 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelect, Answer and Explain: Interpretable Multi-hop Reading Comprehension over Multiple Documents
Nov 22, 2019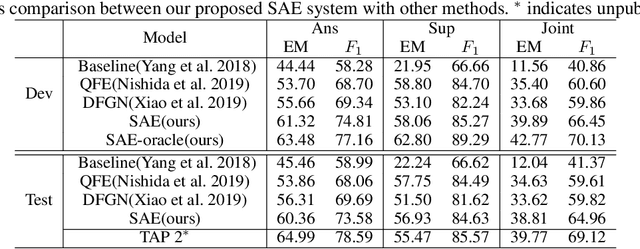
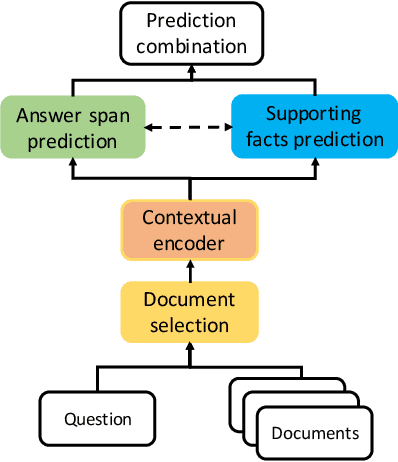
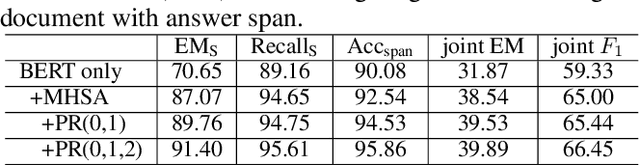
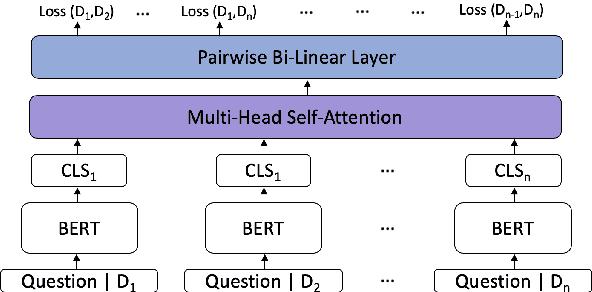
Interpretable multi-hop reading comprehension (RC) over multiple documents is a challenging problem because it demands reasoning over multiple information sources and explaining the answer prediction by providing supporting evidences. In this paper, we propose an effective and interpretable Select, Answer and Explain (SAE) system to solve the multi-document RC problem. Our system first filters out answer-unrelated documents and thus reduce the amount of distraction information. This is achieved by a document classifier trained with a novel pairwise learning-to-rank loss. The selected answer-related documents are then input to a model to jointly predict the answer and supporting sentences. The model is optimized with a multi-task learning objective on both token level for answer prediction and sentence level for supporting sentences prediction, together with an attention-based interaction between these two tasks. Evaluated on HotpotQA, a challenging multi-hop RC data set, the proposed SAE system achieves top competitive performance in distractor setting compared to other existing systems on the leaderboard.
