 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Latent Attention Within Neural Networks
Dec 30, 2017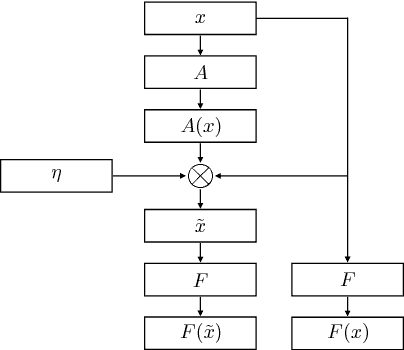

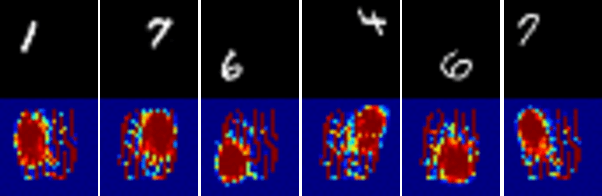

Deep neural networks are able to solve tasks across a variety of domains and modalities of data. Despite many empirical successes, we lack the ability to clearly understand and interpret the learned internal mechanisms that contribute to such effective behaviors or, more critically, failure modes. In this work, we present a general method for visualizing an arbitrary neural network's inner mechanisms and their power and limitations. Our dataset-centric method produces visualizations of how a trained network attends to components of its inputs. The computed "attention masks" support improved interpretability by highlighting which input attributes are critical in determining output. We demonstrate the effectiveness of our framework on a variety of deep neural network architectures in domains from computer vision, natural language processing, and reinforcement learning. The primary contribution of our approach is an interpretable visualization of attention that provides unique insights into the network's underlying decision-making process irrespective of the data modality.
Learning Approximate Stochastic Transition Models
Oct 26, 2017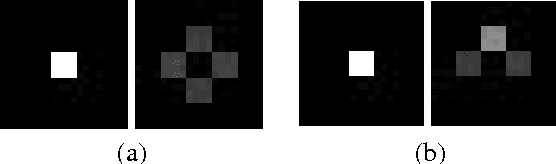
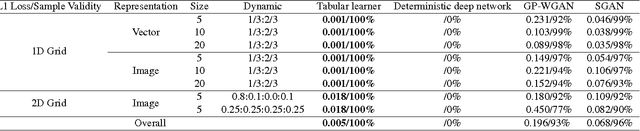


We examine the problem of learning mappings from state to state, suitable for use in a model-based reinforcement-learning setting, that simultaneously generalize to novel states and can capture stochastic transitions. We show that currently popular generative adversarial networks struggle to learn these stochastic transition models but a modification to their loss functions results in a powerful learning algorithm for this class of problems.
