 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePieces of Eight: 8-bit Neural Machine Translation
Apr 13, 2018

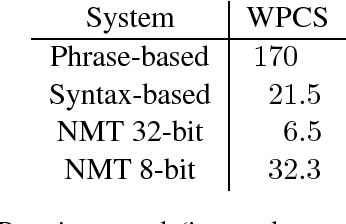
Neural machine translation has achieved levels of fluency and adequacy that would have been surprising a short time ago. Output quality is extremely relevant for industry purposes, however it is equally important to produce results in the shortest time possible, mainly for latency-sensitive applications and to control cloud hosting costs. In this paper we show the effectiveness of translating with 8-bit quantization for models that have been trained using 32-bit floating point values. Results show that 8-bit translation makes a non-negligible impact in terms of speed with no degradation in accuracy and adequacy.
AMR Parsing using Stack-LSTMs
Aug 02, 2017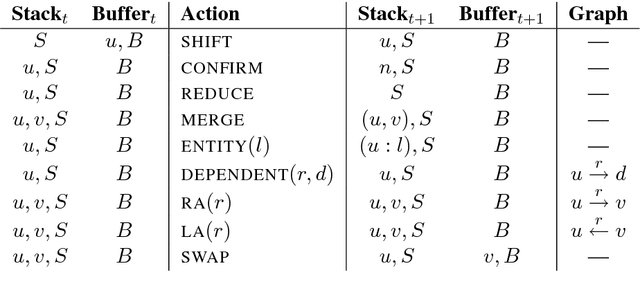
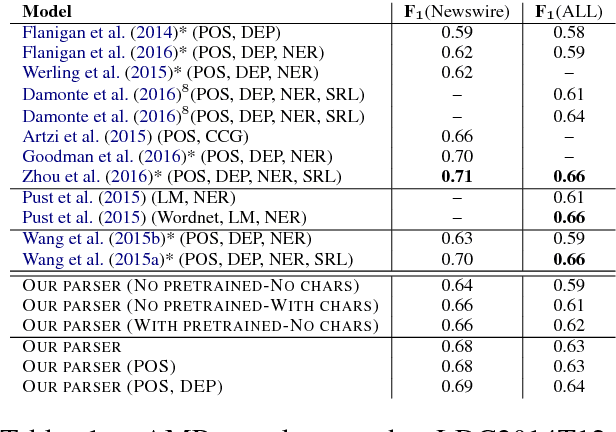

We present a transition-based AMR parser that directly generates AMR parses from plain text. We use Stack-LSTMs to represent our parser state and make decisions greedily. In our experiments, we show that our parser achieves very competitive scores on English using only AMR training data. Adding additional information, such as POS tags and dependency trees, improves the results further.
Are Emojis Predictable?
Feb 24, 2017