Speaker-invariant Affective Representation Learning via Adversarial Training
Nov 04, 2019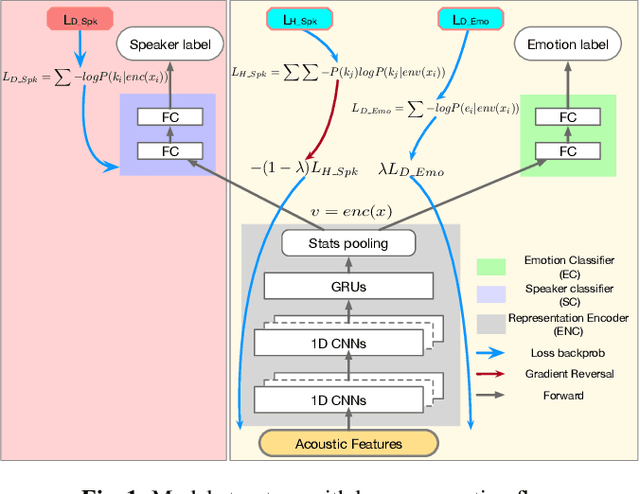
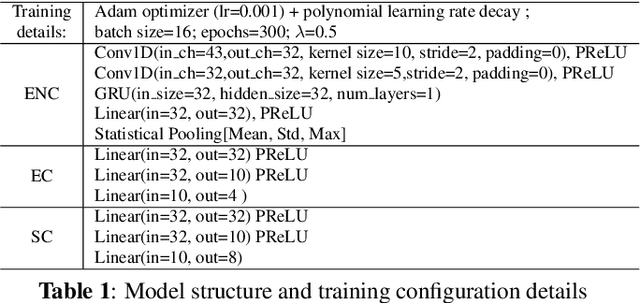
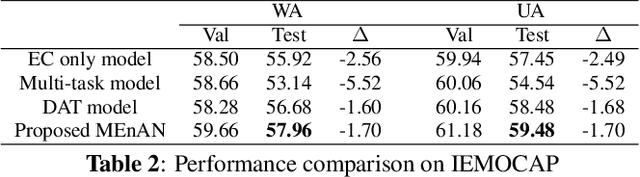
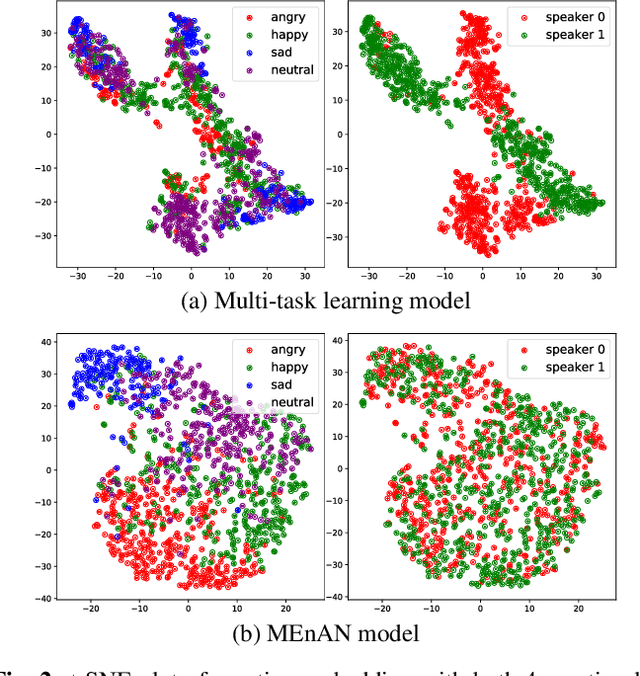
Representation learning for speech emotion recognition is challenging due to labeled data sparsity issue and lack of gold standard references. In addition, there is much variability from input speech signals, human subjective perception of the signals and emotion label ambiguity. In this paper, we propose a machine learning framework to obtain speech emotion representations by limiting the effect of speaker variability in the speech signals. Specifically, we propose to disentangle the speaker characteristics from emotion through an adversarial training network in order to better represent emotion. Our method combines the gradient reversal technique with an entropy loss function to remove such speaker information. Our approach is evaluated on both IEMOCAP and CMU-MOSEI datasets. We show that our method improves speech emotion classification and increases generalization to unseen speakers.