Summable Reparameterizations of Wasserstein Critics in the One-Dimensional Setting
Sep 19, 2017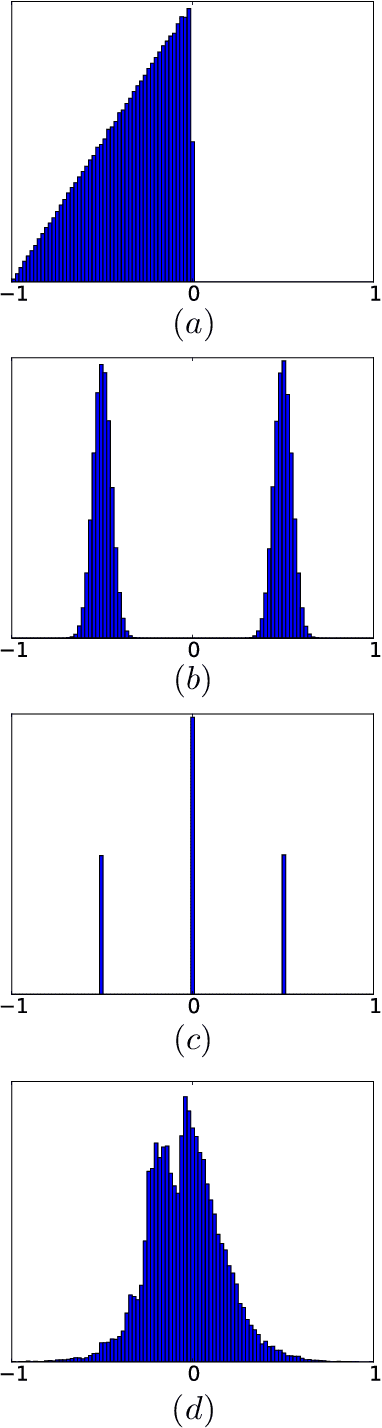
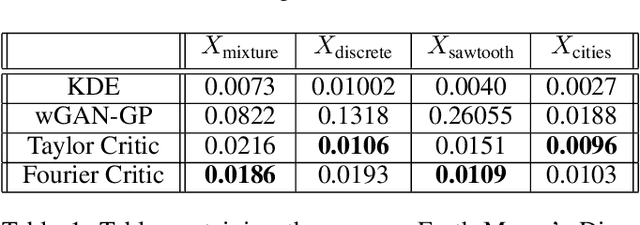
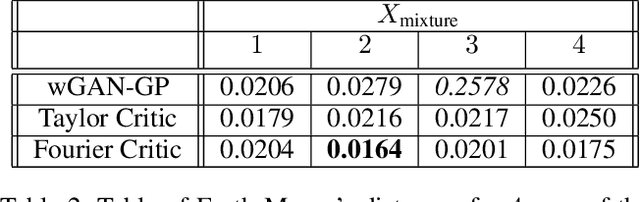
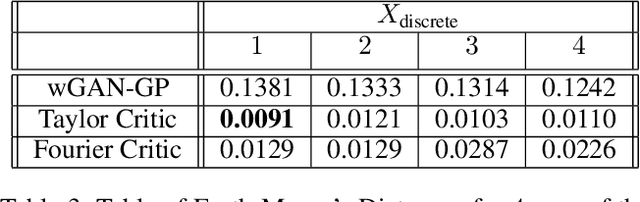
Generative adversarial networks (GANs) are an exciting alternative to algorithms for solving density estimation problems---using data to assess how likely samples are to be drawn from the same distribution. Instead of explicitly computing these probabilities, GANs learn a generator that can match the given probabilistic source. This paper looks particularly at this matching capability in the context of problems with one-dimensional outputs. We identify a class of function decompositions with properties that make them well suited to the critic role in a leading approach to GANs known as Wasserstein GANs. We show that Taylor and Fourier series decompositions belong to our class, provide examples of these critics outperforming standard GAN approaches, and suggest how they can be scaled to higher dimensional problems in the future.
Advantages and Limitations of using Successor Features for Transfer in Reinforcement Learning
Jul 31, 2017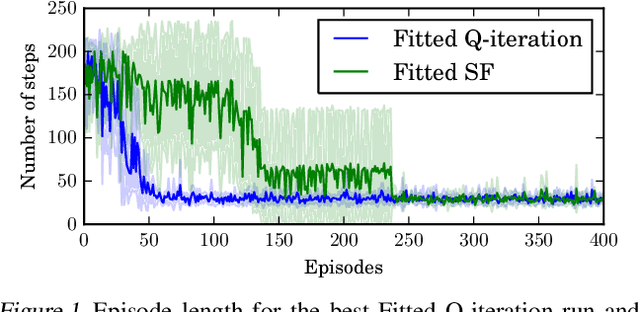
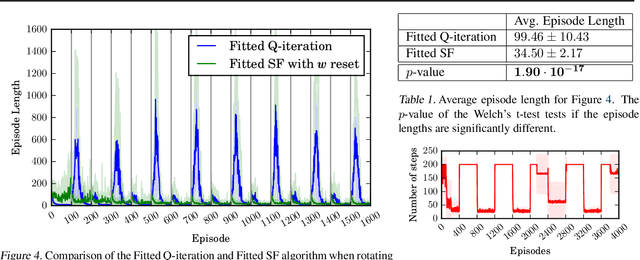
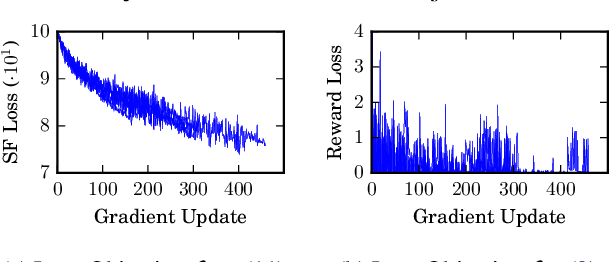
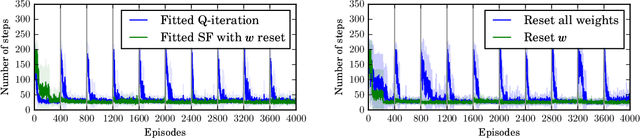
One question central to Reinforcement Learning is how to learn a feature representation that supports algorithm scaling and re-use of learned information from different tasks. Successor Features approach this problem by learning a feature representation that satisfies a temporal constraint. We present an implementation of an approach that decouples the feature representation from the reward function, making it suitable for transferring knowledge between domains. We then assess the advantages and limitations of using Successor Features for transfer.
