 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal and Near-Optimal Adaptive Vector Quantization
Feb 05, 2024



Quantization is a fundamental optimization for many machine-learning use cases, including compressing gradients, model weights and activations, and datasets. The most accurate form of quantization is \emph{adaptive}, where the error is minimized with respect to a given input, rather than optimizing for the worst case. However, optimal adaptive quantization methods are considered infeasible in terms of both their runtime and memory requirements. We revisit the Adaptive Vector Quantization (AVQ) problem and present algorithms that find optimal solutions with asymptotically improved time and space complexity. We also present an even faster near-optimal algorithm for large inputs. Our experiments show our algorithms may open the door to using AVQ more extensively in a variety of machine learning applications.
SkipPredict: When to Invest in Predictions for Scheduling
Feb 05, 2024



In light of recent work on scheduling with predicted job sizes, we consider the effect of the cost of predictions in queueing systems, removing the assumption in prior research that predictions are external to the system's resources and/or cost-free. In particular, we introduce a novel approach to utilizing predictions, SkipPredict, designed to address their inherent cost. Rather than uniformly applying predictions to all jobs, we propose a tailored approach that categorizes jobs based on their prediction requirements. To achieve this, we employ one-bit "cheap predictions" to classify jobs as either short or long. SkipPredict prioritizes predicted short jobs over long jobs, and for the latter, SkipPredict applies a second round of more detailed "expensive predictions" to approximate Shortest Remaining Processing Time for these jobs. Our analysis takes into account the cost of prediction. We examine the effect of this cost for two distinct models. In the external cost model, predictions are generated by some external method without impacting job service times but incur a cost. In the server time cost model, predictions themselves require server processing time, and are scheduled on the same server as the jobs.
THC: Accelerating Distributed Deep Learning Using Tensor Homomorphic Compression
Feb 16, 2023



Deep neural networks (DNNs) are the de-facto standard for essential use cases, such as image classification, computer vision, and natural language processing. As DNNs and datasets get larger, they require distributed training on increasingly larger clusters. A main bottleneck is then the resulting communication overhead where workers exchange model updates (i.e., gradients) on a per-round basis. To address this bottleneck and accelerate training, a widely-deployed approach is compression. However, previous deployments often apply bi-directional compression schemes by simply using a uni-directional gradient compression scheme in each direction. This results in significant computational overheads at the parameter server and increased compression error, leading to longer training and lower accuracy. We introduce Tensor Homomorphic Compression (THC), a novel bi-directional compression framework that enables the direct aggregation of compressed values while optimizing the bandwidth to accuracy tradeoff, thus eliminating the aforementioned overheads. Moreover, THC is compatible with in-network aggregation (INA), which allows for further acceleration. Evaluation over a testbed shows that THC improves time-to-accuracy in comparison to alternatives by up to 1.32x with a software PS and up to 1.51x using INA. Finally, we demonstrate that THC is scalable and tolerant for acceptable packet-loss rates.
Proteus: A Self-Designing Range Filter
Jun 30, 2022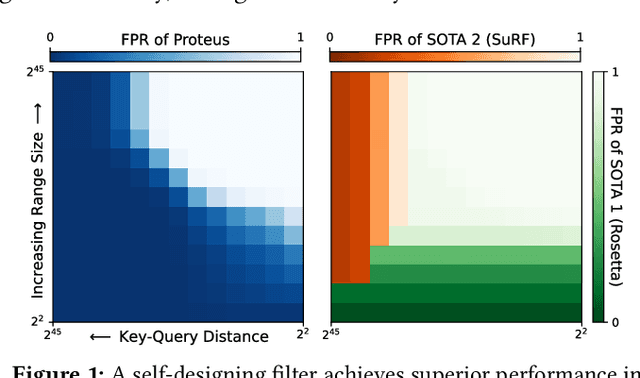

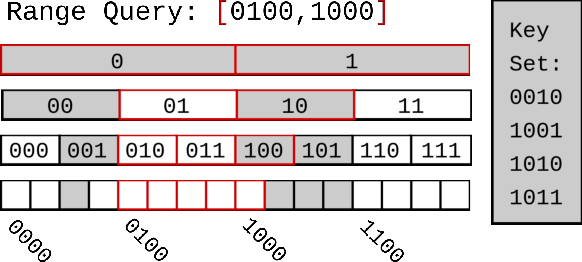
We introduce Proteus, a novel self-designing approximate range filter, which configures itself based on sampled data in order to optimize its false positive rate (FPR) for a given space requirement. Proteus unifies the probabilistic and deterministic design spaces of state-of-the-art range filters to achieve robust performance across a larger variety of use cases. At the core of Proteus lies our Contextual Prefix FPR (CPFPR) model - a formal framework for the FPR of prefix-based filters across their design spaces. We empirically demonstrate the accuracy of our model and Proteus' ability to optimize over both synthetic workloads and real-world datasets. We further evaluate Proteus in RocksDB and show that it is able to improve end-to-end performance by as much as 5.3x over more brittle state-of-the-art methods such as SuRF and Rosetta. Our experiments also indicate that the cost of modeling is not significant compared to the end-to-end performance gains and that Proteus is robust to workload shifts.
