 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Dimension-free Tail Inequalities for Sums of Random Matrices and Applications
Oct 08, 2019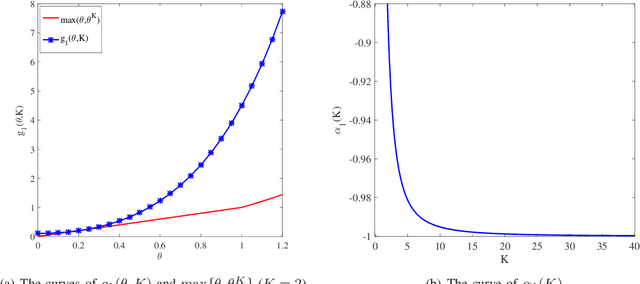
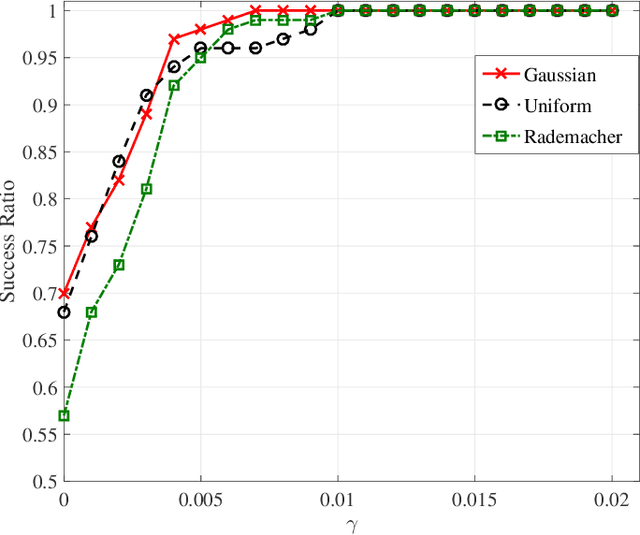
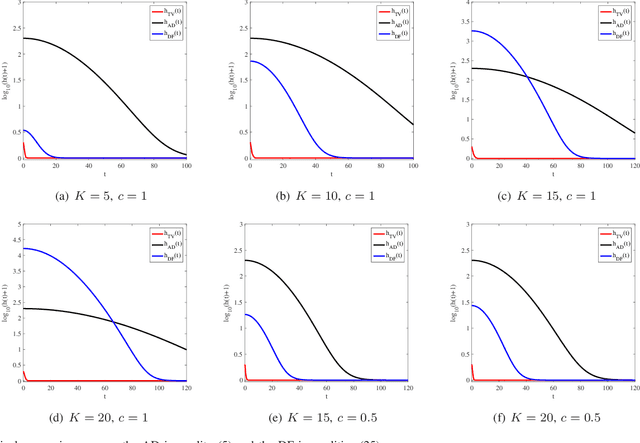
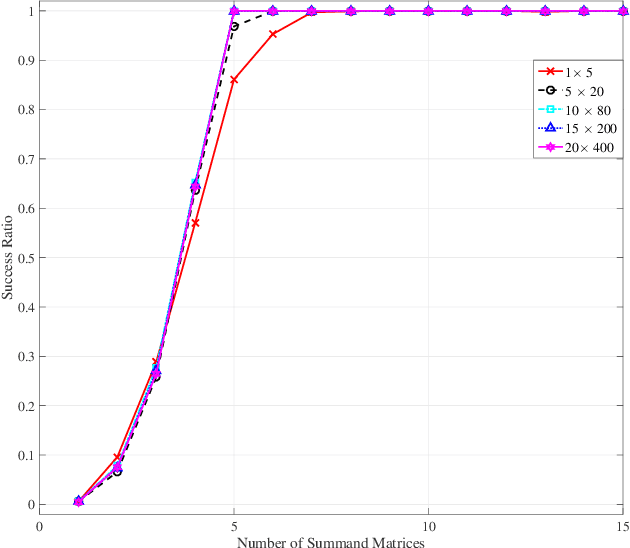
In this paper, we present a new framework to obtain tail inequalities for sums of random matrices. Compared with existing works, our tail inequalities have the following characteristics: 1) high feasibility--they can be used to study the tail behavior of various matrix functions, e.g., arbitrary matrix norms, the absolute value of the sum of the sum of the $j$ largest singular values (resp. eigenvalues) of complex matrices (resp. Hermitian matrices); and 2) independence of matrix dimension --- they do not have the matrix-dimension term as a product factor, and thus are suitable to the scenario of high-dimensional or infinite-dimensional random matrices. The price we pay to obtain these advantages is that the convergence rate of the resulting inequalities will become slow when the number of summand random matrices is large. We also develop the tail inequalities for matrix random series and matrix martingale difference sequence. We also demonstrate usefulness of our tail bounds in several fields. In compressed sensing, we employ the resulted tail inequalities to achieve a proof of the restricted isometry property when the measurement matrix is the sum of random matrices without any assumption on the distributions