Multiple instance learning with graph neural networks
Jun 12, 2019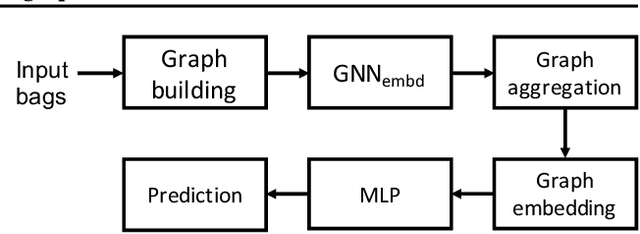
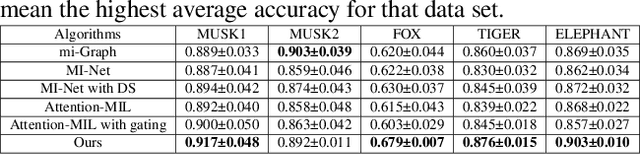
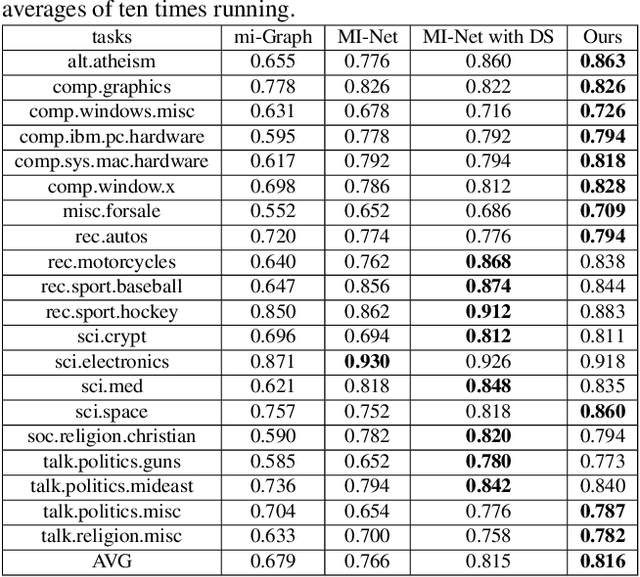
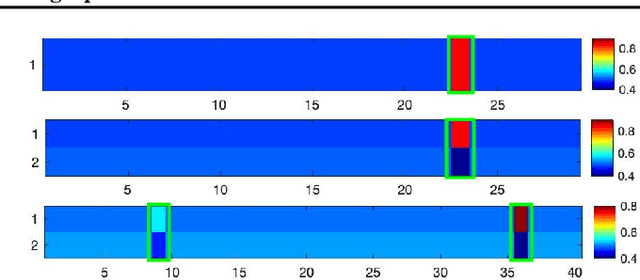
Multiple instance learning (MIL) aims to learn the mapping between a bag of instances and the bag-level label. In this paper, we propose a new end-to-end graph neural network (GNN) based algorithm for MIL: we treat each bag as a graph and use GNN to learn the bag embedding, in order to explore the useful structural information among instances in bags. The final graph representation is fed into a classifier for label prediction. Our algorithm is the first attempt to use GNN for MIL. We empirically show that the proposed algorithm achieves the state of the art performance on several popular MIL data sets without losing model interpretability.
Multi-hop Reading Comprehension across Multiple Documents by Reasoning over Heterogeneous Graphs
Jun 04, 2019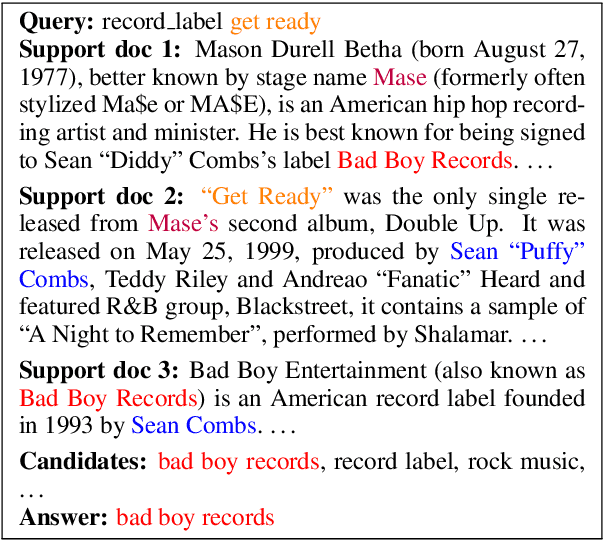
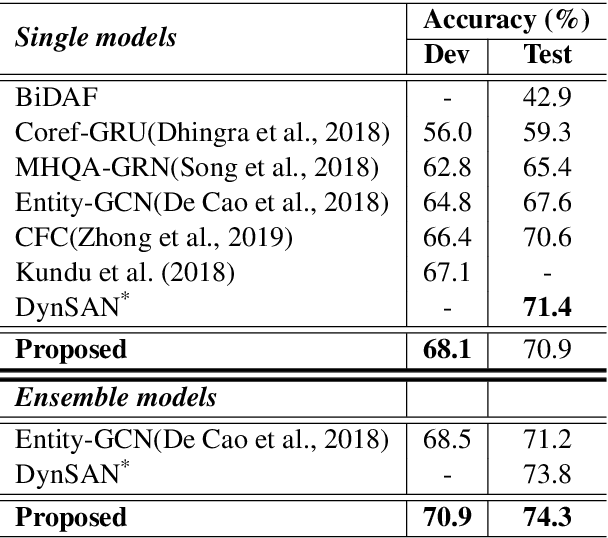
