 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViLMA: A Zero-Shot Benchmark for Linguistic and Temporal Grounding in Video-Language Models
Nov 13, 2023



With the ever-increasing popularity of pretrained Video-Language Models (VidLMs), there is a pressing need to develop robust evaluation methodologies that delve deeper into their visio-linguistic capabilities. To address this challenge, we present ViLMA (Video Language Model Assessment), a task-agnostic benchmark that places the assessment of fine-grained capabilities of these models on a firm footing. Task-based evaluations, while valuable, fail to capture the complexities and specific temporal aspects of moving images that VidLMs need to process. Through carefully curated counterfactuals, ViLMA offers a controlled evaluation suite that sheds light on the true potential of these models, as well as their performance gaps compared to human-level understanding. ViLMA also includes proficiency tests, which assess basic capabilities deemed essential to solving the main counterfactual tests. We show that current VidLMs' grounding abilities are no better than those of vision-language models which use static images. This is especially striking once the performance on proficiency tests is factored in. Our benchmark serves as a catalyst for future research on VidLMs, helping to highlight areas that still need to be explored.
Interpreting Vision and Language Generative Models with Semantic Visual Priors
May 04, 2023



When applied to Image-to-text models, interpretability methods often provide token-by-token explanations namely, they compute a visual explanation for each token of the generated sequence. Those explanations are expensive to compute and unable to comprehensively explain the model's output. Therefore, these models often require some sort of approximation that eventually leads to misleading explanations. We develop a framework based on SHAP, that allows for generating comprehensive, meaningful explanations leveraging the meaning representation of the output sequence as a whole. Moreover, by exploiting semantic priors in the visual backbone, we extract an arbitrary number of features that allows the efficient computation of Shapley values on large-scale models, generating at the same time highly meaningful visual explanations. We demonstrate that our method generates semantically more expressive explanations than traditional methods at a lower compute cost and that it can be generalized over other explainability methods.
HL Dataset: Grounding High-Level Linguistic Concepts in Vision
Feb 23, 2023



Current captioning datasets, focus on object-centric captions, describing the visible objects in the image, often ending up stating the obvious (for humans), e.g. "people eating food in a park". Although these datasets are useful to evaluate the ability of Vision & Language models to recognize the visual content, they lack in expressing trivial abstract concepts, e.g. "people having a picnic". Such concepts are licensed by human's personal experience and contribute to forming common sense assumptions. We present the High-Level Dataset; a dataset extending 14997 images of the COCO dataset with 134973 human-annotated (high-level) abstract captions collected along three axes: scenes, actions and rationales. We describe and release such dataset and we show how it can be used to assess models' multimodal grounding of abstract concepts and enrich models' visio-lingusitic representations. Moreover, we describe potential tasks enabled by this dataset involving high- and low-level concepts interactions.
Understanding Cross-modal Interactions in V&L Models that Generate Scene Descriptions
Nov 10, 2022



Image captioning models tend to describe images in an object-centric way, emphasising visible objects. But image descriptions can also abstract away from objects and describe the type of scene depicted. In this paper, we explore the potential of a state-of-the-art Vision and Language model, VinVL, to caption images at the scene level using (1) a novel dataset which pairs images with both object-centric and scene descriptions. Through (2) an in-depth analysis of the effect of the fine-tuning, we show (3) that a small amount of curated data suffices to generate scene descriptions without losing the capability to identify object-level concepts in the scene; the model acquires a more holistic view of the image compared to when object-centric descriptions are generated. We discuss the parallels between these results and insights from computational and cognitive science research on scene perception.