of matrix entries. In probability theory, we derive a new upper bound to the supreme of stochastic processes. In machine learning, we prove new expectation bounds of sums of random matrices matrix and obtain matrix approximation schemes via random sampling. In quantum information, we show a new analysis relating to the fractional cover number of quantum hypergraphs. In theoretical computer science, we obtain randomness-efficient samplers using matrix expander graphs that can be efficiently implemented in time without dependence on matrix dimensions.
Quantum algorithm for finding the negative curvature direction in non-convex optimization
Sep 17, 2019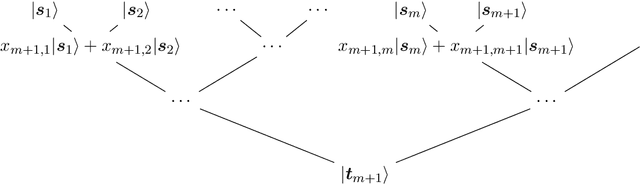
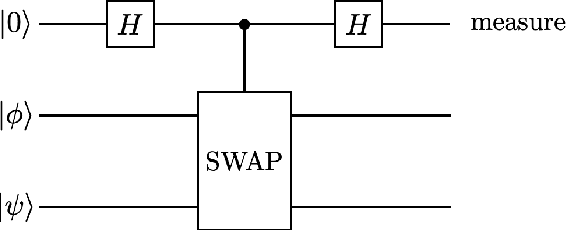
We present an efficient quantum algorithm aiming to find the negative curvature direction for escaping the saddle point, which is the critical subroutine for many second-order non-convex optimization algorithms. We prove that our algorithm could produce the target state corresponding to the negative curvature direction with query complexity O(polylog(d) /{\epsilon}), where d is the dimension of the optimization function. The quantum negative curvature finding algorithm is exponentially faster than any known classical method which takes time at least O(d /\sqrt{\epsilon}). Moreover, we propose an efficient quantum algorithm to achieve the classical read-out of the target state. Our classical read-out algorithm runs exponentially faster on the degree of d than existing counterparts.