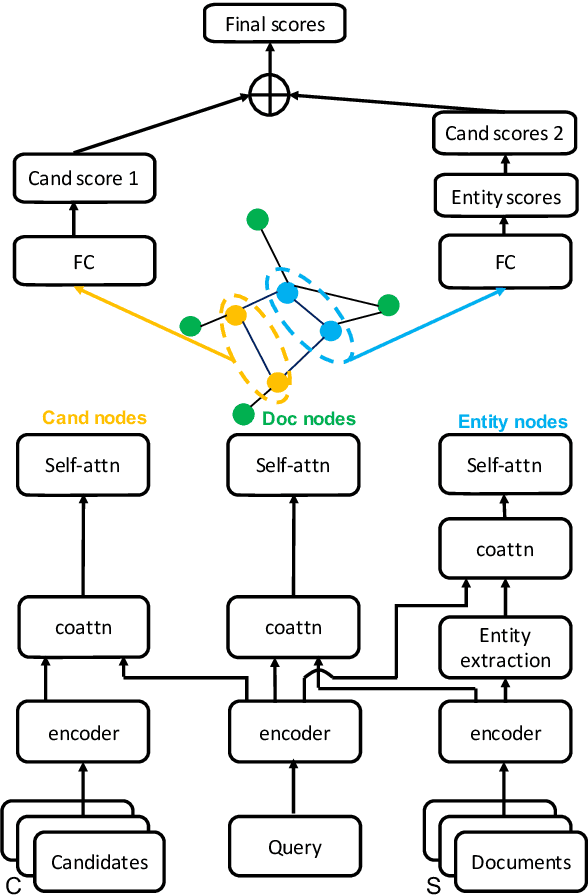
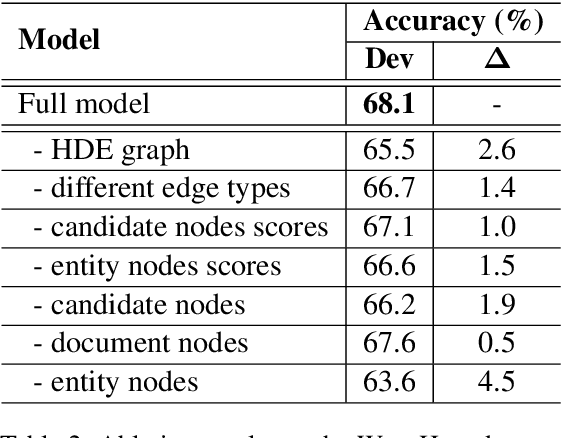
Multi-hop reading comprehension (RC) across documents poses new challenge over single-document RC because it requires reasoning over multiple documents to reach the final answer. In this paper, we propose a new model to tackle the multi-hop RC problem. We introduce a heterogeneous graph with different types of nodes and edges, which is named as Heterogeneous Document-Entity (HDE) graph. The advantage of HDE graph is that it contains different granularity levels of information including candidates, documents and entities in specific document contexts. Our proposed model can do reasoning over the HDE graph with nodes representation initialized with co-attention and self-attention based context encoders. We employ Graph Neural Networks (GNN) based message passing algorithms to accumulate evidences on the proposed HDE graph. Evaluated on the blind test set of the Qangaroo WikiHop data set, our HDE graph based single model delivers competitive result, and the ensemble model achieves the state-of-the-art performance.
