 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Word-based Language Model in Statistical Machine Translation
Feb 05, 2015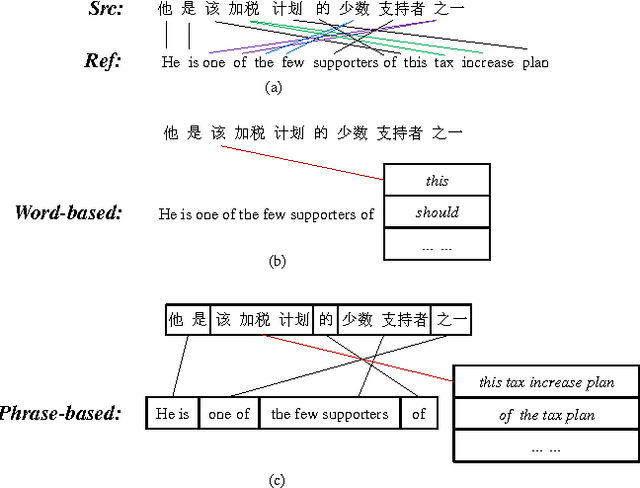


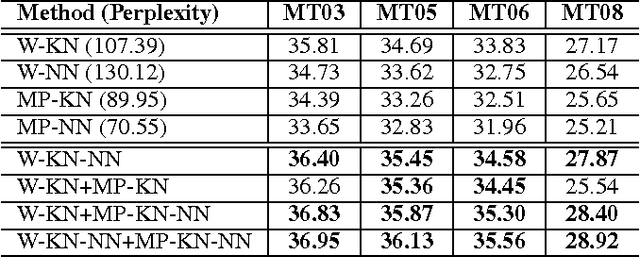
Language model is one of the most important modules in statistical machine translation and currently the word-based language model dominants this community. However, many translation models (e.g. phrase-based models) generate the target language sentences by rendering and compositing the phrases rather than the words. Thus, it is much more reasonable to model dependency between phrases, but few research work succeed in solving this problem. In this paper, we tackle this problem by designing a novel phrase-based language model which attempts to solve three key sub-problems: 1, how to define a phrase in language model; 2, how to determine the phrase boundary in the large-scale monolingual data in order to enlarge the training set; 3, how to alleviate the data sparsity problem due to the huge vocabulary size of phrases. By carefully handling these issues, the extensive experiments on Chinese-to-English translation show that our phrase-based language model can significantly improve the translation quality by up to +1.47 absolute BLEU score.
User-level sentiment analysis incorporating social networks
Sep 27, 2011
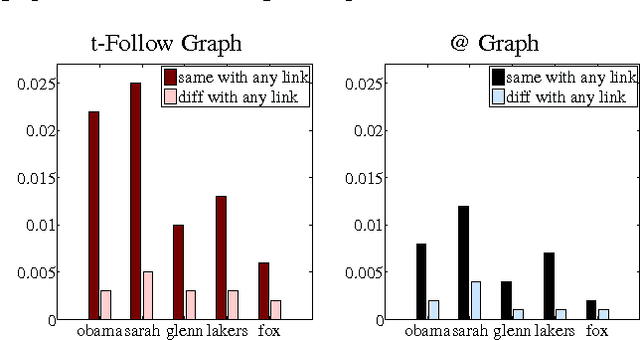
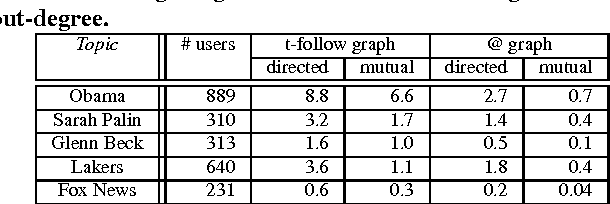
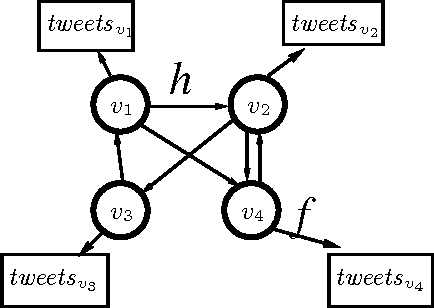
We show that information about social relationships can be used to improve user-level sentiment analysis. The main motivation behind our approach is that users that are somehow "connected" may be more likely to hold similar opinions; therefore, relationship information can complement what we can extract about a user's viewpoints from their utterances. Employing Twitter as a source for our experimental data, and working within a semi-supervised framework, we propose models that are induced either from the Twitter follower/followee network or from the network in Twitter formed by users referring to each other using "@" mentions. Our transductive learning results reveal that incorporating social-network information can indeed lead to statistically significant sentiment-classification improvements over the performance of an approach based on Support Vector Machines having access only to textual features.