A Quantum-inspired Algorithm for General Minimum Conical Hull Problems
Jul 16, 2019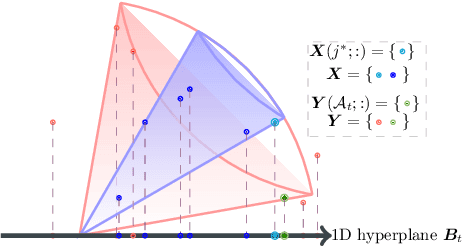
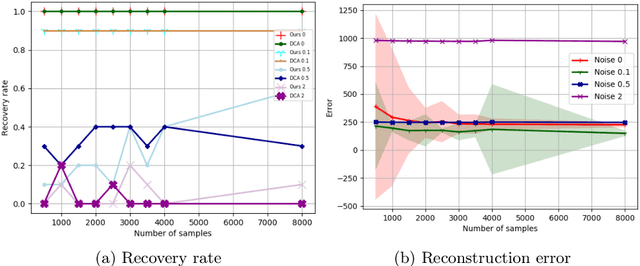
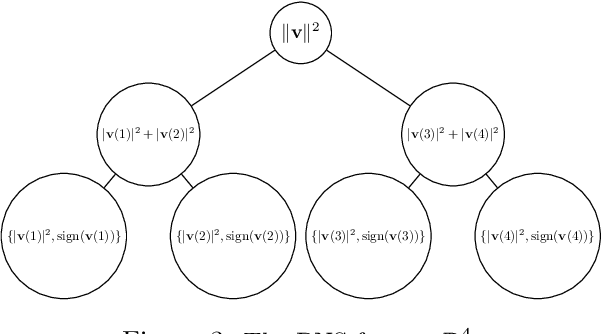
A wide range of fundamental machine learning tasks that are addressed by the maximum a posteriori estimation can be reduced to a general minimum conical hull problem. The best-known solution to tackle general minimum conical hull problems is the divide-and-conquer anchoring learning scheme (DCA), whose runtime complexity is polynomial in size. However, big data is pushing these polynomial algorithms to their performance limits. In this paper, we propose a sublinear classical algorithm to tackle general minimum conical hull problems when the input has stored in a sample-based low-overhead data structure. The algorithm's runtime complexity is polynomial in the rank and polylogarithmic in size. The proposed algorithm achieves the exponential speedup over DCA and, therefore, provides advantages for high dimensional problems.
Efficient Online Quantum Generative Adversarial Learning Algorithms with Applications
Apr 21, 2019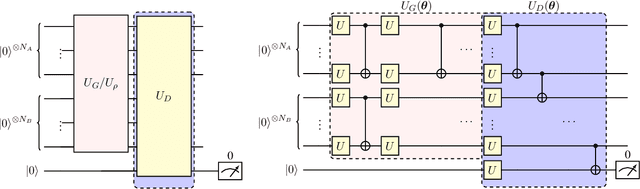
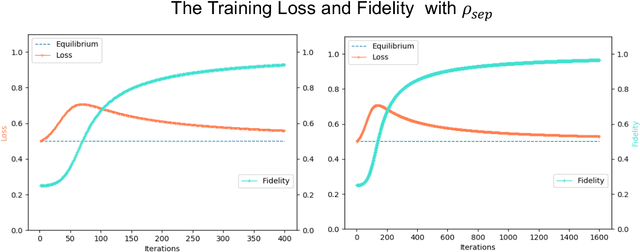
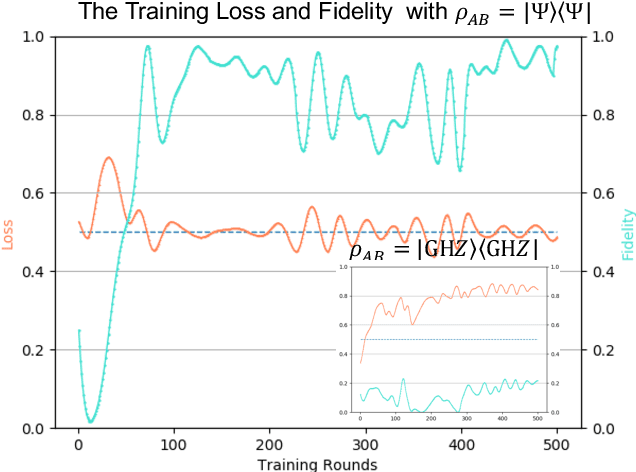
The exploration of quantum algorithms that possess quantum advantages is a central topic in quantum computation and quantum information processing. One potential candidate in this area is quantum generative adversarial learning (QuGAL), which conceptually has exponential advantages over classical adversarial networks. However, the corresponding learning algorithm remains obscured. In this paper, we propose the first quantum generative adversarial learning algorithm-- the quantum multiplicative matrix weight algorithm (QMMW)-- which enables the efficient processing of fundamental tasks. The computational complexity of QMMW is polynomially proportional to the number of training rounds and logarithmically proportional to the input size. The core concept of the proposed algorithm combines QuGAL with online learning. We exploit the implementation of QuGAL with parameterized quantum circuits, and numerical experiments for the task of entanglement test for pure state are provided to support our claims.