I4U Submission to NIST SRE 2018: Leveraging from a Decade of Shared Experiences
Apr 16, 2019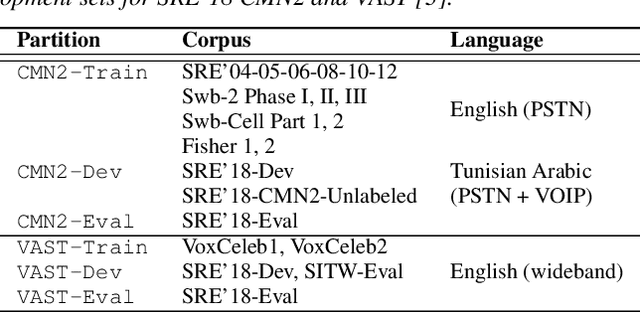
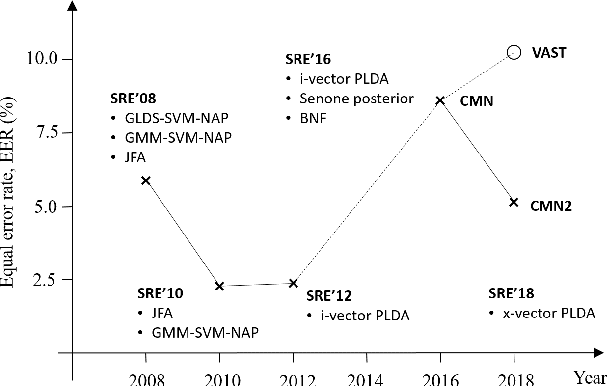
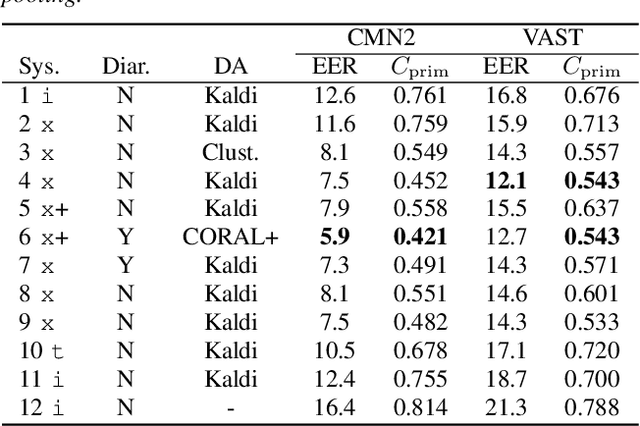
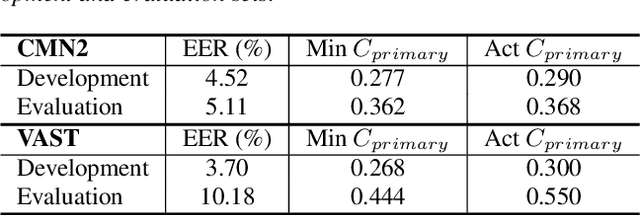
The I4U consortium was established to facilitate a joint entry to NIST speaker recognition evaluations (SRE). The latest edition of such joint submission was in SRE 2018, in which the I4U submission was among the best-performing systems. SRE'18 also marks the 10-year anniversary of I4U consortium into NIST SRE series of evaluation. The primary objective of the current paper is to summarize the results and lessons learned based on the twelve sub-systems and their fusion submitted to SRE'18. It is also our intention to present a shared view on the advancements, progresses, and major paradigm shifts that we have witnessed as an SRE participant in the past decade from SRE'08 to SRE'18. In this regard, we have seen, among others, a paradigm shift from supervector representation to deep speaker embedding, and a switch of research challenge from channel compensation to domain adaptation.
