 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultidimensional Voronoi Constellations vs. Short Blocklength Probabilistic Shaping: A Comparison for Multilevel Coding Approach
Sep 30, 2024



Performance of concatenated multilevel coding with probabilistic shaping (PS) and Voronoi constellations (VCs) is analysed over AWGN channel. Numerical results show that VCs provide up to 1.3 dB SNR gains over PS-QAM with CCDM blocklength of 200.
Preamble Design for Joint Frame Synchronization, Frequency Offset Estimation, and Channel Estimation in Upstream Burst-mode Detection of Coherent PONs
Sep 22, 2024Coherent optics has demonstrated significant potential as a viable solution for achieving 100 Gb/s and higher speeds in single-wavelength passive optical networks (PON). However, upstream burst-mode coherent detection is a major challenge when adopting coherent optics in access networks. To accelerate digital signal processing (DSP) convergence with a minimal preamble length, we propose a novel burst-mode preamble design based on a constant amplitude zero auto-correlation sequence. This design facilitates comprehensive estimation of linear channel effects in the frequency domain, including polarization state rotation, differential group delay, chromatic dispersion, and polarization-dependent loss, providing overall system response information for channel equalization pre-convergence. Additionally, this preamble utilizes the same training unit to jointly achieve three key DSP functions: frame synchronization, frequency offset estimation, and channel estimation. This integration contributes to a significant reduction in the preamble length. The feasibility of the proposed preamble with a length of 272 symbols and corresponding DSP was experimentally verified in a 15 Gbaud coherent system using dual-polarization 16 quadrature amplitude modulation. The experimental results based on this scheme showed a superior performance of the convergence acceleration.
Building a digital twin of EDFA: a grey-box modeling approach
Jul 13, 2023



To enable intelligent and self-driving optical networks, high-accuracy physical layer models are required. The dynamic wavelength-dependent gain effects of non-constant-pump erbium-doped fiber amplifiers (EDFAs) remain a crucial problem in terms of modeling, as it determines optical-to-signal noise ratio as well as the magnitude of fiber nonlinearities. Black-box data-driven models have been widely studied, but it requires a large size of data for training and suffers from poor generalizability. In this paper, we derive the gain spectra of EDFAs as a simple univariable linear function, and then based on it we propose a grey-box EDFA gain modeling scheme. Experimental results show that for both automatic gain control (AGC) and automatic power control (APC) EDFAs, our model built with 8 data samples can achieve better performance than the neural network (NN) based model built with 900 data samples, which means the required data size for modeling can be reduced by at least two orders of magnitude. Moreover, in the experiment the proposed model demonstrates superior generalizability to unseen scenarios since it is based on the underlying physics of EDFAs. The results indicate that building a customized digital twin of each EDFA in optical networks become feasible, which is essential especially for next generation multi-band network operations.
Multicarrier Modulation-Based Digital Radio-over-Fibre System Achieving Unequal Bit Protection with Over 10 dB SNR Gain
Jul 04, 2023


We propose a multicarrier modulation-based digital radio-over-fibre system achieving unequal bit protection by bit and power allocation for subcarriers. A theoretical SNR gain of 16.1 dB is obtained in the AWGN channel and the simulation results show a 13.5 dB gain in the bandwidth-limited case.
SE-Bridge: Speech Enhancement with Consistent Brownian Bridge
May 23, 2023



We propose SE-Bridge, a novel method for speech enhancement (SE). After recently applying the diffusion models to speech enhancement, we can achieve speech enhancement by solving a stochastic differential equation (SDE). Each SDE corresponds to a probabilistic flow ordinary differential equation (PF-ODE), and the trajectory of the PF-ODE solution consists of the speech states at different moments. Our approach is based on consistency model that ensure any speech states on the same PF-ODE trajectory, correspond to the same initial state. By integrating the Brownian Bridge process, the model is able to generate high-intelligibility speech samples without adversarial training. This is the first attempt that applies the consistency models to SE task, achieving state-of-the-art results in several metrics while saving 15 x the time required for sampling compared to the diffusion-based baseline. Our experiments on multiple datasets demonstrate the effectiveness of SE-Bridge in SE. Furthermore, we show through extensive experiments on downstream tasks, including Automatic Speech Recognition (ASR) and Speaker Verification (SV), that SE-Bridge can effectively support multiple downstream tasks.
SRTNet: Time Domain Speech Enhancement Via Stochastic Refinement
Oct 30, 2022



