 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantizing With Randomized Hadamard Transforms: Efficient Heuristic Now Proven
May 07, 2026Uniform random rotations (URRs) are a common preprocessing step in modern quantization approaches used for gradient compression, inference acceleration, KV-cache compression, model weight quantization, and approximate nearest-neighbor search in vector databases. In practice, URRs are often replaced by randomized Hadamard transforms (RHTs), which preserve orthogonality while admitting fast implementations. The remaining issue is the performance for worst-case inputs. With a URR, each coordinate is individually distributed as a shifted beta distribution, which converges to a Gaussian distribution in high dimensions. Generally, one RHT is not suitable in the worst case, as individual coordinates can be far from these distributions. We show that after composing two RHTs on any $d$-sized input vector, the marginal distribution of every fixed coordinate of the normalized rotated vector is within $O(d^{-1/2})$ of a standard Gaussian both in Kolmogorov distance and in $1$-Wasserstein distance. We then plug these bounds into the analyses of modern compression schemes, namely DRIVE and QUIC-FL, and show that two RHTs achieve performance that asymptotically matches URRs. However, we show that two RHTs may not be sufficient for Vector Quantization (VQ), which often requires weak correlation across fixed-size blocks of coordinates (as opposed to only marginal distribution convergence for single coordinates). We prove that a composition of three RHTs leads to decaying coordinate covariance. This ensures that any fixed, bounded, multi-dimensional VQ codebook optimized for URRs has the same expected error when using three RHTs, up to an additive term that vanishes with the dimension. Finally, because practical inputs are rarely adversarial, we propose a linear-time ${O}(d)$ check on the input's moments to dynamically adapt the number of RHTs used at runtime to improve performance.
A Note on TurboQuant and the Earlier DRIVE/EDEN Line of Work
Apr 20, 2026This note clarifies the relationship between the recent TurboQuant work and the earlier DRIVE (NeurIPS 2021) and EDEN (ICML 2022) schemes. DRIVE is a 1-bit quantizer that EDEN extended to any $b>0$ bits per coordinate; we refer to them collectively as EDEN. First, TurboQuant$_{\text{mse}}$ is a special case of EDEN obtained by fixing EDEN's scalar scale parameter to $S=1$. EDEN supports both biased and unbiased quantization, each optimized by a different $S$ (chosen via methods described in the EDEN works). The fixed choice $S=1$ used by TurboQuant is generally suboptimal, although the optimal $S$ for biased EDEN converges to $1$ as the dimension grows; accordingly TurboQuant$_{\text{mse}}$ approaches EDEN's behavior for large $d$. Second, TurboQuant$_{\text{prod}}$ combines a biased $(b-1)$-bit EDEN step with an unbiased 1-bit QJL quantization of the residual. It is suboptimal in three ways: (1) its $(b-1)$-bit step uses the suboptimal $S=1$; (2) its 1-bit unbiased residual quantization has worse MSE than (unbiased) 1-bit EDEN; (3) chaining a biased $(b-1)$-bit step with a 1-bit unbiased residual step is inferior to unbiasedly quantizing the input directly with $b$-bit EDEN. Third, some of the analysis in the TurboQuant work mirrors that of the EDEN works: both exploit the connection between random rotations and the shifted Beta distribution, use the Lloyd-Max algorithm, and note that Randomized Hadamard Transforms can replace uniform random rotations. Experiments support these claims: biased EDEN (with optimized $S$) is more accurate than TurboQuant$_{\text{mse}}$, and unbiased EDEN is markedly more accurate than TurboQuant$_{\text{prod}}$, often by more than a bit (e.g., 2-bit EDEN beats 3-bit TurboQuant$_{\text{prod}}$). We also repeat all accuracy experiments from the TurboQuant paper, showing that EDEN outperforms it in every setup we have tried.
Optimal and Near-Optimal Adaptive Vector Quantization
Feb 05, 2024



Quantization is a fundamental optimization for many machine-learning use cases, including compressing gradients, model weights and activations, and datasets. The most accurate form of quantization is \emph{adaptive}, where the error is minimized with respect to a given input, rather than optimizing for the worst case. However, optimal adaptive quantization methods are considered infeasible in terms of both their runtime and memory requirements. We revisit the Adaptive Vector Quantization (AVQ) problem and present algorithms that find optimal solutions with asymptotically improved time and space complexity. We also present an even faster near-optimal algorithm for large inputs. Our experiments show our algorithms may open the door to using AVQ more extensively in a variety of machine learning applications.
How to send a real number using a single bit
Oct 08, 2020
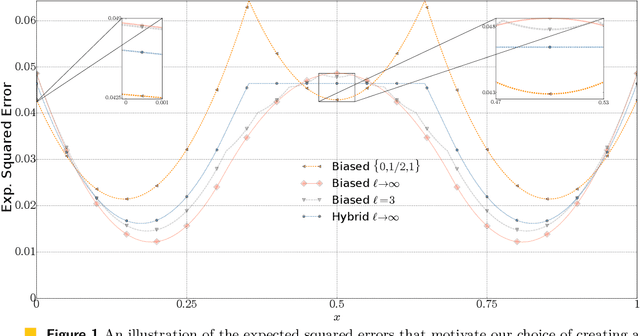
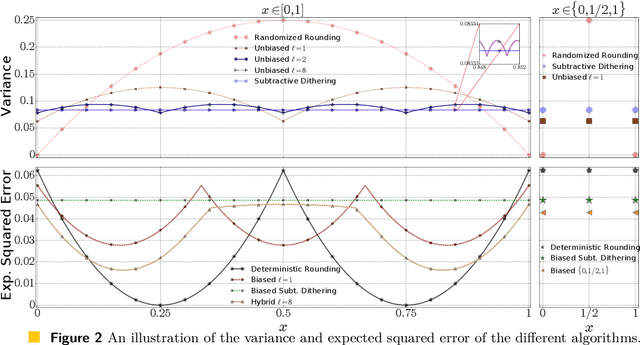
We consider the fundamental problem of communicating an estimate of a real number $x\in[0,1]$ using a single bit. A sender that knows $x$ chooses a value $X\in\set{0,1}$ to transmit. In turn, a receiver estimates $x$ based on the value of $X$. We consider both the biased and unbiased estimation problems and aim to minimize the cost. For the biased case, the cost is the worst-case (over the choice of $x$) expected squared error, which coincides with the variance if the algorithm is required to be unbiased. We first overview common biased and unbiased estimation approaches and prove their optimality when no shared randomness is allowed. We then show how a small amount of shared randomness, which can be as low as a single bit, reduces the cost in both cases. Specifically, we derive lower bounds on the cost attainable by any algorithm with unrestricted use of shared randomness and propose near-optimal solutions that use a small number of shared random bits. Finally, we discuss open problems and future directions.