* 14 pages, 9 figures, originally published in the Proceedings of the 2022 International Conference on Management of Data (SIGMOD'22), ISBN: 9781450392495
QUIC-FL: Quick Unbiased Compression for Federated Learning
May 28, 2022
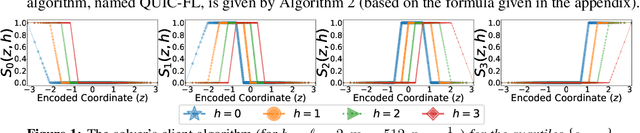
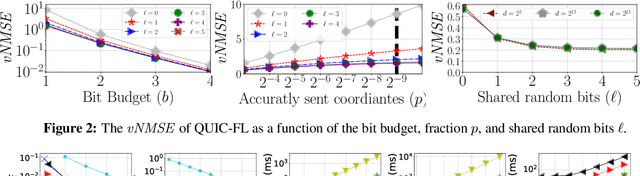
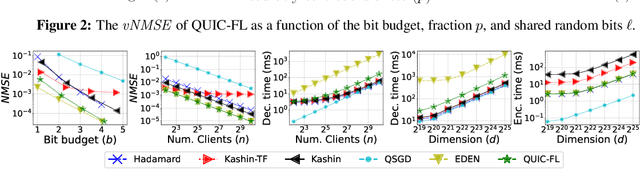
Distributed Mean Estimation (DME) is a fundamental building block in communication efficient federated learning. In DME, clients communicate their lossily compressed gradients to the parameter server, which estimates the average and updates the model. State of the art DME techniques apply either unbiased quantization methods, resulting in large estimation errors, or biased quantization methods, where unbiasing the result requires that the server decodes each gradient individually, which markedly slows the aggregation time. In this paper, we propose QUIC-FL, a DME algorithm that achieves the best of all worlds. QUIC-FL is unbiased, offers fast aggregation time, and is competitive with the most accurate (slow aggregation) DME techniques. To achieve this, we formalize the problem in a novel way that allows us to use standard solvers to design near-optimal unbiased quantization schemes.
Tabula: Efficiently Computing Nonlinear Activation Functions for Secure Neural Network Inference
Mar 05, 2022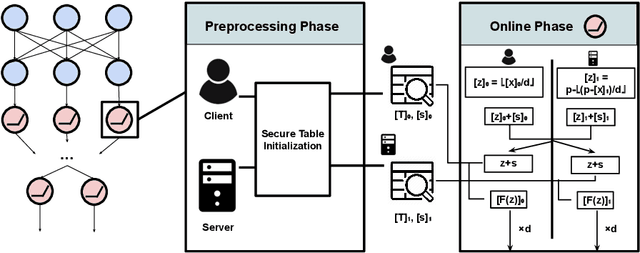

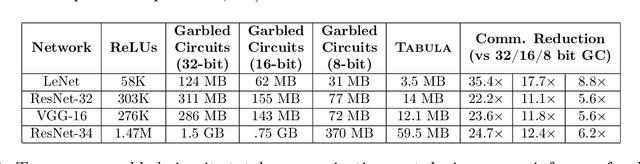
Multiparty computation approaches to secure neural network inference traditionally rely on garbled circuits for securely executing nonlinear activation functions. However, garbled circuits require excessive communication between server and client, impose significant storage overheads, and incur large runtime penalties. To eliminate these costs, we propose an alternative to garbled circuits: Tabula, an algorithm based on secure lookup tables. Tabula leverages neural networks' ability to be quantized and employs a secure lookup table approach to efficiently, securely, and accurately compute neural network nonlinear activation functions. Compared to garbled circuits with quantized inputs, when computing individual nonlinear functions, our experiments show Tabula uses between $35 \times$-$70 \times$ less communication, is over $100\times$ faster, and uses a comparable amount of storage. This leads to significant performance gains over garbled circuits with quantized inputs during secure inference on neural networks: Tabula reduces overall communication by up to $9 \times$ and achieves a speedup of up to $50 \times$, while imposing comparable storage costs.