An Alternative Softmax Operator for Reinforcement Learning
Jun 14, 2017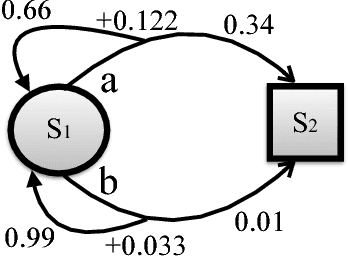
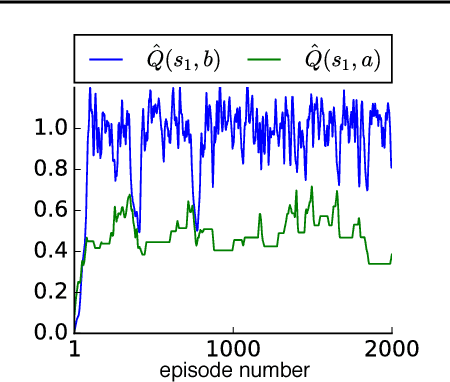
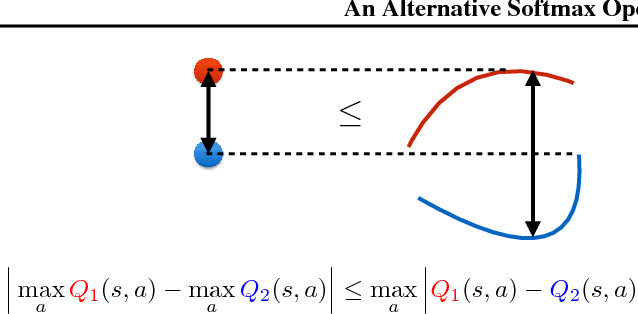
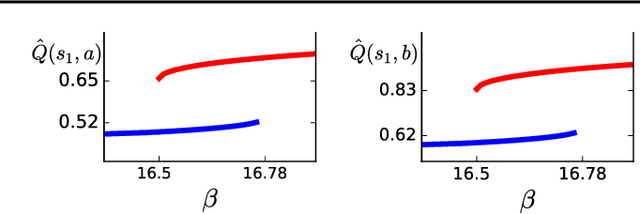
A softmax operator applied to a set of values acts somewhat like the maximization function and somewhat like an average. In sequential decision making, softmax is often used in settings where it is necessary to maximize utility but also to hedge against problems that arise from putting all of one's weight behind a single maximum utility decision. The Boltzmann softmax operator is the most commonly used softmax operator in this setting, but we show that this operator is prone to misbehavior. In this work, we study a differentiable softmax operator that, among other properties, is a non-expansion ensuring a convergent behavior in learning and planning. We introduce a variant of SARSA algorithm that, by utilizing the new operator, computes a Boltzmann policy with a state-dependent temperature parameter. We show that the algorithm is convergent and that it performs favorably in practice.
