 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBad-Policy Density: A Measure of Reinforcement Learning Hardness
Oct 07, 2021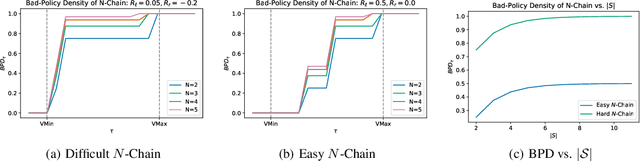
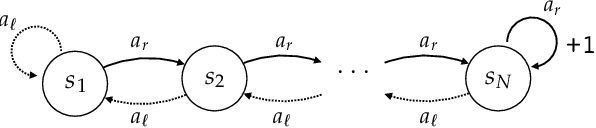
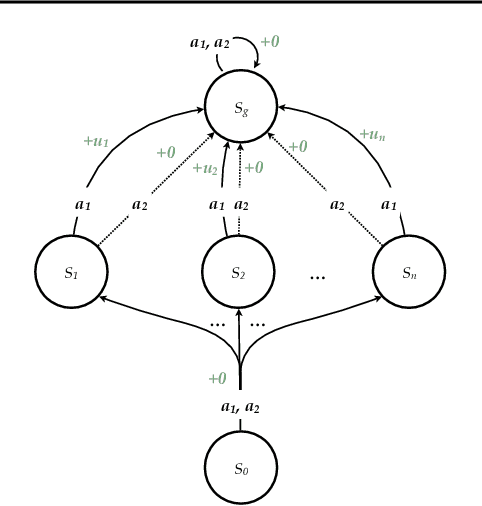
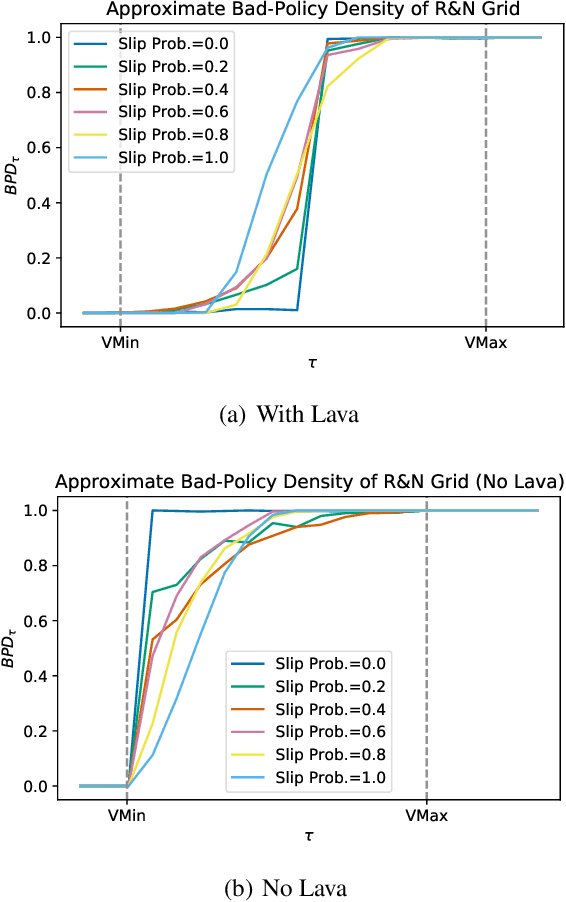
Reinforcement learning is hard in general. Yet, in many specific environments, learning is easy. What makes learning easy in one environment, but difficult in another? We address this question by proposing a simple measure of reinforcement-learning hardness called the bad-policy density. This quantity measures the fraction of the deterministic stationary policy space that is below a desired threshold in value. We prove that this simple quantity has many properties one would expect of a measure of learning hardness. Further, we prove it is NP-hard to compute the measure in general, but there are paths to polynomial-time approximation. We conclude by summarizing potential directions and uses for this measure.
