 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the Fifth Shared Task on Multilingual Coreference Resolution: Expanding Datasets for Long-Range Entities
May 20, 2026This paper describes the fifth edition of the Shared Task on Multilingual Coreference Resolution, held in conjunction with the CODI-CRAC 2026 workshop. Building on previous iterations, the task required participants to develop systems capable of mention identification and identity-based coreference clustering. The 2026 edition specifically emphasizes long-range entities, defined as coreferential chains spanning significant distances, across many words and sentences. The task expanded its linguistic scope by incorporating five new datasets and two additional languages. These additions leverage version 1.4 of CorefUD, a harmonized multilingual collection comprising 27 datasets in 19 languages. In total, ten systems participated, including four LLM-based approaches (three fine-tuned models and one few-shot approach). While traditional systems still maintained their lead, LLMs demonstrated significant potential, suggesting they may soon challenge established approaches in future editions.
Mitigating Language Barriers in Education: Developing Multilingual Digital Learning Materials with Machine Translation
Sep 11, 2025The EdUKate project combines digital education, linguistics, translation studies, and machine translation to develop multilingual learning materials for Czech primary and secondary schools. Launched through collaboration between a major Czech academic institution and the country's largest educational publisher, the project is aimed at translating up to 9,000 multimodal interactive exercises from Czech into Ukrainian, English, and German for an educational web portal. It emphasizes the development and evaluation of a direct Czech-Ukrainian machine translation system tailored to the educational domain, with special attention to processing formatted content such as XML and PDF and handling technical and scientific terminology. We present findings from an initial survey of Czech teachers regarding the needs of non-Czech-speaking students and describe the system's evaluation and implementation on the web portal. All resulting applications are freely available to students, educators, and researchers.
* 8 pages, 2 figures
Findings of the Third Shared Task on Multilingual Coreference Resolution
Oct 21, 2024



The paper presents an overview of the third edition of the shared task on multilingual coreference resolution, held as part of the CRAC 2024 workshop. Similarly to the previous two editions, the participants were challenged to develop systems capable of identifying mentions and clustering them based on identity coreference. This year's edition took another step towards real-world application by not providing participants with gold slots for zero anaphora, increasing the task's complexity and realism. In addition, the shared task was expanded to include a more diverse set of languages, with a particular focus on historical languages. The training and evaluation data were drawn from version 1.2 of the multilingual collection of harmonized coreference resources CorefUD, encompassing 21 datasets across 15 languages. 6 systems competed in this shared task.
Charles Translator: A Machine Translation System between Ukrainian and Czech
Apr 10, 2024



We present Charles Translator, a machine translation system between Ukrainian and Czech, developed as part of a society-wide effort to mitigate the impact of the Russian-Ukrainian war on individuals and society. The system was developed in the spring of 2022 with the help of many language data providers in order to quickly meet the demand for such a service, which was not available at the time in the required quality. The translator was later implemented as an online web interface and as an Android app with speech input, both featuring Cyrillic-Latin script transliteration. The system translates directly, compared to other available systems that use English as a pivot, and thus take advantage of the typological similarity of the two languages. It uses the block back-translation method, which allows for efficient use of monolingual training data. The paper describes the development process, including data collection and implementation, evaluation, mentions several use cases, and outlines possibilities for the further development of the system for educational purposes.
Negative Lexical Constraints in Neural Machine Translation
Aug 07, 2023



