 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantizing With Randomized Hadamard Transforms: Efficient Heuristic Now Proven
May 07, 2026Uniform random rotations (URRs) are a common preprocessing step in modern quantization approaches used for gradient compression, inference acceleration, KV-cache compression, model weight quantization, and approximate nearest-neighbor search in vector databases. In practice, URRs are often replaced by randomized Hadamard transforms (RHTs), which preserve orthogonality while admitting fast implementations. The remaining issue is the performance for worst-case inputs. With a URR, each coordinate is individually distributed as a shifted beta distribution, which converges to a Gaussian distribution in high dimensions. Generally, one RHT is not suitable in the worst case, as individual coordinates can be far from these distributions. We show that after composing two RHTs on any $d$-sized input vector, the marginal distribution of every fixed coordinate of the normalized rotated vector is within $O(d^{-1/2})$ of a standard Gaussian both in Kolmogorov distance and in $1$-Wasserstein distance. We then plug these bounds into the analyses of modern compression schemes, namely DRIVE and QUIC-FL, and show that two RHTs achieve performance that asymptotically matches URRs. However, we show that two RHTs may not be sufficient for Vector Quantization (VQ), which often requires weak correlation across fixed-size blocks of coordinates (as opposed to only marginal distribution convergence for single coordinates). We prove that a composition of three RHTs leads to decaying coordinate covariance. This ensures that any fixed, bounded, multi-dimensional VQ codebook optimized for URRs has the same expected error when using three RHTs, up to an additive term that vanishes with the dimension. Finally, because practical inputs are rarely adversarial, we propose a linear-time ${O}(d)$ check on the input's moments to dynamically adapt the number of RHTs used at runtime to improve performance.
A Note on TurboQuant and the Earlier DRIVE/EDEN Line of Work
Apr 20, 2026This note clarifies the relationship between the recent TurboQuant work and the earlier DRIVE (NeurIPS 2021) and EDEN (ICML 2022) schemes. DRIVE is a 1-bit quantizer that EDEN extended to any $b>0$ bits per coordinate; we refer to them collectively as EDEN. First, TurboQuant$_{\text{mse}}$ is a special case of EDEN obtained by fixing EDEN's scalar scale parameter to $S=1$. EDEN supports both biased and unbiased quantization, each optimized by a different $S$ (chosen via methods described in the EDEN works). The fixed choice $S=1$ used by TurboQuant is generally suboptimal, although the optimal $S$ for biased EDEN converges to $1$ as the dimension grows; accordingly TurboQuant$_{\text{mse}}$ approaches EDEN's behavior for large $d$. Second, TurboQuant$_{\text{prod}}$ combines a biased $(b-1)$-bit EDEN step with an unbiased 1-bit QJL quantization of the residual. It is suboptimal in three ways: (1) its $(b-1)$-bit step uses the suboptimal $S=1$; (2) its 1-bit unbiased residual quantization has worse MSE than (unbiased) 1-bit EDEN; (3) chaining a biased $(b-1)$-bit step with a 1-bit unbiased residual step is inferior to unbiasedly quantizing the input directly with $b$-bit EDEN. Third, some of the analysis in the TurboQuant work mirrors that of the EDEN works: both exploit the connection between random rotations and the shifted Beta distribution, use the Lloyd-Max algorithm, and note that Randomized Hadamard Transforms can replace uniform random rotations. Experiments support these claims: biased EDEN (with optimized $S$) is more accurate than TurboQuant$_{\text{mse}}$, and unbiased EDEN is markedly more accurate than TurboQuant$_{\text{prod}}$, often by more than a bit (e.g., 2-bit EDEN beats 3-bit TurboQuant$_{\text{prod}}$). We also repeat all accuracy experiments from the TurboQuant paper, showing that EDEN outperforms it in every setup we have tried.
DynamiQ: Accelerating Gradient Synchronization using Compressed Multi-hop All-reduce
Feb 09, 2026Multi-hop all-reduce is the de facto backbone of large model training. As the training scale increases, the network often becomes a bottleneck, motivating reducing the volume of transmitted data. Accordingly, recent systems demonstrated significant acceleration of the training process using gradient quantization. However, these systems are not optimized for multi-hop aggregation, where entries are partially summed multiple times along their aggregation topology. This paper presents DynamiQ, a quantization framework that bridges the gap between quantization best practices and multi-hop aggregation. DynamiQ introduces novel techniques to better represent partial sums, co-designed with a decompress-accumulate-recompress fused kernel to facilitate fast execution. We extended PyTorch DDP to support DynamiQ over NCCL P2P, and across different LLMs, tasks, and scales, we demonstrate consistent improvement of up to 34.2% over the best among state-of-the-art methods such as Omni-Reduce, THC, and emerging standards such as MXFP4, MXFP6, and MXFP8. Further, DynamiQ is the only evaluated method that consistently reaches near-baseline accuracy (e.g., 99.9% of the BF16 baseline) and does so while significantly accelerating the training.
HACK: Homomorphic Acceleration via Compression of the Key-Value Cache for Disaggregated LLM Inference
Feb 05, 2025