Environment-Independent Task Specifications via GLTL
Apr 14, 2017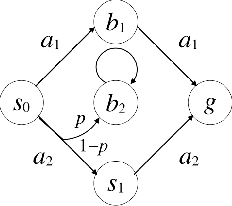
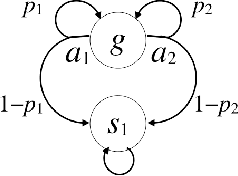
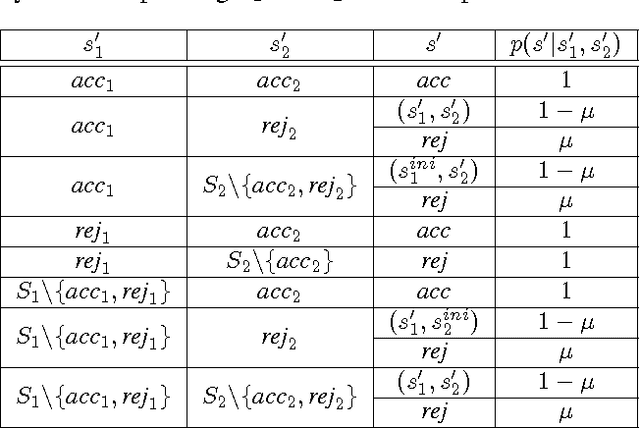
We propose a new task-specification language for Markov decision processes that is designed to be an improvement over reward functions by being environment independent. The language is a variant of Linear Temporal Logic (LTL) that is extended to probabilistic specifications in a way that permits approximations to be learned in finite time. We provide several small environments that demonstrate the advantages of our geometric LTL (GLTL) language and illustrate how it can be used to specify standard reinforcement-learning tasks straightforwardly.
Interactive Learning from Policy-Dependent Human Feedback
Jan 21, 2017
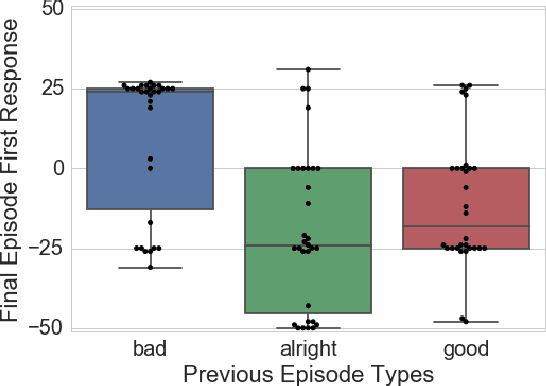
For agents and robots to become more useful, they must be able to quickly learn from non-technical users. This paper investigates the problem of interactively learning behaviors communicated by a human teacher using positive and negative feedback. Much previous work on this problem has made the assumption that people provide feedback for decisions that is dependent on the behavior they are teaching and is independent from the learner's current policy. We present empirical results that show this assumption to be false---whether human trainers give a positive or negative feedback for a decision is influenced by the learner's current policy. We argue that policy-dependent feedback, in addition to being commonplace, enables useful training strategies from which agents should benefit. Based on this insight, we introduce Convergent Actor-Critic by Humans (COACH), an algorithm for learning from policy-dependent feedback that converges to a local optimum. Finally, we demonstrate that COACH can successfully learn multiple behaviors on a physical robot, even with noisy image features.
Near Optimal Behavior via Approximate State Abstraction
Jan 15, 2017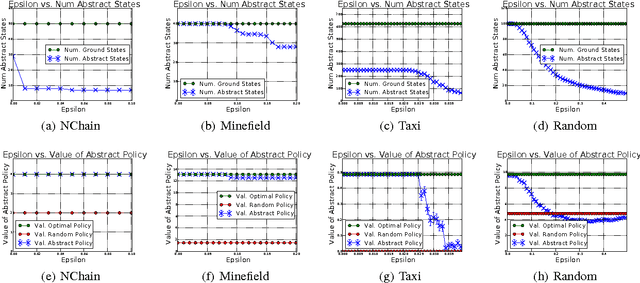
The combinatorial explosion that plagues planning and reinforcement learning (RL) algorithms can be moderated using state abstraction. Prohibitively large task representations can be condensed such that essential information is preserved, and consequently, solutions are tractably computable. However, exact abstractions, which treat only fully-identical situations as equivalent, fail to present opportunities for abstraction in environments where no two situations are exactly alike. In this work, we investigate approximate state abstractions, which treat nearly-identical situations as equivalent. We present theoretical guarantees of the quality of behaviors derived from four types of approximate abstractions. Additionally, we empirically demonstrate that approximate abstractions lead to reduction in task complexity and bounded loss of optimality of behavior in a variety of environments.
