing attributes is a crucial stage but not well handled. In this paper, we propose a novel deep learning approach to HAR, namely Distraction-aware HAR (Da-HAR). It enhances deep CNN feature learning by improving attribute localization through a coarse-to-fine attention mechanism. At the coarse step, a self-mask block is built to roughly discriminate and reduce distractions, while at the fine step, a masked attention branch is applied to further eliminate irrelevant regions. Thanks to this mechanism, feature learning is more accurate, especially when heavy occlusions and complex backgrounds exist. Extensive experiments are conducted on the WIDER-Attribute and RAP databases, and state-of-the-art results are achieved, demonstrating the effectiveness of the proposed approach.