Convergence of a Human-in-the-Loop Policy-Gradient Algorithm With Eligibility Trace Under Reward, Policy, and Advantage Feedback
Sep 15, 2021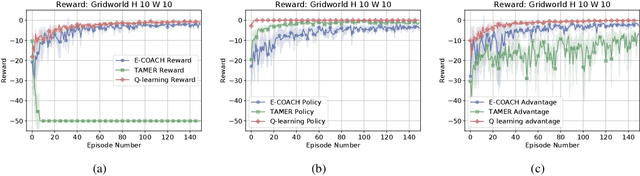

Fluid human-agent communication is essential for the future of human-in-the-loop reinforcement learning. An agent must respond appropriately to feedback from its human trainer even before they have significant experience working together. Therefore, it is important that learning agents respond well to various feedback schemes human trainers are likely to provide. This work analyzes the COnvergent Actor-Critic by Humans (COACH) algorithm under three different types of feedback-policy feedback, reward feedback, and advantage feedback. For these three feedback types, we find that COACH can behave sub-optimally. We propose a variant of COACH, episodic COACH (E-COACH), which we prove converges for all three types. We compare our COACH variant with two other reinforcement-learning algorithms: Q-learning and TAMER.
Brittle AI, Causal Confusion, and Bad Mental Models: Challenges and Successes in the XAI Program
Jun 10, 2021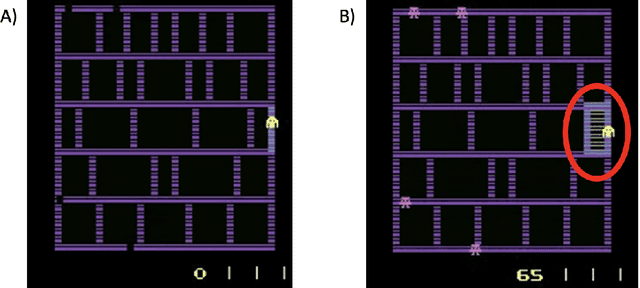
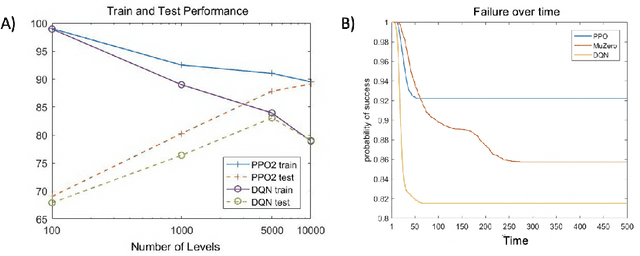
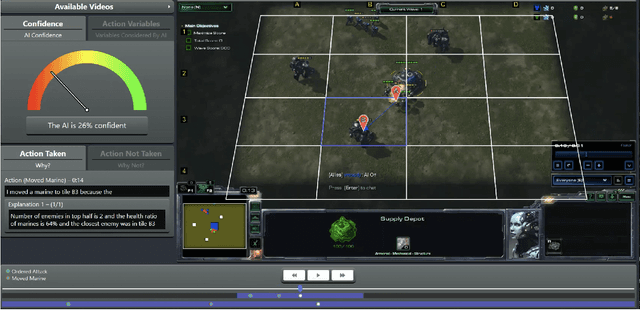

The advances in artificial intelligence enabled by deep learning architectures are undeniable. In several cases, deep neural network driven models have surpassed human level performance in benchmark autonomy tasks. The underlying policies for these agents, however, are not easily interpretable. In fact, given their underlying deep models, it is impossible to directly understand the mapping from observations to actions for any reasonably complex agent. Producing this supporting technology to "open the black box" of these AI systems, while not sacrificing performance, was the fundamental goal of the DARPA XAI program. In our journey through this program, we have several "big picture" takeaways: 1) Explanations need to be highly tailored to their scenario; 2) many seemingly high performing RL agents are extremely brittle and are not amendable to explanation; 3) causal models allow for rich explanations, but how to present them isn't always straightforward; and 4) human subjects conjure fantastically wrong mental models for AIs, and these models are often hard to break. This paper discusses the origins of these takeaways, provides amplifying information, and suggestions for future work.
