 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreaking Attacks vs. Content Safety Filters: How Far Are We in the LLM Safety Arms Race?
Dec 30, 2025As large language models (LLMs) are increasingly deployed, ensuring their safe use is paramount. Jailbreaking, adversarial prompts that bypass model alignment to trigger harmful outputs, present significant risks, with existing studies reporting high success rates in evading common LLMs. However, previous evaluations have focused solely on the models, neglecting the full deployment pipeline, which typically incorporates additional safety mechanisms like content moderation filters. To address this gap, we present the first systematic evaluation of jailbreak attacks targeting LLM safety alignment, assessing their success across the full inference pipeline, including both input and output filtering stages. Our findings yield two key insights: first, nearly all evaluated jailbreak techniques can be detected by at least one safety filter, suggesting that prior assessments may have overestimated the practical success of these attacks; second, while safety filters are effective in detection, there remains room to better balance recall and precision to further optimize protection and user experience. We highlight critical gaps and call for further refinement of detection accuracy and usability in LLM safety systems.
JADES: A Universal Framework for Jailbreak Assessment via Decompositional Scoring
Aug 28, 2025Accurately determining whether a jailbreak attempt has succeeded is a fundamental yet unresolved challenge. Existing evaluation methods rely on misaligned proxy indicators or naive holistic judgments. They frequently misinterpret model responses, leading to inconsistent and subjective assessments that misalign with human perception. To address this gap, we introduce JADES (Jailbreak Assessment via Decompositional Scoring), a universal jailbreak evaluation framework. Its key mechanism is to automatically decompose an input harmful question into a set of weighted sub-questions, score each sub-answer, and weight-aggregate the sub-scores into a final decision. JADES also incorporates an optional fact-checking module to strengthen the detection of hallucinations in jailbreak responses. We validate JADES on JailbreakQR, a newly introduced benchmark proposed in this work, consisting of 400 pairs of jailbreak prompts and responses, each meticulously annotated by humans. In a binary setting (success/failure), JADES achieves 98.5% agreement with human evaluators, outperforming strong baselines by over 9%. Re-evaluating five popular attacks on four LLMs reveals substantial overestimation (e.g., LAA's attack success rate on GPT-3.5-Turbo drops from 93% to 69%). Our results show that JADES could deliver accurate, consistent, and interpretable evaluations, providing a reliable basis for measuring future jailbreak attacks.
Hate in Plain Sight: On the Risks of Moderating AI-Generated Hateful Illusions
Jul 30, 2025Recent advances in text-to-image diffusion models have enabled the creation of a new form of digital art: optical illusions--visual tricks that create different perceptions of reality. However, adversaries may misuse such techniques to generate hateful illusions, which embed specific hate messages into harmless scenes and disseminate them across web communities. In this work, we take the first step toward investigating the risks of scalable hateful illusion generation and the potential for bypassing current content moderation models. Specifically, we generate 1,860 optical illusions using Stable Diffusion and ControlNet, conditioned on 62 hate messages. Of these, 1,571 are hateful illusions that successfully embed hate messages, either overtly or subtly, forming the Hateful Illusion dataset. Using this dataset, we evaluate the performance of six moderation classifiers and nine vision language models (VLMs) in identifying hateful illusions. Experimental results reveal significant vulnerabilities in existing moderation models: the detection accuracy falls below 0.245 for moderation classifiers and below 0.102 for VLMs. We further identify a critical limitation in their vision encoders, which mainly focus on surface-level image details while overlooking the secondary layer of information, i.e., hidden messages. To address this risk, we explore preliminary mitigation measures and identify the most effective approaches from the perspectives of image transformations and training-level strategies.
