 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource Utilization of Differentiable Logic Gate Networks Deployed on FPGAs
May 04, 2026On-edge machine learning (ML) often strives to maximize the intelligence of small models while miniaturizing the circuit size and power needed to perform inference. Meeting these needs, differentiable Logic Gate Networks (LGN) have demonstrated nanosecond-scale prediction speeds while reducing the required resources as compares to traditional binary neural networks. Despite these benefits, the trade-offs between LGN parameters and resulting hardware synthesis characteristics are not well characterized. This paper therefore studies the tradeoffs between power, resource utilization, inference speed, and model accuracy when varying the depth and width of LGNs synthesized for Field Programmable Gate Arrays (FPGA). Results reveal that the final layer of an LGN is critical to minimize timing and resource usage (i.e. 28\% decrease), as this layer dictates the logic size of summing operations. Subject to timing and routing constraints, deeper and wider LGNs can be synthesized for FPGA when the final layer is narrow. Further tradeoffs are presented to help ML engineers select baseline LGN architectures for FPGAs with a set number of Look Up Tables (LUT).
Is the Digital Forensics and Incident Response Pipeline Ready for Text-Based Threats in LLM Era?
Jul 25, 2024



In the era of generative AI, the widespread adoption of Neural Text Generators (NTGs) presents new cybersecurity challenges, particularly within the realms of Digital Forensics and Incident Response (DFIR). These challenges primarily involve the detection and attribution of sources behind advanced attacks like spearphishing and disinformation campaigns. As NTGs evolve, the task of distinguishing between human and NTG-authored texts becomes critically complex. This paper rigorously evaluates the DFIR pipeline tailored for text-based security systems, specifically focusing on the challenges of detecting and attributing authorship of NTG-authored texts. By introducing a novel human-NTG co-authorship text attack, termed CS-ACT, our study uncovers significant vulnerabilities in traditional DFIR methodologies, highlighting discrepancies between ideal scenarios and real-world conditions. Utilizing 14 diverse datasets and 43 unique NTGs, up to the latest GPT-4, our research identifies substantial vulnerabilities in the forensic profiling phase, particularly in attributing authorship to NTGs. Our comprehensive evaluation points to factors such as model sophistication and the lack of distinctive style within NTGs as significant contributors for these vulnerabilities. Our findings underscore the necessity for more sophisticated and adaptable strategies, such as incorporating adversarial learning, stylizing NTGs, and implementing hierarchical attribution through the mapping of NTG lineages to enhance source attribution. This sets the stage for future research and the development of more resilient text-based security systems.
TraSE: Towards Tackling Authorial Style from a Cognitive Science Perspective
Jun 21, 2022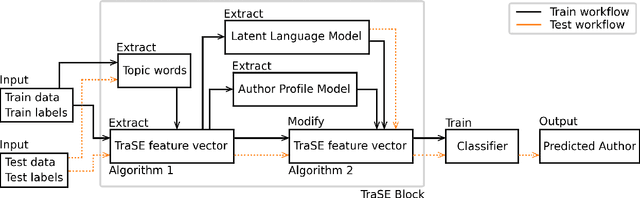

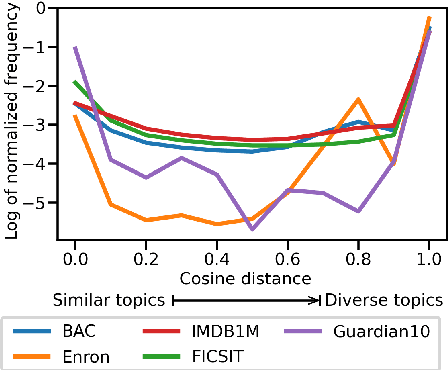
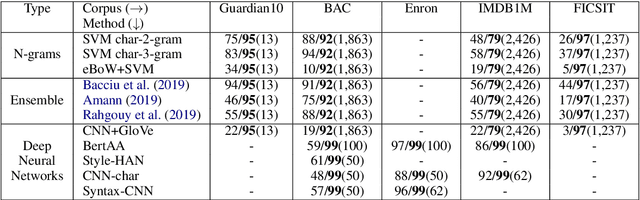
Stylistic analysis of text is a key task in research areas ranging from authorship attribution to forensic analysis and personality profiling. The existing approaches for stylistic analysis are plagued by issues like topic influence, lack of discriminability for large number of authors and the requirement for large amounts of diverse data. In this paper, the source of these issues are identified along with the necessity for a cognitive perspective on authorial style in addressing them. A novel feature representation, called Trajectory-based Style Estimation (TraSE), is introduced to support this purpose. Authorship attribution experiments with over 27,000 authors and 1.4 million samples in a cross-domain scenario resulted in 90% attribution accuracy suggesting that the feature representation is immune to such negative influences and an excellent candidate for stylistic analysis. Finally, a qualitative analysis is performed on TraSE using physical human characteristics, like age, to validate its claim on capturing cognitive traits.