Communication-Efficient Federated Learning via Robust Distributed Mean Estimation
Aug 19, 2021
Federated learning commonly relies on algorithms such as distributed (mini-batch) SGD, where multiple clients compute their gradients and send them to a central coordinator for averaging and updating the model. To optimize the transmission time and the scalability of the training process, clients often use lossy compression to reduce the message sizes. DRIVE is a recent state of the art algorithm that compresses gradients using one bit per coordinate (with some lower-order overhead). In this technical report, we generalize DRIVE to support any bandwidth constraint as well as extend it to support heterogeneous client resources and make it robust to packet loss.
Gradient Disaggregation: Breaking Privacy in Federated Learning by Reconstructing the User Participant Matrix
Jun 10, 2021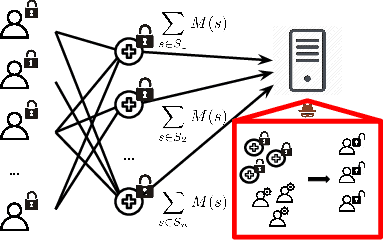
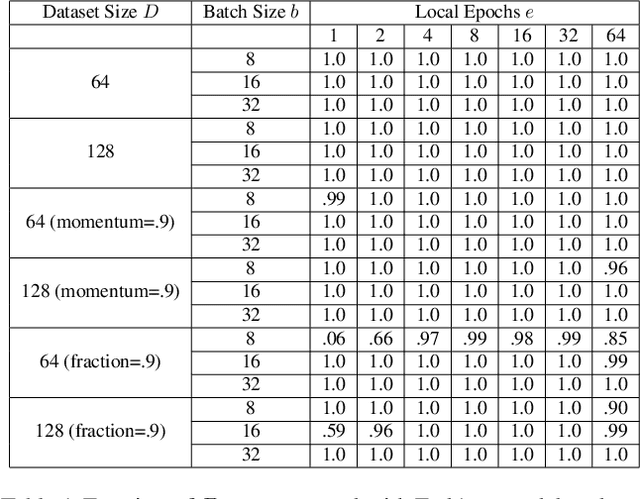
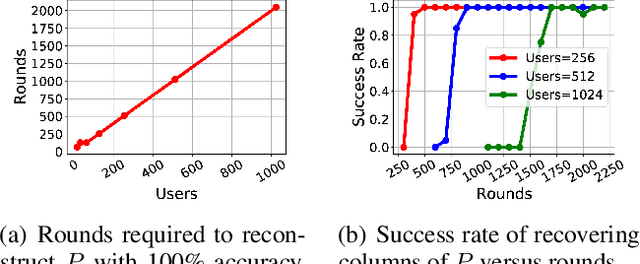

We show that aggregated model updates in federated learning may be insecure. An untrusted central server may disaggregate user updates from sums of updates across participants given repeated observations, enabling the server to recover privileged information about individual users' private training data via traditional gradient inference attacks. Our method revolves around reconstructing participant information (e.g: which rounds of training users participated in) from aggregated model updates by leveraging summary information from device analytics commonly used to monitor, debug, and manage federated learning systems. Our attack is parallelizable and we successfully disaggregate user updates on settings with up to thousands of participants. We quantitatively and qualitatively demonstrate significant improvements in the capability of various inference attacks on the disaggregated updates. Our attack enables the attribution of learned properties to individual users, violating anonymity, and shows that a determined central server may undermine the secure aggregation protocol to break individual users' data privacy in federated learning.