Control of mental representations in human planning
May 14, 2021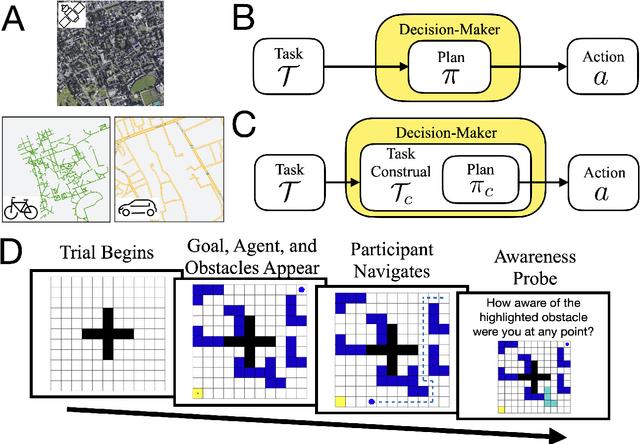
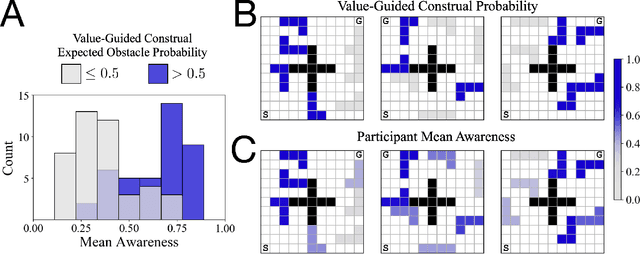
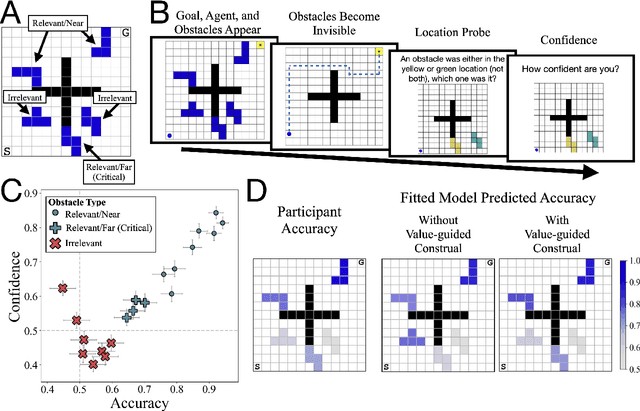
One of the most striking features of human cognition is the capacity to plan. Two aspects of human planning stand out: its efficiency, even in complex environments, and its flexibility, even in changing environments. Efficiency is especially impressive because directly computing an optimal plan is intractable, even for modestly complex tasks, and yet people successfully solve myriad everyday problems despite limited cognitive resources. Standard accounts in psychology, economics, and artificial intelligence have suggested this is because people have a mental representation of a task and then use heuristics to plan in that representation. However, this approach generally assumes that mental representations are fixed. Here, we propose that mental representations can be controlled and that this provides opportunities to adaptively simplify problems so they can be more easily reasoned about -- a process we refer to as construal. We construct a formal model of this process and, in a series of large, pre-registered behavioral experiments, show both that construal is subject to online cognitive control and that people form value-guided construals that optimally balance the complexity of a representation and its utility for planning and acting. These results demonstrate how strategically perceiving and conceiving problems facilitates the effective use of limited cognitive resources.