Disaggregated Large Language Model (LLM) inference has gained popularity as it separates the computation-intensive prefill stage from the memory-intensive decode stage, avoiding the prefill-decode interference and improving resource utilization. However, transmitting Key-Value (KV) data between the two stages can be a bottleneck, especially for long prompts. Additionally, the computation time overhead for prefill and decode is key for optimizing Job Completion Time (JCT), and KV data size can become prohibitive for long prompts and sequences. Existing KV quantization methods can alleviate the transmission bottleneck and reduce memory requirements, but they introduce significant dequantization overhead, exacerbating the computation time. We propose Homomorphic Acceleration via Compression of the KV cache (HACK) for disaggregated LLM inference. HACK eliminates the heavy KV dequantization step, and directly performs computations on quantized KV data to approximate and reduce the cost of the expensive matrix-multiplication step. Extensive trace-driven experiments show that HACK reduces JCT by up to 70.9% compared to disaggregated LLM inference baseline and by up to 52.3% compared to state-of-the-art KV quantization methods.
Lucy: Think and Reason to Solve Text-to-SQL
Jul 06, 2024



Large Language Models (LLMs) have made significant progress in assisting users to query databases in natural language. While LLM-based techniques provide state-of-the-art results on many standard benchmarks, their performance significantly drops when applied to large enterprise databases. The reason is that these databases have a large number of tables with complex relationships that are challenging for LLMs to reason about. We analyze challenges that LLMs face in these settings and propose a new solution that combines the power of LLMs in understanding questions with automated reasoning techniques to handle complex database constraints. Based on these ideas, we have developed a new framework that outperforms state-of-the-art techniques in zero-shot text-to-SQL on complex benchmarks
Beyond Throughput and Compression Ratios: Towards High End-to-end Utility of Gradient Compression
Jul 01, 2024



Gradient aggregation has long been identified as a major bottleneck in today's large-scale distributed machine learning training systems. One promising solution to mitigate such bottlenecks is gradient compression, directly reducing communicated gradient data volume. However, in practice, many gradient compression schemes do not achieve acceleration of the training process while also preserving accuracy. In this work, we identify several common issues in previous gradient compression systems and evaluation methods. These issues include excessive computational overheads; incompatibility with all-reduce; and inappropriate evaluation metrics, such as not using an end-to-end metric or using a 32-bit baseline instead of a 16-bit baseline. We propose several general design and evaluation techniques to address these issues and provide guidelines for future work. Our preliminary evaluation shows that our techniques enhance the system's performance and provide a clearer understanding of the end-to-end utility of gradient compression methods.
Optimal and Near-Optimal Adaptive Vector Quantization
Feb 05, 2024



Quantization is a fundamental optimization for many machine-learning use cases, including compressing gradients, model weights and activations, and datasets. The most accurate form of quantization is \emph{adaptive}, where the error is minimized with respect to a given input, rather than optimizing for the worst case. However, optimal adaptive quantization methods are considered infeasible in terms of both their runtime and memory requirements. We revisit the Adaptive Vector Quantization (AVQ) problem and present algorithms that find optimal solutions with asymptotically improved time and space complexity. We also present an even faster near-optimal algorithm for large inputs. Our experiments show our algorithms may open the door to using AVQ more extensively in a variety of machine learning applications.
THC: Accelerating Distributed Deep Learning Using Tensor Homomorphic Compression
Feb 16, 2023