VALSE: A Task-Independent Benchmark for Vision and Language Models Centered on Linguistic Phenomena
Dec 14, 2021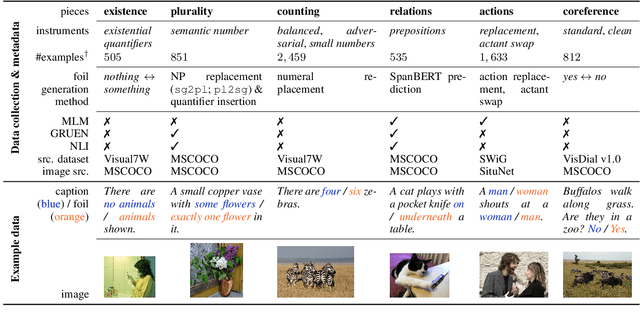
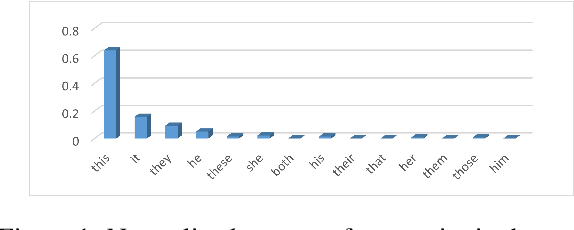
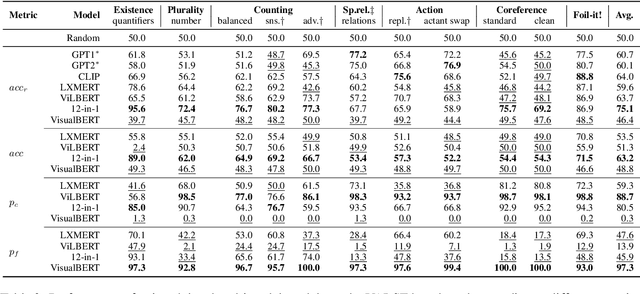
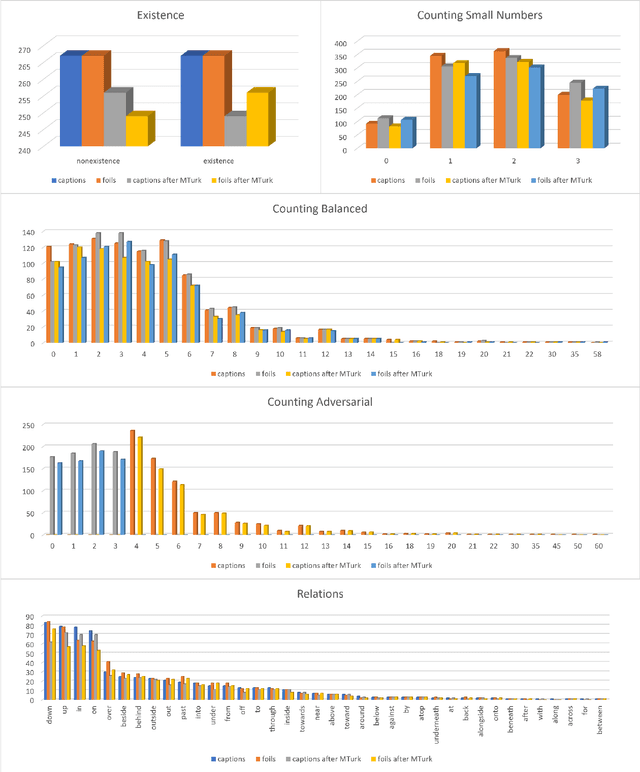
We propose VALSE (Vision And Language Structured Evaluation), a novel benchmark designed for testing general-purpose pretrained vision and language (V&L) models for their visio-linguistic grounding capabilities on specific linguistic phenomena. VALSE offers a suite of six tests covering various linguistic constructs. Solving these requires models to ground linguistic phenomena in the visual modality, allowing more fine-grained evaluations than hitherto possible. We build VALSE using methods that support the construction of valid foils, and report results from evaluating five widely-used V&L models. Our experiments suggest that current models have considerable difficulty addressing most phenomena. Hence, we expect VALSE to serve as an important benchmark to measure future progress of pretrained V&L models from a linguistic perspective, complementing the canonical task-centred V&L evaluations.