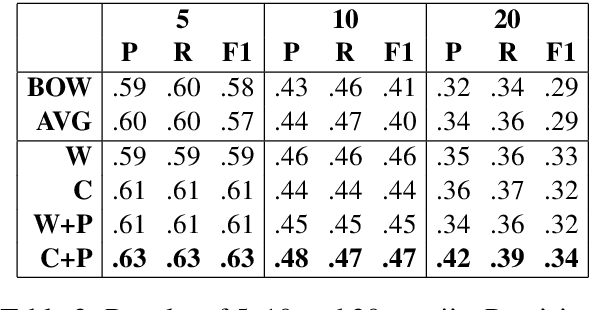
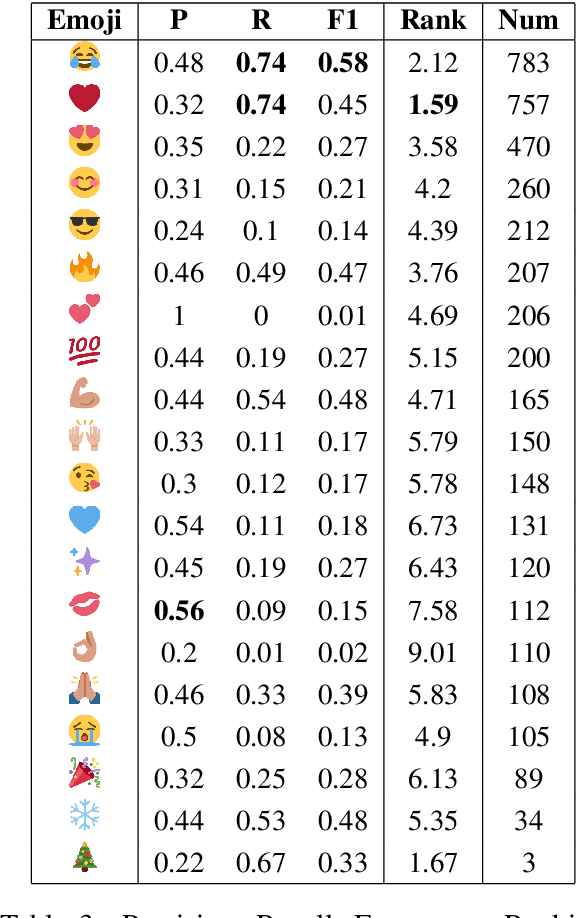
Emojis are ideograms which are naturally combined with plain text to visually complement or condense the meaning of a message. Despite being widely used in social media, their underlying semantics have received little attention from a Natural Language Processing standpoint. In this paper, we investigate the relation between words and emojis, studying the novel task of predicting which emojis are evoked by text-based tweet messages. We train several models based on Long Short-Term Memory networks (LSTMs) in this task. Our experimental results show that our neural model outperforms two baselines as well as humans solving the same task, suggesting that computational models are able to better capture the underlying semantics of emojis.
DyNet: The Dynamic Neural Network Toolkit
Jan 15, 2017
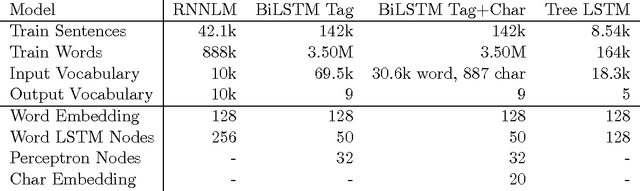

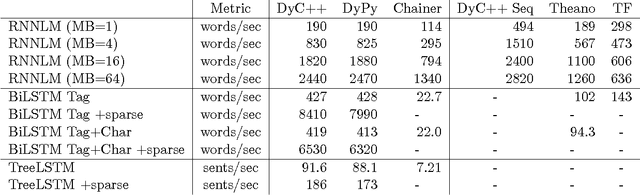
We describe DyNet, a toolkit for implementing neural network models based on dynamic declaration of network structure. In the static declaration strategy that is used in toolkits like Theano, CNTK, and TensorFlow, the user first defines a computation graph (a symbolic representation of the computation), and then examples are fed into an engine that executes this computation and computes its derivatives. In DyNet's dynamic declaration strategy, computation graph construction is mostly transparent, being implicitly constructed by executing procedural code that computes the network outputs, and the user is free to use different network structures for each input. Dynamic declaration thus facilitates the implementation of more complicated network architectures, and DyNet is specifically designed to allow users to implement their models in a way that is idiomatic in their preferred programming language (C++ or Python). One challenge with dynamic declaration is that because the symbolic computation graph is defined anew for every training example, its construction must have low overhead. To achieve this, DyNet has an optimized C++ backend and lightweight graph representation. Experiments show that DyNet's speeds are faster than or comparable with static declaration toolkits, and significantly faster than Chainer, another dynamic declaration toolkit. DyNet is released open-source under the Apache 2.0 license and available at http://github.com/clab/dynet.
What Do Recurrent Neural Network Grammars Learn About Syntax?
Jan 10, 2017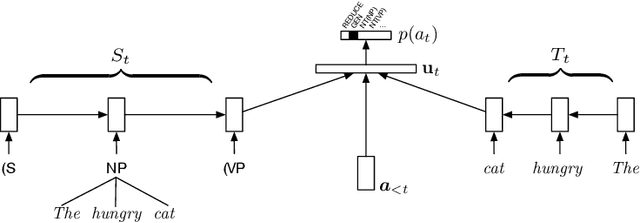
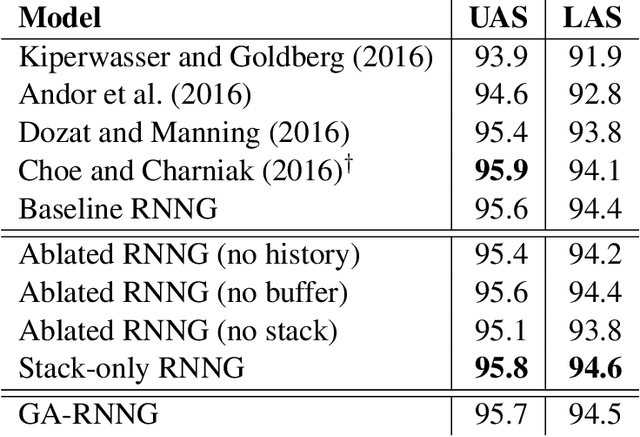