Excessive Reasoning Attack on Reasoning LLMs
Jun 17, 2025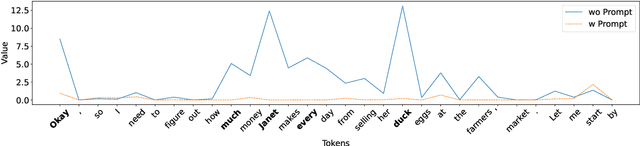
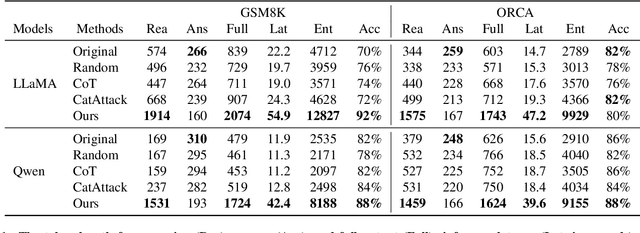
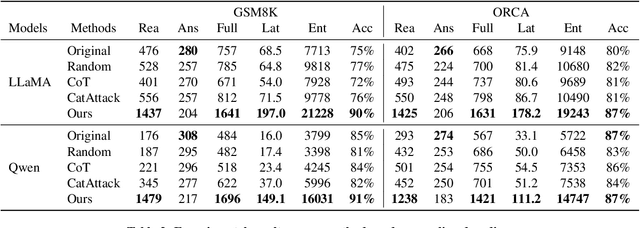
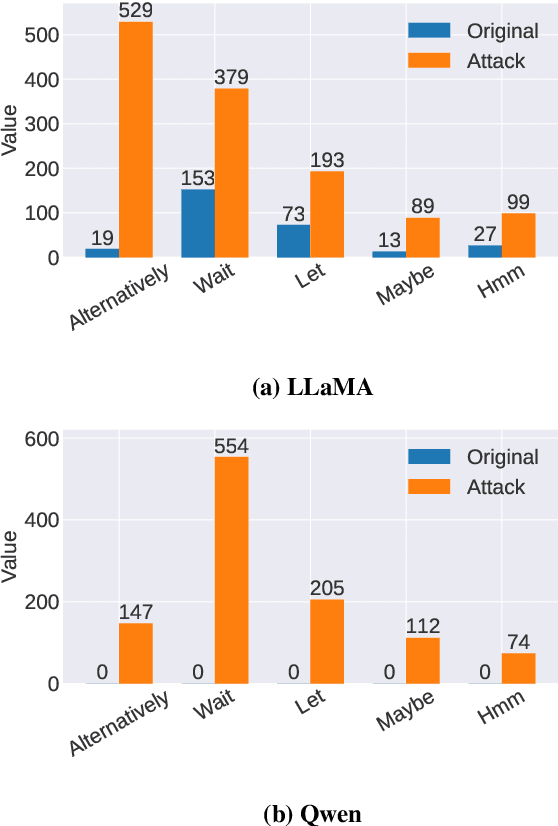
Recent reasoning large language models (LLMs), such as OpenAI o1 and DeepSeek-R1, exhibit strong performance on complex tasks through test-time inference scaling. However, prior studies have shown that these models often incur significant computational costs due to excessive reasoning, such as frequent switching between reasoning trajectories (e.g., underthinking) or redundant reasoning on simple questions (e.g., overthinking). In this work, we expose a novel threat: adversarial inputs can be crafted to exploit excessive reasoning behaviors and substantially increase computational overhead without compromising model utility. Therefore, we propose a novel loss framework consisting of three components: (1) Priority Cross-Entropy Loss, a modification of the standard cross-entropy objective that emphasizes key tokens by leveraging the autoregressive nature of LMs; (2) Excessive Reasoning Loss, which encourages the model to initiate additional reasoning paths during inference; and (3) Delayed Termination Loss, which is designed to extend the reasoning process and defer the generation of final outputs. We optimize and evaluate our attack for the GSM8K and ORCA datasets on DeepSeek-R1-Distill-LLaMA and DeepSeek-R1-Distill-Qwen. Empirical results demonstrate a 3x to 9x increase in reasoning length with comparable utility performance. Furthermore, our crafted adversarial inputs exhibit transferability, inducing computational overhead in o3-mini, o1-mini, DeepSeek-R1, and QWQ models.
SoK: Data Reconstruction Attacks Against Machine Learning Models: Definition, Metrics, and Benchmark
Jun 09, 2025Data reconstruction attacks, which aim to recover the training dataset of a target model with limited access, have gained increasing attention in recent years. However, there is currently no consensus on a formal definition of data reconstruction attacks or appropriate evaluation metrics for measuring their quality. This lack of rigorous definitions and universal metrics has hindered further advancement in this field. In this paper, we address this issue in the vision domain by proposing a unified attack taxonomy and formal definitions of data reconstruction attacks. We first propose a set of quantitative evaluation metrics that consider important criteria such as quantifiability, consistency, precision, and diversity. Additionally, we leverage large language models (LLMs) as a substitute for human judgment, enabling visual evaluation with an emphasis on high-quality reconstructions. Using our proposed taxonomy and metrics, we present a unified framework for systematically evaluating the strengths and limitations of existing attacks and establishing a benchmark for future research. Empirical results, primarily from a memorization perspective, not only validate the effectiveness of our metrics but also offer valuable insights for designing new attacks.
The Challenge of Identifying the Origin of Black-Box Large Language Models
Mar 06, 2025



The tremendous commercial potential of large language models (LLMs) has heightened concerns about their unauthorized use. Third parties can customize LLMs through fine-tuning and offer only black-box API access, effectively concealing unauthorized usage and complicating external auditing processes. This practice not only exacerbates unfair competition, but also violates licensing agreements. In response, identifying the origin of black-box LLMs is an intrinsic solution to this issue. In this paper, we first reveal the limitations of state-of-the-art passive and proactive identification methods with experiments on 30 LLMs and two real-world black-box APIs. Then, we propose the proactive technique, PlugAE, which optimizes adversarial token embeddings in a continuous space and proactively plugs them into the LLM for tracing and identification. The experiments show that PlugAE can achieve substantial improvement in identifying fine-tuned derivatives. We further advocate for legal frameworks and regulations to better address the challenges posed by the unauthorized use of LLMs.