What Vision-Language Models `See' when they See Scenes
Sep 15, 2021
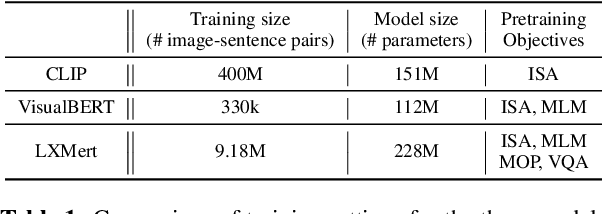
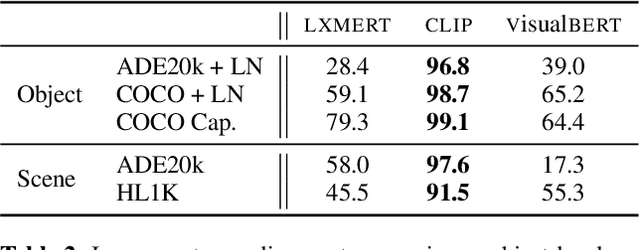
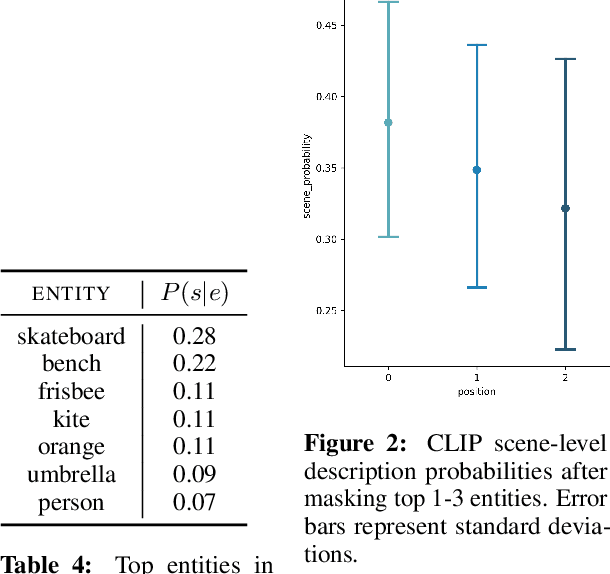
Images can be described in terms of the objects they contain, or in terms of the types of scene or place that they instantiate. In this paper we address to what extent pretrained Vision and Language models can learn to align descriptions of both types with images. We compare 3 state-of-the-art models, VisualBERT, LXMERT and CLIP. We find that (i) V&L models are susceptible to stylistic biases acquired during pretraining; (ii) only CLIP performs consistently well on both object- and scene-level descriptions. A follow-up ablation study shows that CLIP uses object-level information in the visual modality to align with scene-level textual descriptions.
On the interaction of automatic evaluation and task framing in headline style transfer
Jan 05, 2021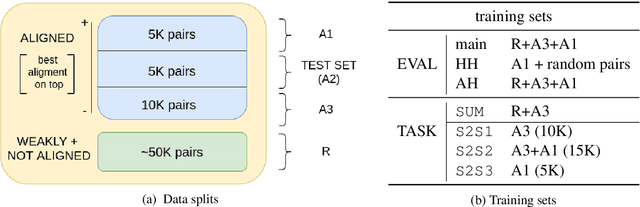
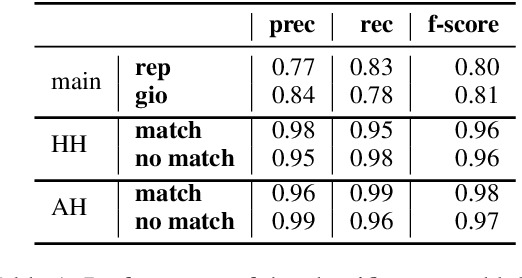
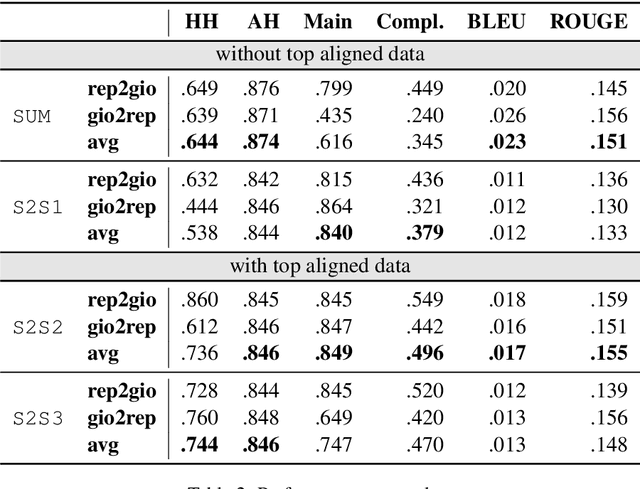
An ongoing debate in the NLG community concerns the best way to evaluate systems, with human evaluation often being considered the most reliable method, compared to corpus-based metrics. However, tasks involving subtle textual differences, such as style transfer, tend to be hard for humans to perform. In this paper, we propose an evaluation method for this task based on purposely-trained classifiers, showing that it better reflects system differences than traditional metrics such as BLEU and ROUGE.