Towards Sample Efficient Agents through Algorithmic Alignment
Sep 08, 2020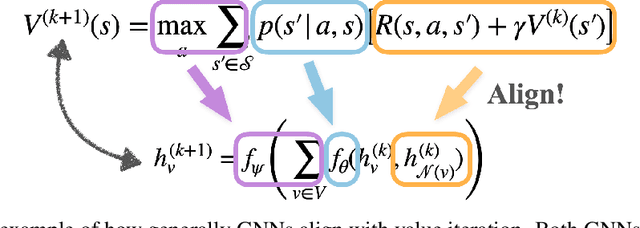
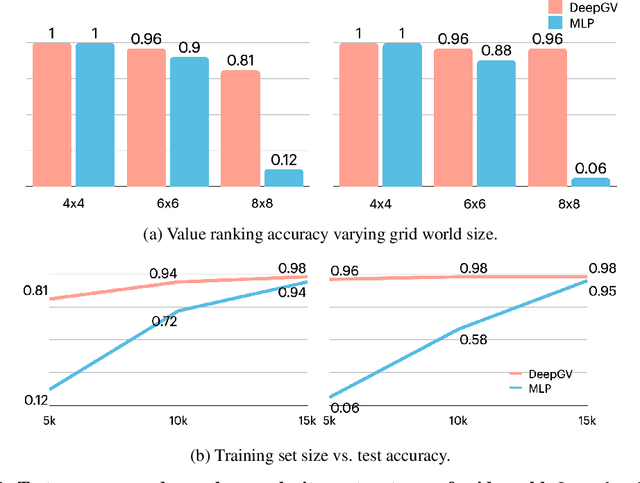
Deep reinforcement-learning agents have demonstrated great success on various tasks. However, current methods typically suffer from sample complexity problems when learning in high dimensional observation spaces, which limits the application of deep reinforcement-learning agents to complex, uncertain real-world tasks. In this work, we propose and explore Deep Graph Value Network as a promising method to work around this drawback using a message-passing mechanism. The main idea is that the RL agent should be guided by structured non-neural-network algorithms like dynamic programming. According to recent advances in algorithmic alignment, neural networks with structured computation procedures can be trained efficiently. We demonstrate the potential of graph neural network in supporting sample efficient learning by showing that Deep Graph Value Network can outperform unstructured baselines by a large margin with low sample complexity.
The Efficiency of Human Cognition Reflects Planned Information Processing
Feb 13, 2020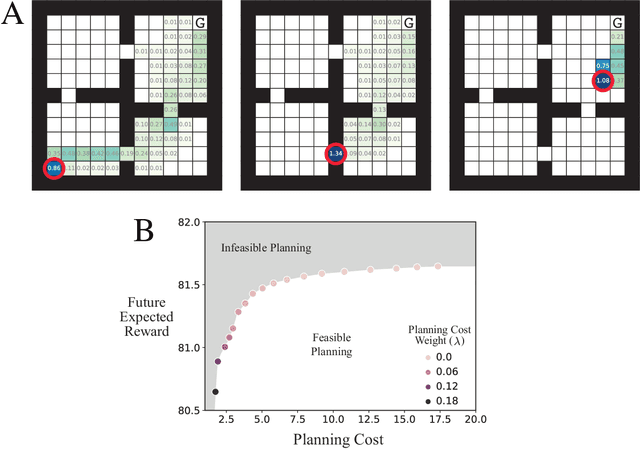
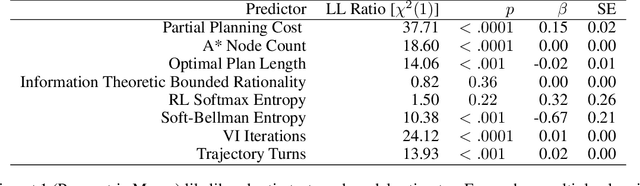
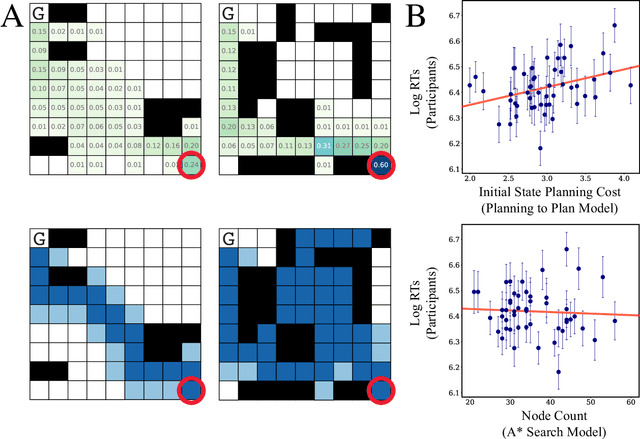

Planning is useful. It lets people take actions that have desirable long-term consequences. But, planning is hard. It requires thinking about consequences, which consumes limited computational and cognitive resources. Thus, people should plan their actions, but they should also be smart about how they deploy resources used for planning their actions. Put another