DRIVE: One-bit Distributed Mean Estimation
Jun 02, 2021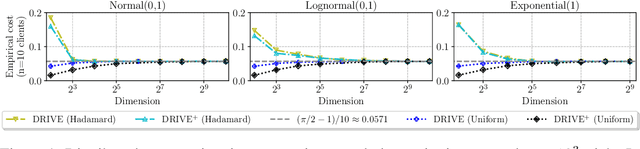
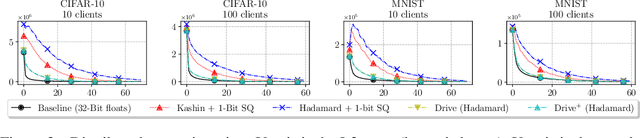
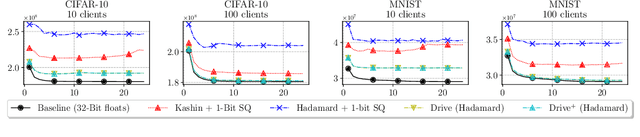
We consider the problem where $n$ clients transmit $d$-dimensional real-valued vectors using $d(1+o(1))$ bits each, in a manner that allows the receiver to approximately reconstruct their mean. Such compression problems naturally arise in distributed and federated learning. We provide novel mathematical results and derive computationally efficient algorithms that are more accurate than previous compression techniques. We evaluate our methods on a collection of distributed and federated learning tasks, using a variety of datasets, and show a consistent improvement over the state of the art.
How to send a real number using a single bit
Oct 08, 2020
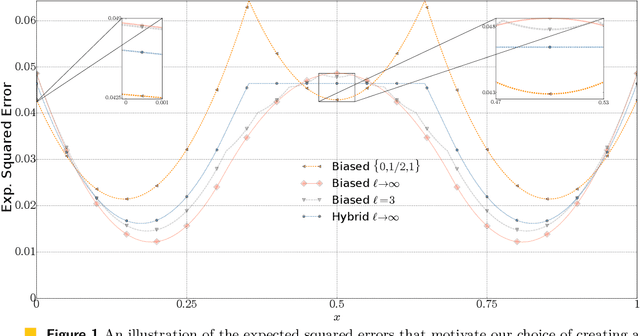
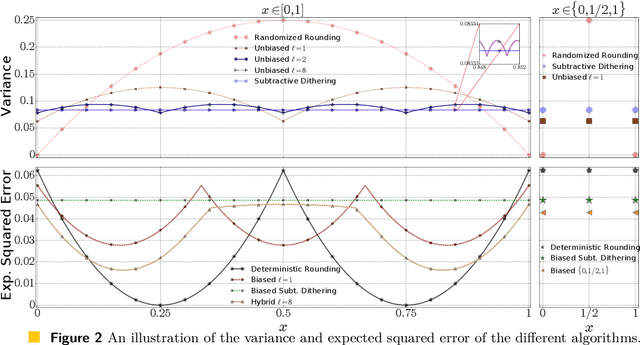
We consider the fundamental problem of communicating an estimate of a real number $x\in[0,1]$ using a single bit. A sender that knows $x$ chooses a value $X\in\set{0,1}$ to transmit. In turn, a receiver estimates $x$ based on the value of $X$. We consider both the biased and unbiased estimation problems and aim to minimize the cost. For the biased case, the cost is the worst-case (over the choice of $x$) expected squared error, which coincides with the variance if the algorithm is required to be unbiased. We first overview common biased and unbiased estimation approaches and prove their optimality when no shared randomness is allowed. We then show how a small amount of shared randomness, which can be as low as a single bit, reduces the cost in both cases. Specifically, we derive lower bounds on the cost attainable by any algorithm with unrestricted use of shared randomness and propose near-optimal solutions that use a small number of shared random bits. Finally, we discuss open problems and future directions.