Diffusion model, as a new generative model which is very popular in image generation and audio synthesis, is rarely used in speech enhancement. In this paper, we use the diffusion model as a module for stochastic refinement. We propose SRTNet, a novel method for speech enhancement via Stochastic Refinement in complete Time domain. Specifically, we design a joint network consisting of a deterministic module and a stochastic module, which makes up the ``enhance-and-refine'' paradigm. We theoretically demonstrate the feasibility of our method and experimentally prove that our method achieves faster training, faster sampling and higher quality. Our code and enhanced samples are available at https://github.com/zhibinQiu/SRTNet.git.
An Interpretable Mapping from a Communication System to a Neural Network for Optimal Transceiver-Joint Equalization
Mar 23, 2021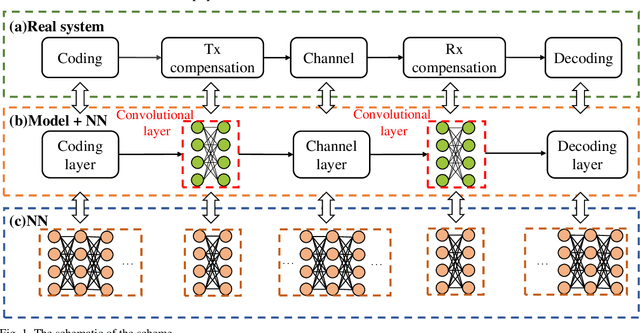
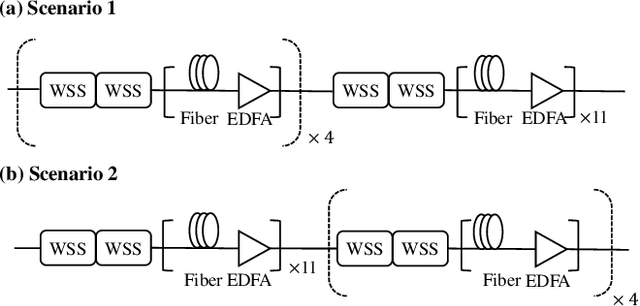
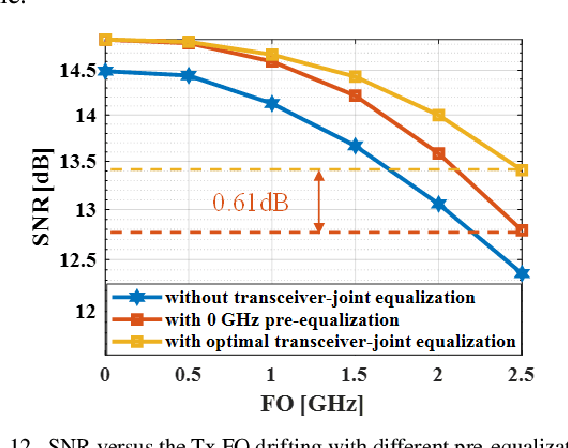
In this paper, we propose a scheme that utilizes the optimization ability of artificial intelligence (AI) for optimal transceiver-joint equalization in compensating for the optical filtering impairments caused by wavelength selective switches (WSS). In contrast to adding