Quantum Speedup in Adaptive Boosting of Binary Classification
Feb 03, 2019
In classical machine learning, a set of weak classifiers can be adaptively combined to form a strong classifier for improving the overall performance, a technique called adaptive boosting (or AdaBoost). However, constructing the strong classifier for a large data set is typically resource consuming. Here we propose a quantum extension of AdaBoost, demonstrating a quantum algorithm that can output the optimal strong classifier with a quadratic speedup in the number of queries of the weak classifiers. Our results also include a generalization of the standard AdaBoost to the cases where the output of each classifier may be probabilistic even for the same input. We prove that the update rules and the query complexity of the non-deterministic classifiers are the same as those of deterministic classifiers, which may be of independent interest to the classical machine-learning community. Furthermore, the AdaBoost algorithm can also be applied to data encoded in the form of quantum states; we show how the training set can be simplified by using the tools of t-design. Our approach describes a model of quantum machine learning where quantum speedup is achieved in finding the optimal classifier, which can then be applied for classical machine-learning applications.
Generalization Bounds for Vicinal Risk Minimization Principle
Nov 11, 2018The vicinal risk minimization (VRM) principle, first proposed by \citet{vapnik1999nature}, is an empirical risk minimization (ERM) variant that replaces Dirac masses with vicinal functions. Although there is strong numerical evidence showing that VRM outperforms ERM if appropriate vicinal functions are chosen, a comprehensive theoretical understanding of VRM is still lacking. In this paper, we study the generalization bounds for VRM. Our results support Vapnik's original arguments and additionally provide deeper insights into VRM. First, we prove that the complexity of function classes convolving with vicinal functions can be controlled by that of the original function classes under the assumption that the function class is composed of Lipschitz-continuous functions. Then, the resulting generalization bounds for VRM suggest that the generalization performance of VRM is also effected by the choice of vicinity function and the quality of function classes. These findings can be used to examine whether the choice of vicinal function is appropriate for the VRM-based learning setting. Finally, we provide a theoretical explanation for existing VRM models, e.g., uniform distribution-based models, Gaussian distribution-based models, and mixup models.