way, people should also "plan their plans". Here, we formulate this aspect of planning as a meta-reasoning problem and formalize it in terms of a recursive Bellman objective that incorporates both task rewards and information-theoretic planning costs. Our account makes quantitative predictions about how people should plan and meta-plan as a function of the overall structure of a task, which we test in two experiments with human participants. We find that people's reaction times reflect a planned use of information processing, consistent with our account. This formulation of planning to plan provides new insight into the function of hierarchical planning, state abstraction, and cognitive control in both humans and machines.
Learning State Abstractions for Transfer in Continuous Control
Feb 08, 2020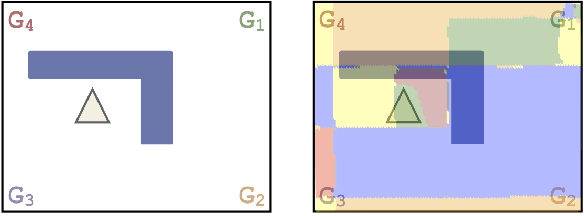
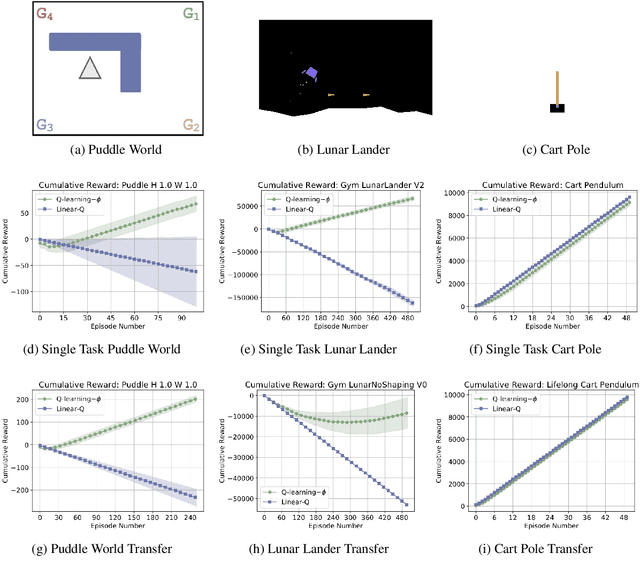
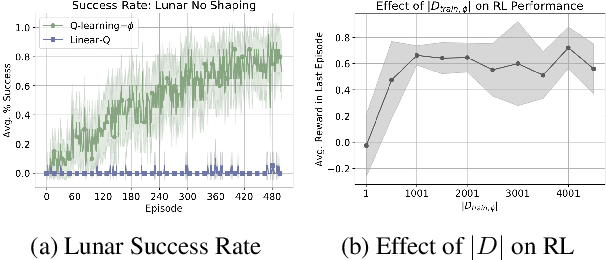
Can simple algorithms with a good representation solve challenging reinforcement learning problems? In this work, we answer this question in the affirmative, where we take "simple learning algorithm" to be tabular Q-Learning, the "good representations" to be a learned state abstraction, and "challenging problems" to be continuous control tasks. Our main contribution is a learning algorithm that abstracts a continuous state-space into a discrete one. We transfer this learned representation to unseen problems to enable effective learning. We provide theory showing that learned abstractions maintain a bounded value loss, and we report experiments showing that the abstractions empower tabular Q-Learning to learn efficiently in unseen tasks.