This paper explores negative lexical constraining in English to Czech neural machine translation. Negative lexical constraining is used to prohibit certain words or expressions in the translation produced by the neural translation model. We compared various methods based on modifying either the decoding process or the training data. The comparison was performed on two tasks: paraphrasing and feedback-based translation refinement. We also studied to which extent these methods "evade" the constraints presented to the model (usually in the dictionary form) by generating a different surface form of a given constraint.We propose a way to mitigate the issue through training with stemmed negative constraints to counter the model's ability to induce a variety of the surface forms of a word that can result in bypassing the constraint. We demonstrate that our method improves the constraining, although the problem still persists in many cases.
Findings of the Shared Task on Multilingual Coreference Resolution
Sep 16, 2022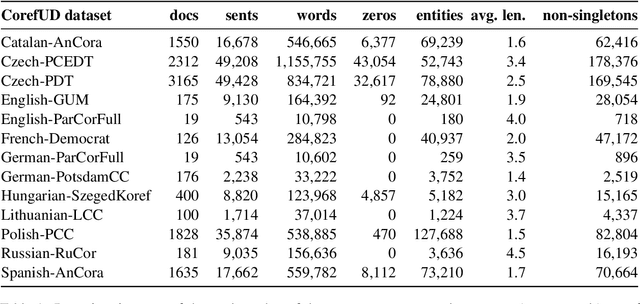
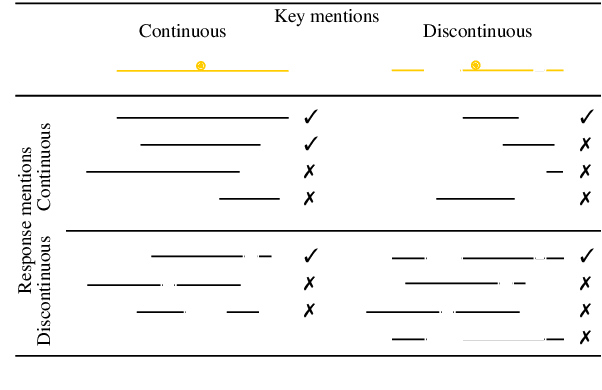

This paper presents an overview of the shared task on multilingual coreference resolution associated with the CRAC 2022 workshop. Shared task participants were supposed to develop trainable systems capable of identifying mentions and clustering them according to identity coreference. The public edition of CorefUD 1.0, which contains 13 datasets for 10 languages, was used as the source of training and evaluation data. The CoNLL score used in previous coreference-oriented shared tasks was used as the main evaluation metric. There were 8 coreference prediction systems submitted by 5 participating teams; in addition, there was a competitive Transformer-based baseline system provided by the organizers at the beginning of the shared task. The winner system outperformed the baseline by 12 percentage points (in terms of the CoNLL scores averaged across all datasets for individual languages).
CUNI systems for WMT21: Multilingual Low-Resource Translation for Indo-European Languages Shared Task
Sep 20, 2021
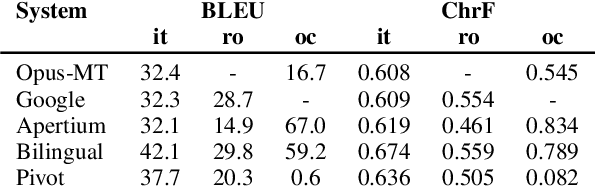
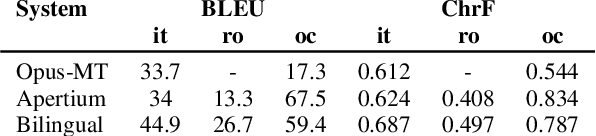

This paper describes Charles University submission for Multilingual Low-Resource Translation for Indo-European Languages shared task at WMT21. We competed in translation from Catalan into Romanian, Italian and Occitan. Our systems are based on shared multilingual model. We show that using joint model for multiple similar language pairs improves upon translation quality in each pair. We also demonstrate that chararacter-level bilingual models are competitive for very similar language pairs (Catalan-Occitan) but less so for more distant pairs. We also describe our experiments with multi-task learning, where aside from a textual translation, the models are also trained to perform grapheme-to-phoneme conversion.
CUNI systems for WMT21: Terminology translation Shared Task
Sep 20, 2021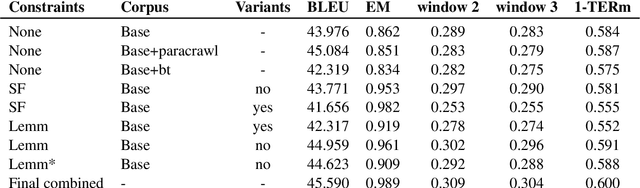