The Expressive Power of Parameterized Quantum Circuits
Oct 29, 2018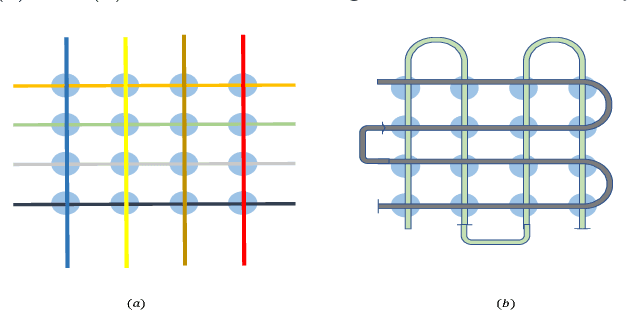
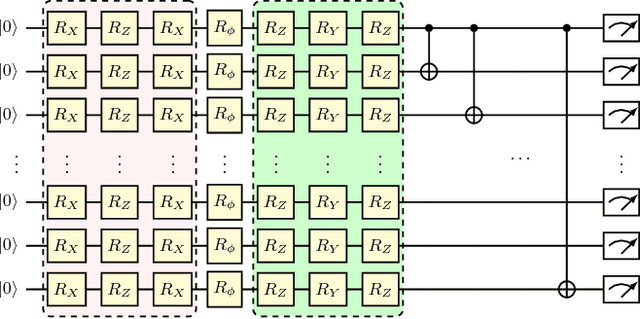
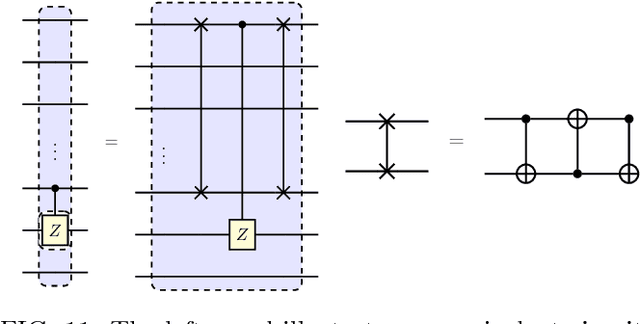
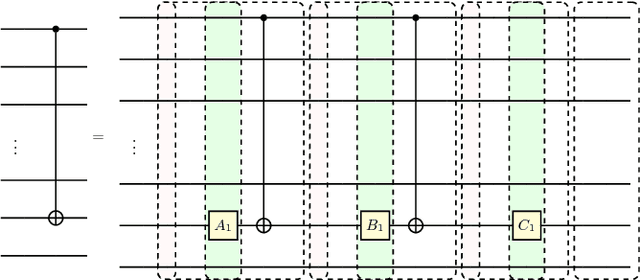
Parameterized quantum circuits (PQCs) have been broadly used as a hybrid quantum-classical machine learning scheme to accomplish generative tasks. However, whether PQCs have better expressive power than classical generative neural networks, such as restricted or deep Boltzmann machines, remains an open issue. In this paper, we prove that PQCs with a simple structure already outperform any classical neural network for generative tasks, unless the polynomial hierarchy collapses. Our proof builds on known results from tensor networks and quantum circuits (in particular, instantaneous quantum polynomial circuits). In addition, PQCs equipped with ancillary qubits for post-selection have even stronger expressive power than those without post-selection. We employ them as an application for Bayesian learning, since it is possible to learn prior probabilities rather than assuming they are known. We expect that it will find many more applications in semi-supervised learning where prior distributions are normally assumed to be unknown. Lastly, we conduct several numerical experiments using the Rigetti Forest platform to demonstrate the performance of the proposed Bayesian quantum circuit.
Implementable Quantum Classifier for Nonlinear Data
Sep 17, 2018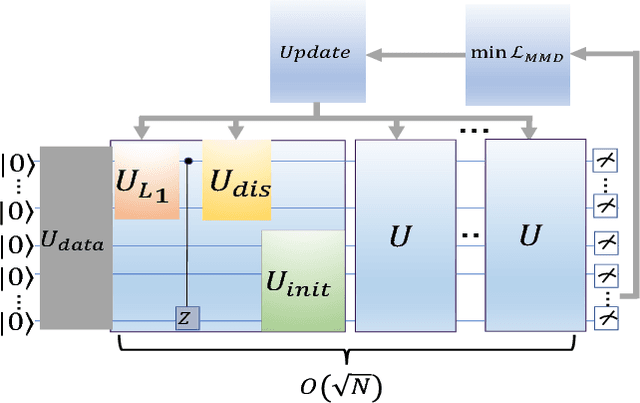
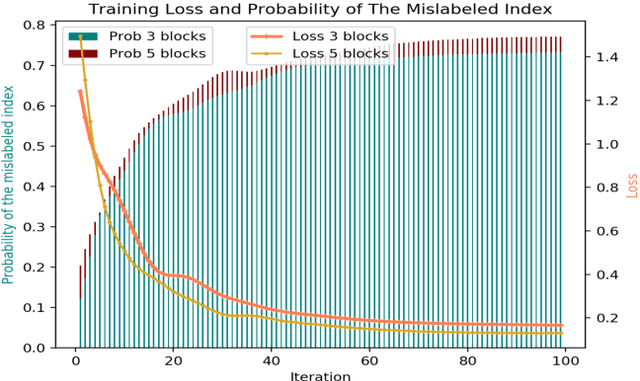
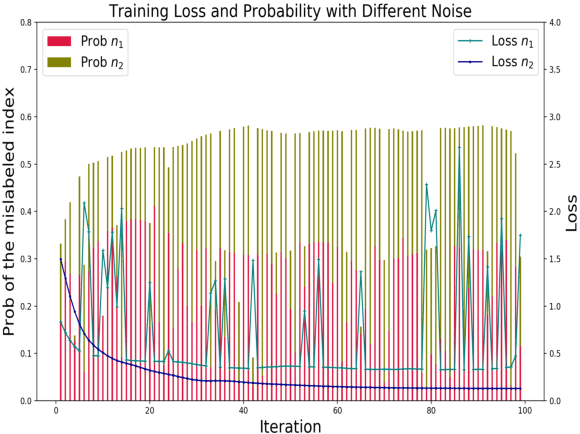
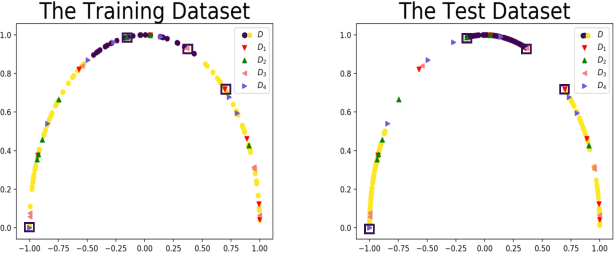
In this Letter, we propose a quantum machine learning scheme for the classification of classical nonlinear data. The main ingredients of our method are variational quantum perceptron (VQP) and a quantum generalization of classical ensemble learning. Our VQP employs parameterized quantum circuits to learn a Grover search (or amplitude amplification) operation with classical optimization, and can achieve quadratic speedup in query complexity compared to its classical counterparts. We show how the trained VQP can be used to predict future data with $O(1)$ {query} complexity. Ultimately, a stronger nonlinear classifier can be established, the so-called quantum ensemble learning (QEL), by combining a set of weak VQPs produced using a subsampling method. The subsampling method has two significant advantages. First, all $T$ weak VQPs employed in QEL can be trained in parallel, therefore, the query complexity of QEL is equal to that of each weak VQP multiplied by $T$. Second, it dramatically