Deep RBF Value Functions for Continuous Control
Feb 05, 2020
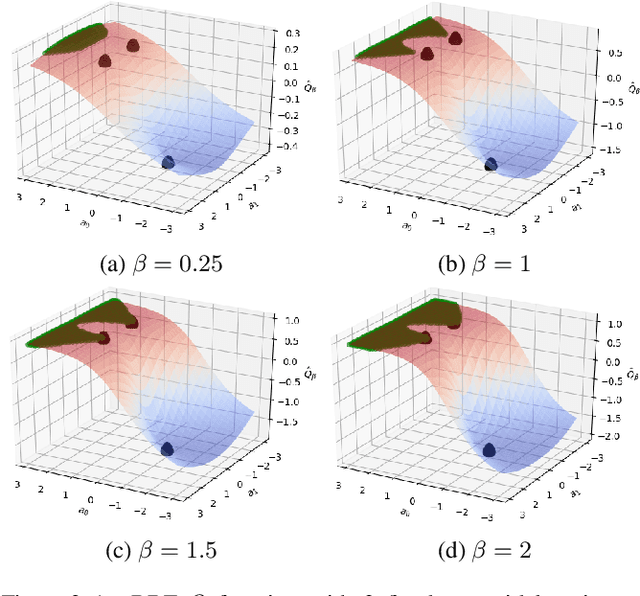
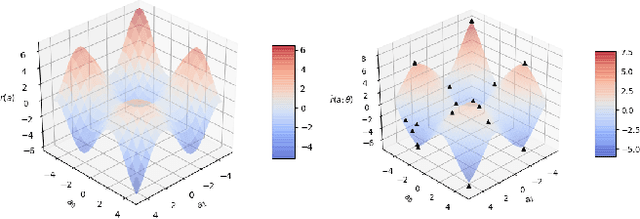
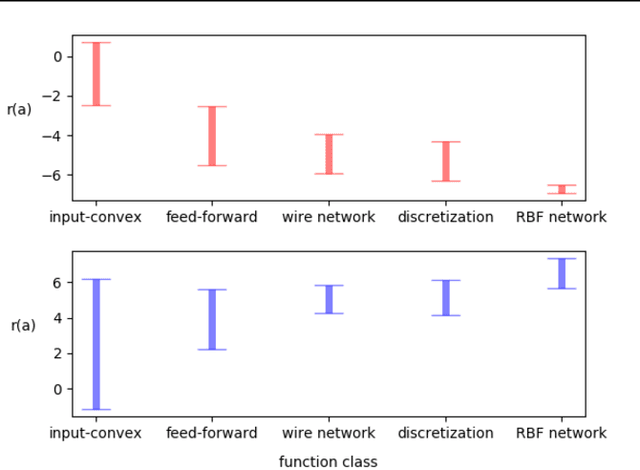
A core operation in reinforcement learning (RL) is finding an action that is optimal with respect to a learned state-action value function. This operation is often challenging when the learned value function takes continuous actions as input. We introduce deep RBF value functions: state-action value functions learned using a deep neural network with a radial-basis function (RBF) output layer. We show that the optimal action with respect to a deep RBF value function can be easily approximated up to any desired accuracy. Moreover, deep RBF value functions can represent any true value function up to any desired accuracy owing to their support for universal function approximation. By learning a deep RBF value function, we extend the standard DQN algorithm to continuous control, and demonstrate that the resultant agent, RBF-DQN, outperforms standard baselines on a set of continuous-action RL problems.