GePpeTto Carves Italian into a Language Model
Apr 29, 2020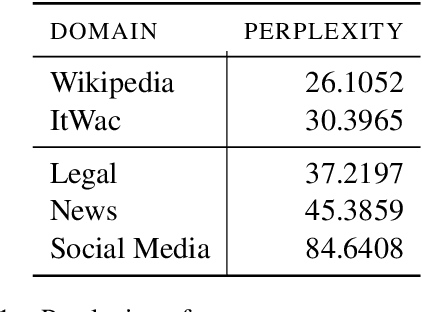
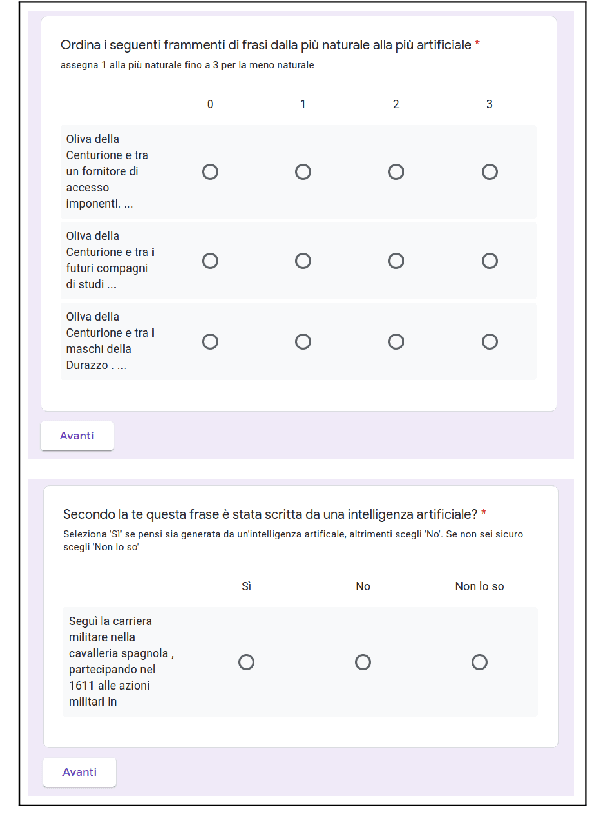
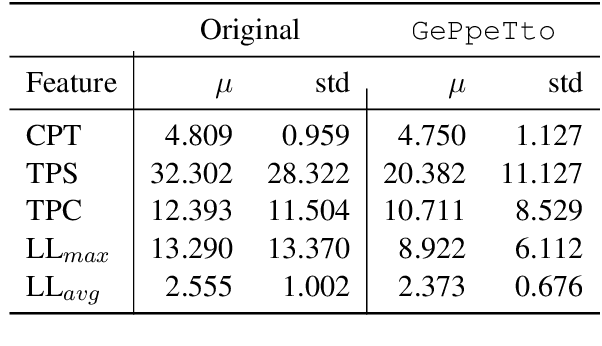
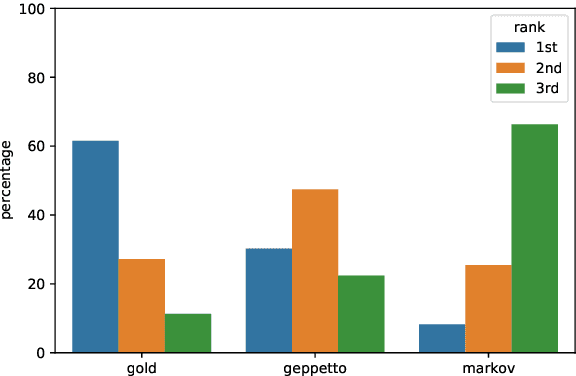
In the last few years, pre-trained neural architectures have provided impressive improvements across several NLP tasks. Still, generative language models are available mainly for English. We develop GePpeTto, the first generative language model for Italian, built using the GPT-2 architecture. We provide a thorough analysis of GePpeTto's quality by means of both an automatic and a human-based evaluation. The automatic assessment consists in (i) calculating perplexity across different genres and (ii) a profiling analysis over GePpeTto's writing characteristics. We find that GePpeTto's production is a sort of bonsai version of human production, with shorter but yet complex sentences. Human evaluation is performed over a sentence completion task, where GePpeTto's output is judged as natural more often than not, and much closer to the original human texts than to a simpler language model which we take as baseline.