Reducing the Model Order of Deep Neural Networks Using Information Theory
May 16, 2016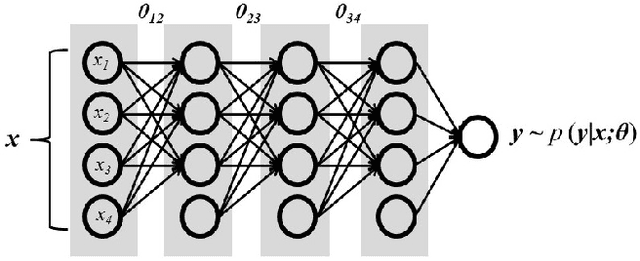
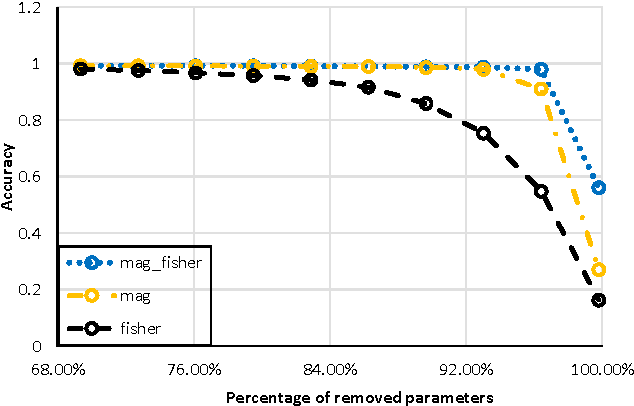
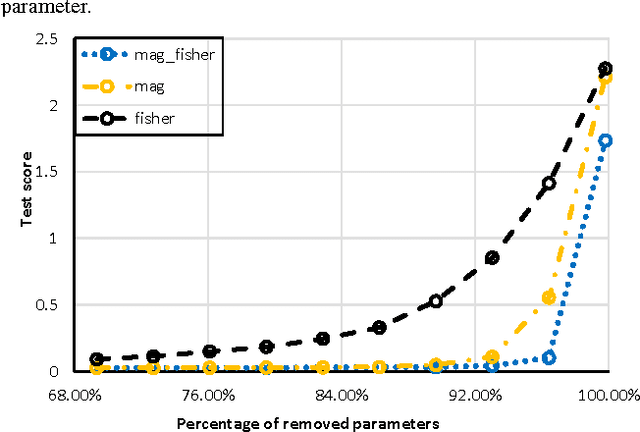
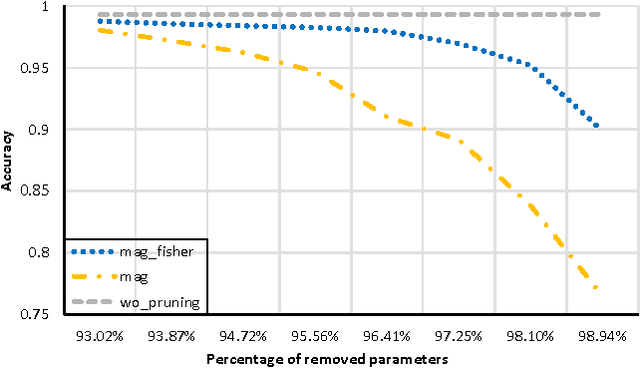
Deep neural networks are typically represented by a much larger number of parameters than shallow models, making them prohibitive for small footprint devices. Recent research shows that there is considerable redundancy in the parameter space of deep neural networks. In this paper, we propose a method to compress deep neural networks by using the Fisher Information metric, which we estimate through a stochastic optimization method that keeps track of second-order information in the network. We first remove unimportant parameters and then use non-uniform fixed point quantization to assign more bits to parameters with higher Fisher Information estimates. We evaluate our method on a classification task with a convolutional neural network trained on the MNIST data set. Experimental results show that our method outperforms existing methods for both network pruning and quantization.