Lipschitz Lifelong Reinforcement Learning
Jan 17, 2020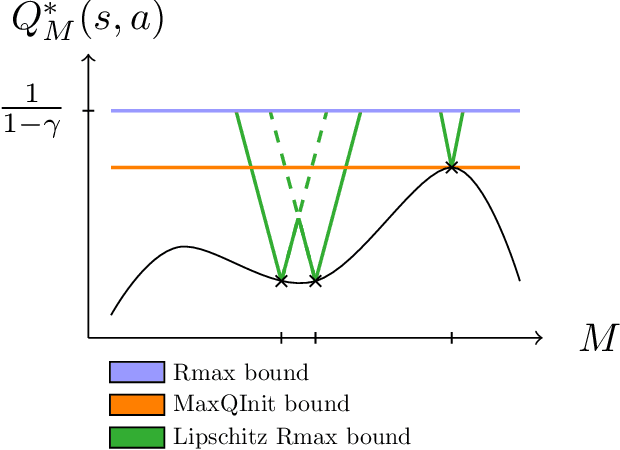
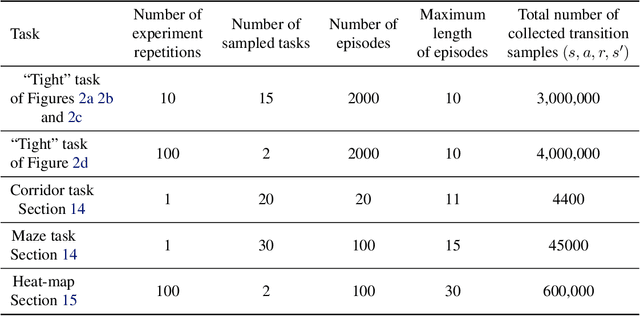
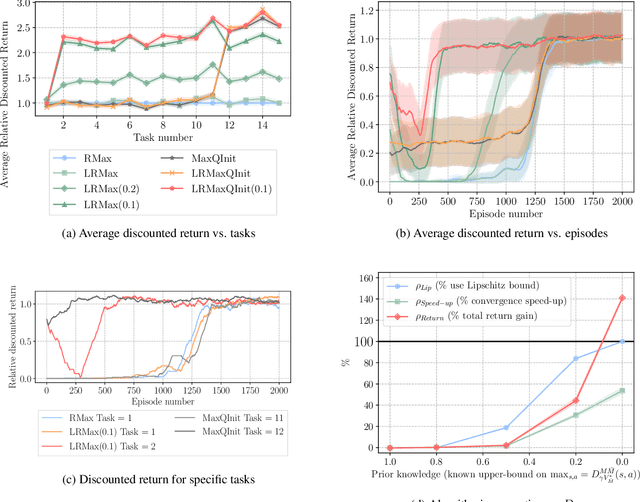
We consider the problem of knowledge transfer when an agent is facing a series of Reinforcement Learning (RL) tasks. We introduce a novel metric between Markov Decision Processes and establish that close MDPs have close optimal value functions. Formally, the optimal value functions are Lipschitz continuous with respect to the tasks space. These theoretical results lead us to a value transfer method for Lifelong RL, which we use to build a PAC-MDP algorithm with improved convergence rate. We illustrate the benefits of the method in Lifelong RL experiments.