or replacing a certain module of existing digital signal processing (DSP), we exploit the similarity between a communication system and a neural network (NN). By mapping a communication system to an NN, in which the equalization modules correspond to the convolutional layers and other modules can been regarded as static layers, the optimal transceiver-joint equalization coefficients can be obtained. In particular, the DSP structure of the communication system is not changed. Extensive numerical simulations are performed to validate the performance of the proposed method. For a 65 GBaud 16QAM signal, it can achieve a 0.76 dB gain when the number of WSSs is 16 with a -6 dB bandwidth of 73 GHz.
Low Complexity Component Nonlinear Distortions Mitigation Scheme for Probabilistically Shaped 64-QAM Signals
Dec 21, 2020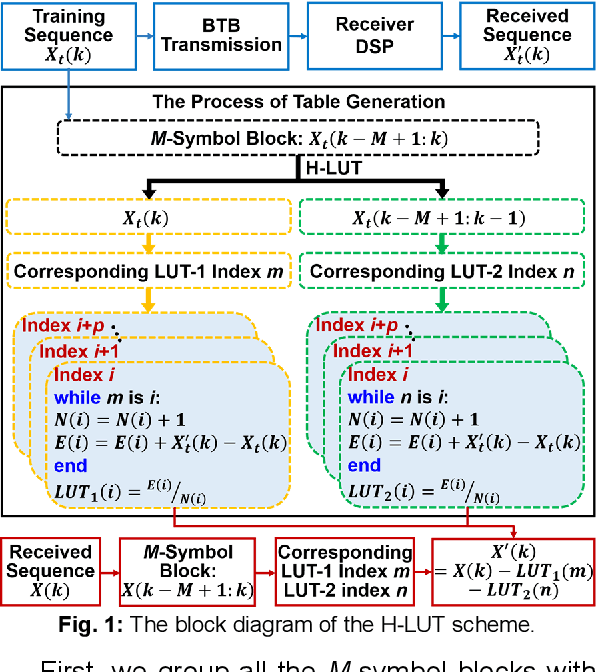
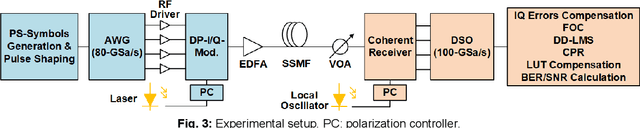
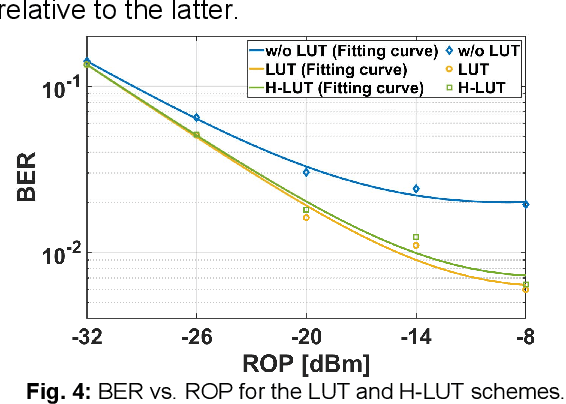
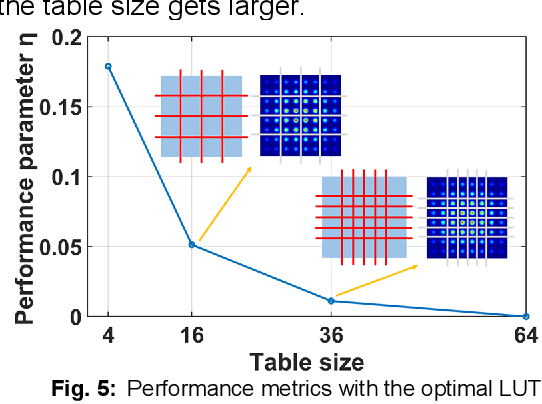
We propose a degenerated hierarchical look-up table (DH-LUT) scheme to compensate component nonlinearities. For probabilistically shaped 64-QAM signals, it achieves up to 2-dB SNR improvement, while the size of table is only 8.59% compared to the conventional LUT method.