This paper describes Charles University submission for Terminology translation Shared Task at WMT21. The objective of this task is to design a system which translates certain terms based on a provided terminology database, while preserving high overall translation quality. We competed in English-French language pair. Our approach is based on providing the desired translations alongside the input sentence and training the model to use these provided terms. We lemmatize the terms both during the training and inference, to allow the model to learn how to produce correct surface forms of the words, when they differ from the forms provided in the terminology database. Our submission ranked second in Exact Match metric which evaluates the ability of the model to produce desired terms in the translation.
Backtranslation Feedback Improves User Confidence in MT, Not Quality
Apr 12, 2021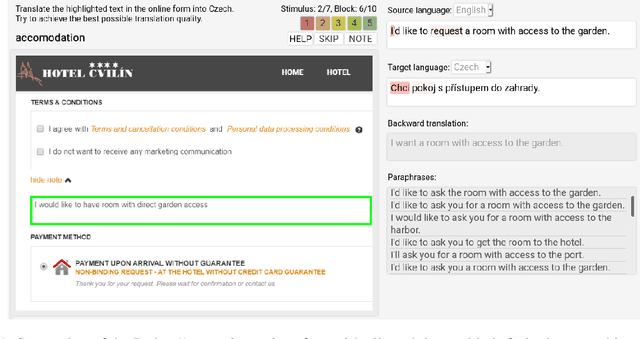
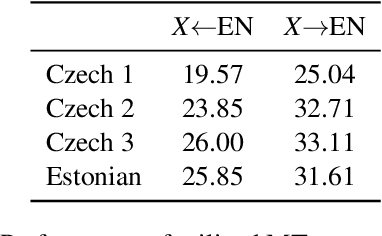
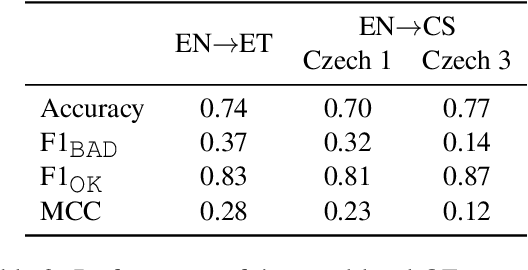
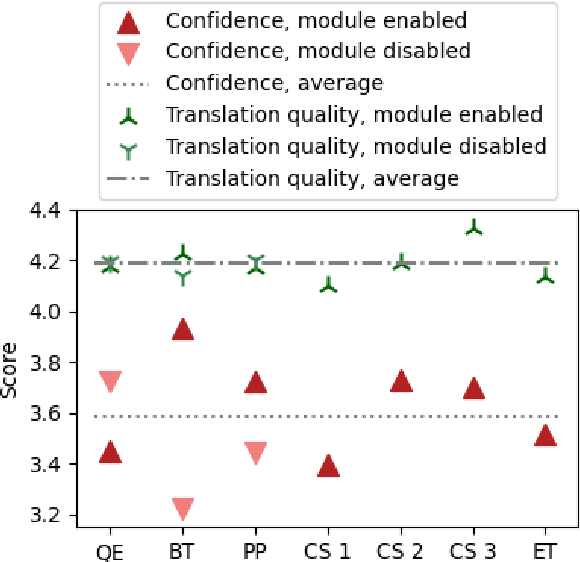
Translating text into a language unknown to the text's author, dubbed outbound translation, is a modern need for which the user experience has significant room for improvement, beyond the basic machine translation facility. We demonstrate this by showing three ways in which user confidence in the outbound translation, as well as its overall final quality, can be affected: backward translation, quality estimation (with alignment) and source paraphrasing. In this paper, we describe an experiment on outbound translation from English to Czech and Estonian. We examine the effects of each proposed feedback module and further focus on how the quality of machine translation systems influence these findings and the user perception of success. We show that backward translation feedback has a mixed effect on the whole process: it increases user confidence in the produced translation, but not the objective quality.
SAO WMT19 Test Suite: Machine Translation of Audit Reports
Sep 04, 2019


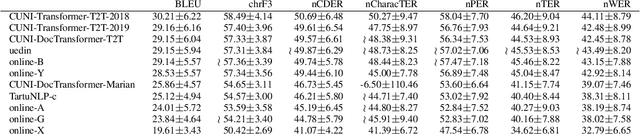
This paper describes a machine translation test set of documents from the auditing domain and its use as one of the "test suites" in the WMT19 News Translation Task for translation directions involving Czech, English and German. Our evaluation suggests that current MT systems optimized for the general news domain can perform quite well even in the particular domain of audit reports. The detailed manual evaluation however indicates that deep factual knowledge of the domain is necessary. For the naked eye of a non-expert, translations by many systems seem almost perfect and automatic MT evaluation with one reference is practically useless for considering these details. Furthermore, we show on a sample document from the domain of agreements that even the best systems completely fail in preserving the semantics of the agreement, namely the identity of the parties.
* WMT19 (http://www.statmt.org/wmt19/)