Recurrent neural network grammars (RNNG) are a recently proposed probabilistic generative modeling family for natural language. They show state-of-the-art language modeling and parsing performance. We investigate what information they learn, from a linguistic perspective, through various ablations to the model and the data, and by augmenting the model with an attention mechanism (GA-RNNG) to enable closer inspection. We find that explicit modeling of composition is crucial for achieving the best performance. Through the attention mechanism, we find that headedness plays a central role in phrasal representation (with the model's latent attention largely agreeing with predictions made by hand-crafted head rules, albeit with some important differences). By training grammars without nonterminal labels, we find that phrasal representations depend minimally on nonterminals, providing support for the endocentricity hypothesis.
Recurrent Neural Network Grammars
Oct 12, 2016

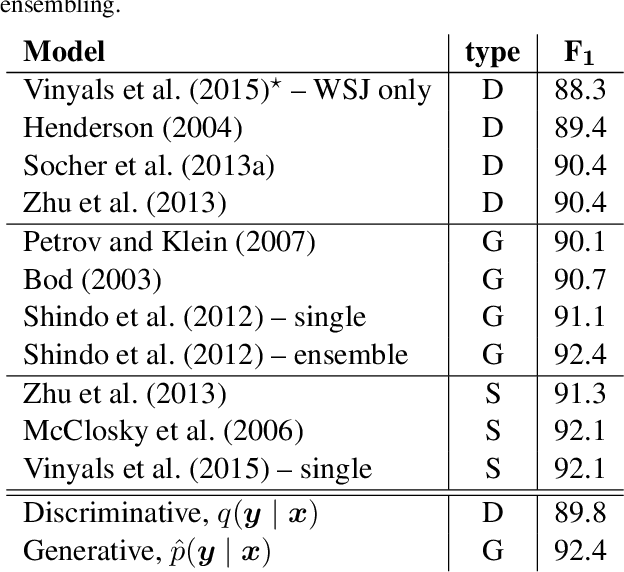
We introduce recurrent neural network grammars, probabilistic models of sentences with explicit phrase structure. We explain efficient inference procedures that allow application to both parsing and language modeling. Experiments show that they provide better parsing in English than any single previously published supervised generative model and better language modeling than state-of-the-art sequential RNNs in English and Chinese.
Distilling an Ensemble of Greedy Dependency Parsers into One MST Parser
Sep 24, 2016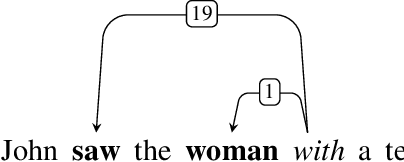