Deep neural networks (DNNs) are the de-facto standard for essential use cases, such as image classification, computer vision, and natural language processing. As DNNs and datasets get larger, they require distributed training on increasingly larger clusters. A main bottleneck is then the resulting communication overhead where workers exchange model updates (i.e., gradients) on a per-round basis. To address this bottleneck and accelerate training, a widely-deployed approach is compression. However, previous deployments often apply bi-directional compression schemes by simply using a uni-directional gradient compression scheme in each direction. This results in significant computational overheads at the parameter server and increased compression error, leading to longer training and lower accuracy. We introduce Tensor Homomorphic Compression (THC), a novel bi-directional compression framework that enables the direct aggregation of compressed values while optimizing the bandwidth to accuracy tradeoff, thus eliminating the aforementioned overheads. Moreover, THC is compatible with in-network aggregation (INA), which allows for further acceleration. Evaluation over a testbed shows that THC improves time-to-accuracy in comparison to alternatives by up to 1.32x with a software PS and up to 1.51x using INA. Finally, we demonstrate that THC is scalable and tolerant for acceptable packet-loss rates.
$\texttt{DoCoFL}$: Downlink Compression for Cross-Device Federated Learning
Feb 01, 2023



Many compression techniques have been proposed to reduce the communication overhead of Federated Learning training procedures. However, these are typically designed for compressing model updates, which are expected to decay throughout training. As a result, such methods are inapplicable to downlink (i.e., from the parameter server to clients) compression in the cross-device setting, where heterogeneous clients $\textit{may appear only once}$ during training and thus must download the model parameters. In this paper, we propose a new framework ($\texttt{DoCoFL}$) for downlink compression in the cross-device federated learning setting. Importantly, $\texttt{DoCoFL}$ can be seamlessly combined with many uplink compression schemes, rendering it suitable for bi-directional compression. Through extensive evaluation, we demonstrate that $\texttt{DoCoFL}$ offers significant bi-directional bandwidth reduction while achieving competitive accuracy to that of $\texttt{FedAvg}$ without compression.
ScionFL: Secure Quantized Aggregation for Federated Learning
Oct 13, 2022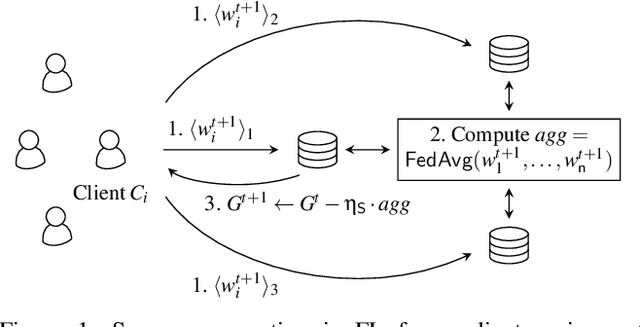
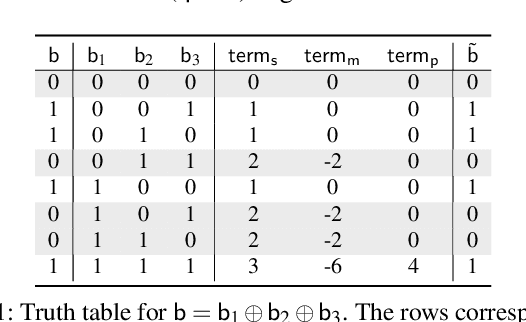

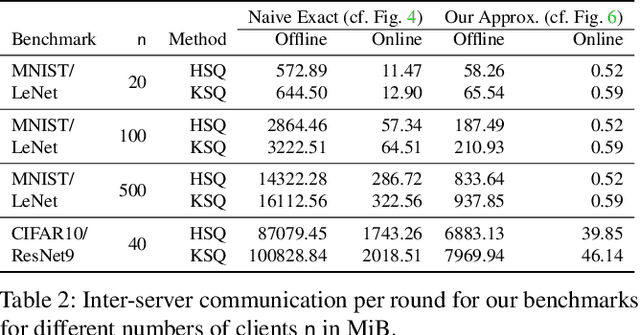
Privacy concerns in federated learning (FL) are commonly addressed with secure aggregation schemes that prevent a central party from observing plaintext client updates. However, most such schemes neglect orthogonal FL research that aims at reducing communication between clients and the aggregator and is instrumental in facilitating cross-device FL with thousands and even millions of (mobile) participants. In particular, quantization techniques can typically reduce client-server communication by a factor of 32x. In this paper, we unite both research directions by introducing an efficient secure aggregation framework based on outsourced multi-party computation (MPC) that supports any linear quantization scheme. Specifically, we design a novel approximate version of an MPC-based secure aggregation protocol with support for multiple stochastic quantization schemes, including ones that utilize the randomized Hadamard transform and Kashin's representation. In our empirical performance evaluation, we show that with no additional overhead for clients and moderate inter-server communication, we achieve similar training accuracy as insecure schemes for standard FL benchmarks. Beyond this, we present an efficient extension to our secure quantized aggregation framework that effectively defends against state-of-the-art untargeted poisoning attacks.