Fairness and/or Privacy on Social Graphs
Mar 03, 2025Graph Neural Networks (GNNs) have shown remarkable success in various graph-based learning tasks. However, recent studies have raised concerns about fairness and privacy issues in GNNs, highlighting the potential for biased or discriminatory outcomes and the vulnerability of sensitive information. This paper presents a comprehensive investigation of fairness and privacy in GNNs, exploring the impact of various fairness-preserving measures on model performance. We conduct experiments across diverse datasets and evaluate the effectiveness of different fairness interventions. Our analysis considers the trade-offs between fairness, privacy, and accuracy, providing insights into the challenges and opportunities in achieving both fair and private graph learning. The results highlight the importance of carefully selecting and combining fairness-preserving measures based on the specific characteristics of the data and the desired fairness objectives. This study contributes to a deeper understanding of the complex interplay between fairness, privacy, and accuracy in GNNs, paving the way for the development of more robust and ethical graph learning models.
Captured by Captions: On Memorization and its Mitigation in CLIP Models
Feb 11, 2025Multi-modal models, such as CLIP, have demonstrated strong performance in aligning visual and textual representations, excelling in tasks like image retrieval and zero-shot classification. Despite this success, the mechanisms by which these models utilize training data, particularly the role of memorization, remain unclear. In uni-modal models, both supervised and self-supervised, memorization has been shown to be essential for generalization. However, it is not well understood how these findings would apply to CLIP, which incorporates elements from both supervised learning via captions that provide a supervisory signal similar to labels, and from self-supervised learning via the contrastive objective. To bridge this gap in understanding, we propose a formal definition of memorization in CLIP (CLIPMem) and use it to quantify memorization in CLIP models. Our results indicate that CLIP's memorization behavior falls between the supervised and self-supervised paradigms, with "mis-captioned" samples exhibiting highest levels of memorization. Additionally, we find that the text encoder contributes more to memorization than the image encoder, suggesting that mitigation strategies should focus on the text domain. Building on these insights, we propose multiple strategies to reduce memorization while at the same time improving utility--something that had not been shown before for traditional learning paradigms where reducing memorization typically results in utility decrease.
Synthetic Artifact Auditing: Tracing LLM-Generated Synthetic Data Usage in Downstream Applications
Feb 02, 2025Large language models (LLMs) have facilitated the generation of high-quality, cost-effective synthetic data for developing downstream models and conducting statistical analyses in various domains. However, the increased reliance on synthetic data may pose potential negative impacts. Numerous studies have demonstrated that LLM-generated synthetic data can perpetuate and even amplify societal biases and stereotypes, and produce erroneous outputs known as ``hallucinations'' that deviate from factual knowledge. In this paper, we aim to audit artifacts, such as classifiers, generators, or statistical plots, to identify those trained on or derived from synthetic data and raise user awareness, thereby reducing unexpected consequences and risks in downstream applications. To this end, we take the first step to introduce synthetic artifact auditing to assess whether a given artifact is derived from LLM-generated synthetic data. We then propose an auditing framework with three methods including metric-based auditing, tuning-based auditing, and classification-based auditing. These methods operate without requiring the artifact owner to disclose proprietary training details. We evaluate our auditing framework on three text classification tasks, two text summarization tasks, and two data visualization tasks across three training scenarios. Our evaluation demonstrates the effectiveness of all proposed auditing methods across all these tasks. For instance, black-box metric-based auditing can achieve an average accuracy of $0.868 \pm 0.071$ for auditing classifiers and $0.880 \pm 0.052$ for auditing generators using only 200 random queries across three scenarios. We hope our research will enhance model transparency and regulatory compliance, ensuring the ethical and responsible use of synthetic data.
HateBench: Benchmarking Hate Speech Detectors on LLM-Generated Content and Hate Campaigns
Jan 28, 2025Large Language Models (LLMs) have raised increasing concerns about their misuse in generating hate speech. Among all the efforts to address this issue, hate speech detectors play a crucial role. However, the effectiveness of different detectors against LLM-generated hate speech remains largely unknown. In this paper, we propose HateBench, a framework for benchmarking hate speech detectors on LLM-generated hate speech. We first construct a hate speech dataset of 7,838 samples generated by six widely-used LLMs covering 34 identity groups, with meticulous annotations by three labelers. We then assess the effectiveness of eight representative hate speech detectors on the LLM-generated dataset. Our results show that while detectors are generally effective in identifying LLM-generated hate speech, their performance degrades with newer versions of LLMs. We also reveal the potential of LLM-driven hate campaigns, a new threat that LLMs bring to the field of hate speech detection. By leveraging advanced techniques like adversarial attacks and model stealing attacks, the adversary can intentionally evade the detector and automate hate campaigns online. The most potent adversarial attack achieves an attack success rate of 0.966, and its attack efficiency can be further improved by $13-21\times$ through model stealing attacks with acceptable attack performance. We hope our study can serve as a call to action for the research community and platform moderators to fortify defenses against these emerging threats.