Graphical Models for Game Theory
Mar 08, 2015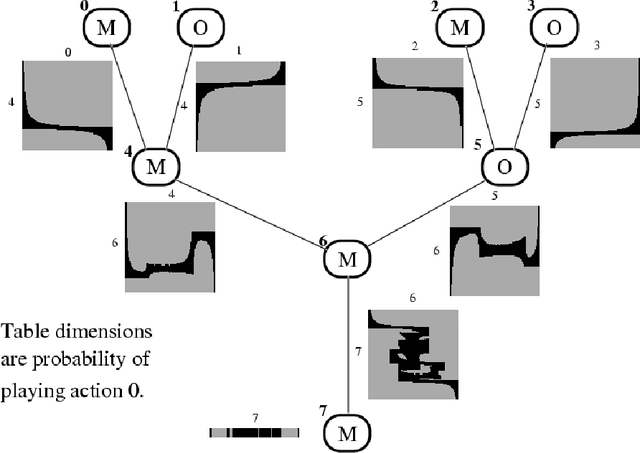
In this work, we introduce graphical modelsfor multi-player game theory, and give powerful algorithms for computing their Nash equilibria in certain cases. An n-player game is given by an undirected graph on n nodes and a set of n local matrices. The interpretation is that the payoff to player i is determined entirely by the actions of player i and his neighbors in the graph, and thus the payoff matrix to player i is indexed only by these players. We thus view the global n-player game as being composed of interacting local games, each involving many fewer players. Each player's action may have global impact, but it occurs through the propagation of local influences.Our main technical result is an efficient algorithm for computing Nash equilibria when the underlying graph is a tree (or can be turned into a tree with few node mergings). The algorithm runs in time polynomial in the size of the representation (the graph and theassociated local game matrices), and comes in two related but distinct flavors. The first version involves an approximation step, and computes a representation of all approximate Nash equilibria (of which there may be an exponential number in general). The second version allows the exact computation of Nash equilibria at the expense of weakened complexity bounds. The algorithm requires only local message-passing between nodes (and thus can be implemented by the players themselves in a distributed manner). Despite an analogy to inference in Bayes nets that we develop, the analysis of our algorithm is more involved than that for the polytree algorithm in, owing partially to the fact that we must either compute, or select from, an exponential number of potential solutions. We discuss a number of extensions, such as the computation of equilibria with desirable global properties (e.g. maximizing global return), and directions for further research.
On the Complexity of Solving Markov Decision Problems
Feb 20, 2013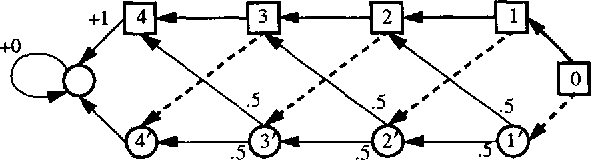
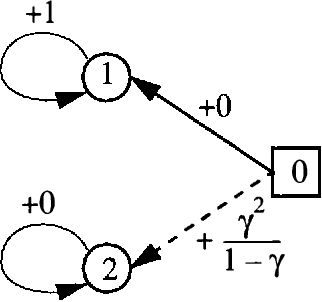
Markov decision problems (MDPs) provide the foundations for a number of problems of interest to AI researchers studying automated planning and reinforcement learning. In this paper, we summarize results regarding the complexity of solving MDPs and the running time of MDP solution algorithms. We argue that, although MDPs can be solved efficiently in theory, more study is needed to reveal practical algorithms for solving large problems quickly. To encourage future research, we sketch some alternative methods of analysis that rely on the structure of MDPs.