Individual predictions matter: Assessing the effect of data ordering in training fine-tuned CNNs for medical imaging
Dec 08, 2019
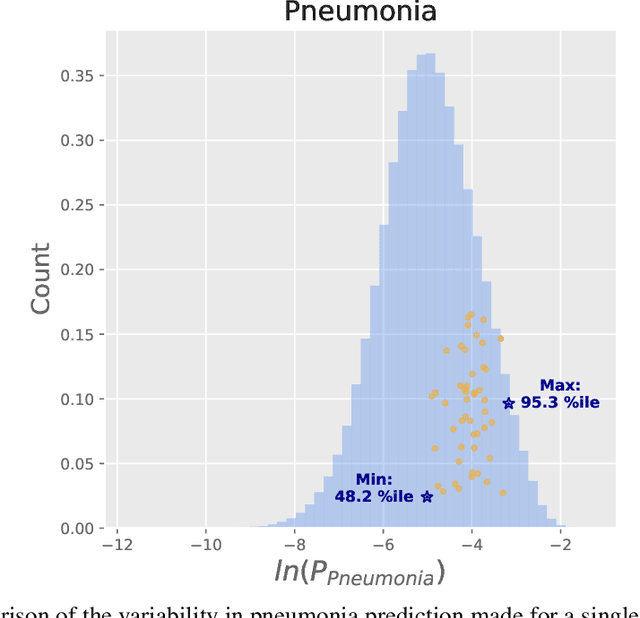
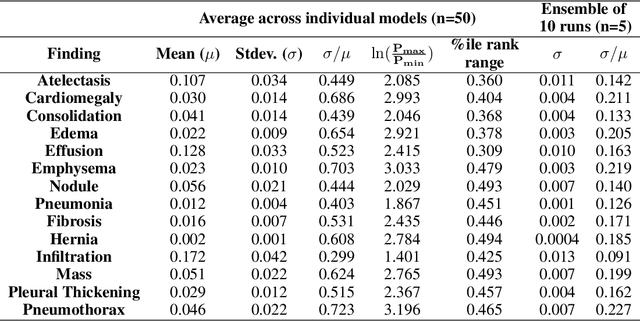
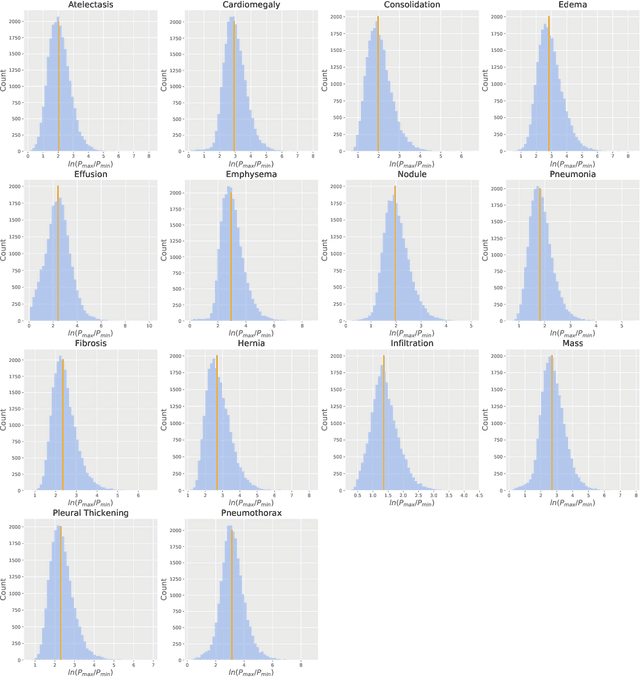
We reproduced the results of CheXNet with fixed hyperparameters and 50 different random seeds to identify 14 finding in chest radiographs (x-rays). Because CheXNet fine-tunes a pre-trained DenseNet, the random seed affects the ordering of the batches of training data but not the initialized model weights. We found substantial variability in predictions for the same radiograph across model runs (mean ln[(maximum probability)/(minimum probability)] 2.45, coefficient of variation 0.543). This individual radiograph-level variability was not fully reflected in the variability of AUC on a large test set. Averaging predictions from 10 models reduced variability by nearly 70% (mean coefficient of variation from 0.543 to 0.169, t-test 15.96, p-value < 0.0001). We encourage researchers to be aware of the potential variability of CNNs and ensemble predictions from multiple models to minimize the effect this variability may have on the care of individual patients when these models are deployed clinically.