reduce the {runtime} complexity of encoding circuits that map classical data to a quantum state because this dataset can be significantly smaller than the original dataset given to QEL. This arguably provides a most satisfactory solution to one of the most criticized issues in quantum machine learning proposals. To conclude, we perform two numerical experiments for our VQP and QEL, implemented by Python and pyQuil library. Our experiments show that excellent performance can be achieved using a very small quantum circuit size that is implementable under current quantum hardware development. Specifically, given a nonlinear synthetic dataset with $4$ features for each example, the trained QEL can classify the test examples that are sampled away from the decision boundaries using $146$ single and two qubits quantum gates with $92\%$ accuracy.
The Learnability of Unknown Quantum Measurements
Jan 03, 2015

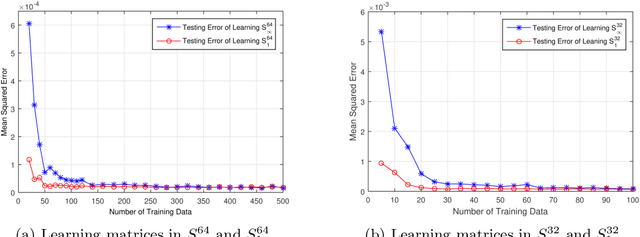

Quantum machine learning has received significant attention in recent years, and promising progress has been made in the development of quantum algorithms to speed up traditional machine learning tasks. In this work, however, we focus on investigating the information-theoretic upper bounds of sample complexity - how many training samples are sufficient to predict the future behaviour of an unknown target function. This kind of problem is, arguably, one of the most fundamental problems in statistical learning theory and the bounds for practical settings can be completely characterised by a simple measure of complexity. Our main result in the paper is that, for learning an unknown quantum measurement, the upper bound, given by the fat-shattering dimension, is linearly proportional to the dimension of the underlying Hilbert space. Learning an unknown quantum state becomes a dual problem to ours, and as a byproduct, we can recover Aaronson's famous result [Proc. R. Soc. A 463:3089-3144 (2007)] solely using a classical machine learning technique. In addition, other famous complexity measures like covering numbers and Rademacher complexities are derived explicitly. We are able to connect measures of sample complexity with various areas in quantum information science, e.g. quantum state/measurement tomography, quantum state discrimination and quantum random access codes, which may be of independent interest. Lastly, with the assistance of general Bloch-sphere representation, we show that learning quantum measurements/states can be mathematically formulated as a neural network. Consequently, classical ML algorithms can be applied to efficiently accomplish the two quantum learning tasks.