 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext is all you need: Towards autonomous model-based process design using agentic AI in flowsheet simulations
Mar 13, 2026Agentic AI systems integrating large language models (LLMs) with reasoning and tooluse capabilities are transforming various domains - in particular, software development. In contrast, their application in chemical process flowsheet modelling remains largely unexplored. In this work, we present an agentic AI framework that delivers assistance in an industrial flowsheet simulation environment. To this end, we show the capabilities of GitHub Copilot (GitHub, Inc., 2026), when using state-of-the-art LLMs, such as Claude Opus 4.6 (Anthropic, PBC, 2026), to generate valid syntax for our in-house process modelling tool Chemasim using the technical documentation and a few commented examples as context. Based on this, we develop a multi-agent system that decomposes process development tasks with one agent solving the abstract problem using engineering knowledge and another agent implementing the solution as Chemasim code. We demonstrate the effectiveness of our framework for typical flowsheet modelling examples, including (i) a reaction/separation process, (ii) a pressure-swing distillation, and (iii) a heteroazeotropic distillation including entrainer selection. Along these lines, we discuss current limitations of the framework and outline future research directions to further enhance its capabilities.
Optimized data exploration applied to the simulation of a chemical process
Feb 18, 2019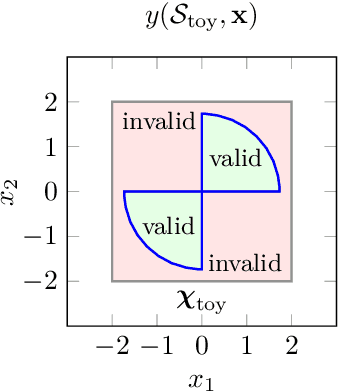
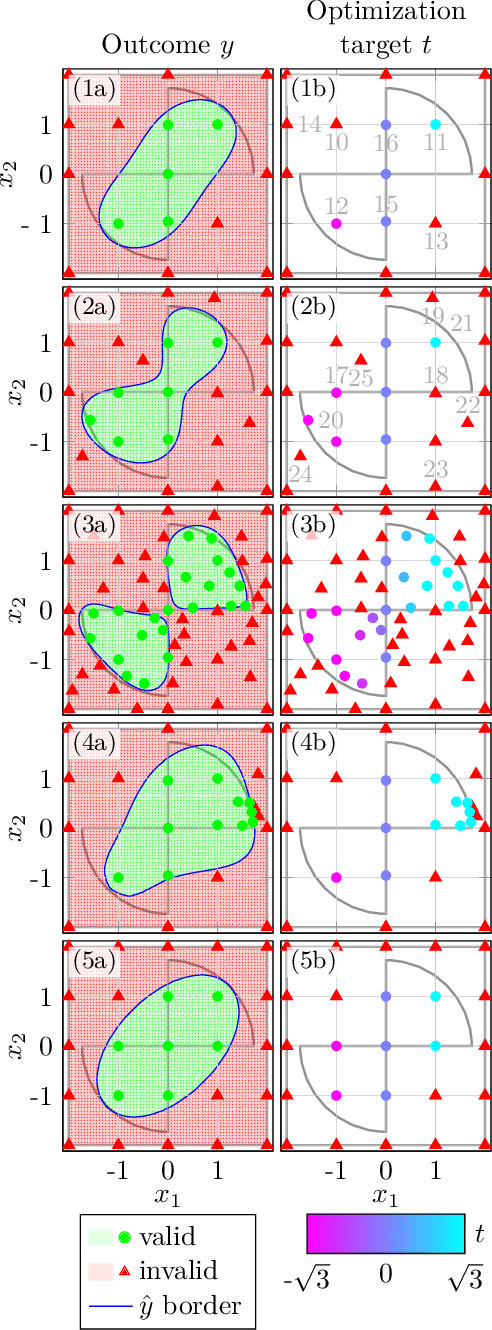
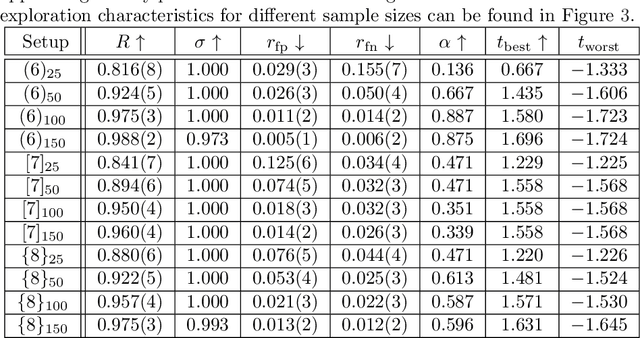
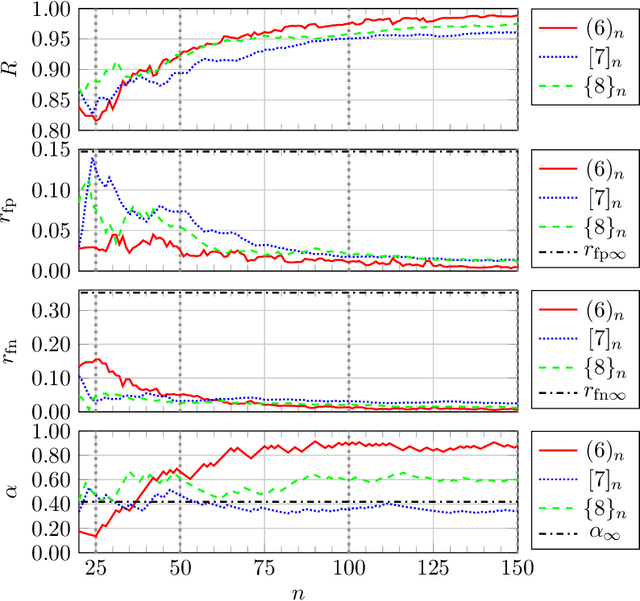
In complex simulation environments, certain parameter space regions may result in non-convergent or unphysical outcomes. All parameters can therefore be labeled with a binary class describing whether or not they lead to valid results. In general, it can be very difficult to determine feasible parameter regions, especially without previous knowledge. We propose a novel algorithm to explore such an unknown parameter space and improve its feasibility classification in an iterative way. Moreover, we include an additional optimization target in the algorithm to guide the exploration towards regions of interest and to improve the classification therein. In our method we make use of well-established concepts from the field of machine learning like kernel support vector machines and kernel ridge regression. From a comparison with a Kriging-based exploration approach based on recently published results we can show the advantages of our algorithm in a binary feasibility classification scenario with a discrete feasibility constraint violation. In this context, we also propose an improvement of the Kriging-based exploration approach. We apply our novel method to a fully realistic, industrially relevant chemical process simulation to demonstrate its practical usability and find a comparably good approximation of the data space topology from relatively few data points.
* 45 pages, 6 figures