We introduce two first-order graph-based dependency parsers achieving a new state of the art. The first is a consensus parser built from an ensemble of independently trained greedy LSTM transition-based parsers with different random initializations. We cast this approach as minimum Bayes risk decoding (under the Hamming cost) and argue that weaker consensus within the ensemble is a useful signal of difficulty or ambiguity. The second parser is a "distillation" of the ensemble into a single model. We train the distillation parser using a structured hinge loss objective with a novel cost that incorporates ensemble uncertainty estimates for each possible attachment, thereby avoiding the intractable cross-entropy computations required by applying standard distillation objectives to problems with structured outputs. The first-order distillation parser matches or surpasses the state of the art on English, Chinese, and German.
Training with Exploration Improves a Greedy Stack-LSTM Parser
Sep 13, 2016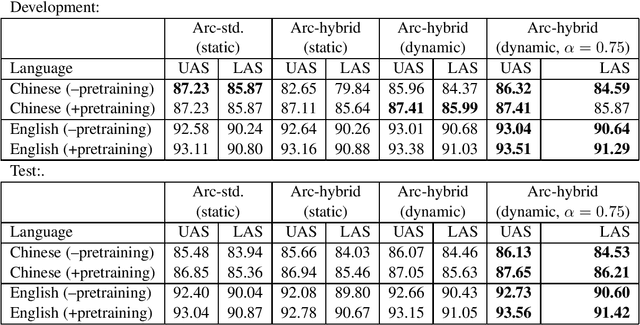
We adapt the greedy Stack-LSTM dependency parser of Dyer et al. (2015) to support a training-with-exploration procedure using dynamic oracles(Goldberg and Nivre, 2013) instead of cross-entropy minimization. This form of training, which accounts for model predictions at training time rather than assuming an error-free action history, improves parsing accuracies for both English and Chinese, obtaining very strong results for both languages. We discuss some modifications needed in order to get training with exploration to work well for a probabilistic neural-network.
Many Languages, One Parser
Jul 26, 2016We train one multilingual model for dependency parsing and use it to parse sentences in several languages. The parsing model uses (i) multilingual word clusters and embeddings; (ii) token-level language information; and (iii) language-specific features (fine-grained POS tags). This input representation enables the parser not only to parse effectively in multiple languages, but also to generalize across languages based on linguistic universals and typological similarities, making it more effective to learn from limited annotations. Our parser's performance compares favorably to strong baselines in a range of data scenarios, including when the target language has a large treebank, a small treebank, or no treebank for training.
Neural Architectures for Named Entity Recognition
Apr 07, 2016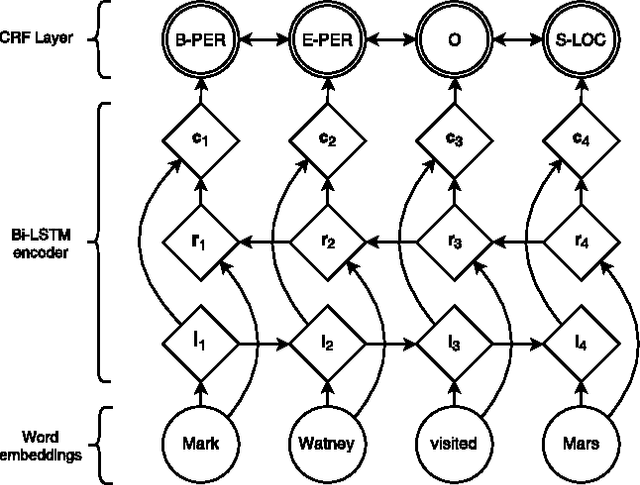
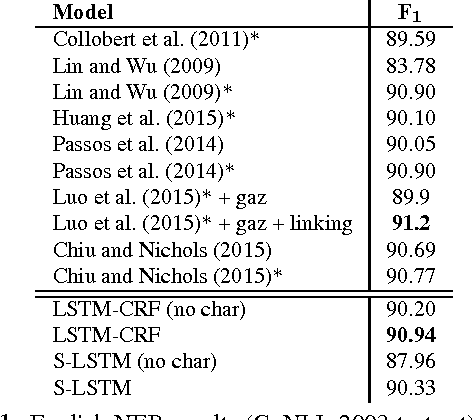

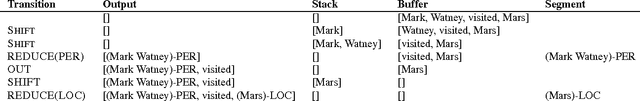
State-of-the-art named entity recognition systems rely heavily on hand-crafted features and domain-specific knowledge in order to learn effectively from the small, supervised training corpora that are available. In this paper, we introduce two new neural architectures---one based on bidirectional LSTMs and conditional random fields, and the other that constructs and labels segments using a transition-based approach inspired by shift-reduce parsers. Our models rely on two sources of information about words: character-based word representations learned from the supervised corpus and unsupervised word representations learned from unannotated corpora. Our models obtain state-of-the-art performance in NER in four languages without resorting to any language-specific knowledge or resources such as gazetteers.