 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Infectiousness for Proactive Contact Tracing
Oct 23, 2020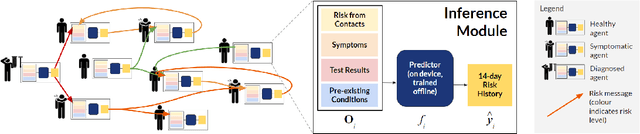
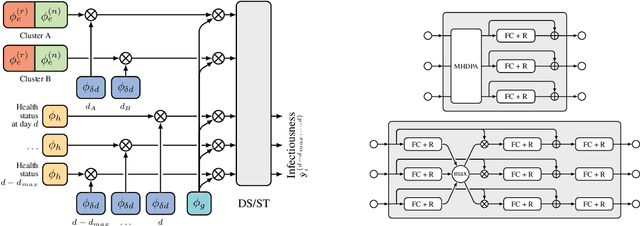
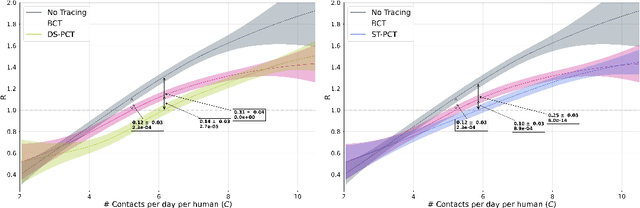
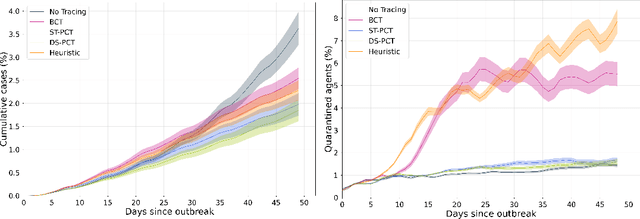
The COVID-19 pandemic has spread rapidly worldwide, overwhelming manual contact tracing in many countries and resulting in widespread lockdowns for emergency containment. Large-scale digital contact tracing (DCT) has emerged as a potential solution to resume economic and social activity while minimizing spread of the virus. Various DCT methods have been proposed, each making trade-offs between privacy, mobility restrictions, and public health. The most common approach, binary contact tracing (BCT), models infection as a binary event, informed only by an individual's test results, with corresponding binary recommendations that either all or none of the individual's contacts quarantine. BCT ignores the inherent uncertainty in contacts and the infection process, which could be used to tailor messaging to high-risk individuals, and prompt proactive testing or earlier warnings. It also does not make use of observations such as symptoms or pre-existing medical conditions, which could be used to make more accurate infectiousness predictions. In this paper, we use a recently-proposed COVID-19 epidemiological simulator to develop and test methods that can be deployed to a smartphone to locally and proactively predict an individual's infectiousness (risk of infecting others) based on their contact history and other information, while respecting strong privacy constraints. Predictions are used to provide personalized recommendations to the individual via an app, as well as to send anonymized messages to the individual's contacts, who use this information to better predict their own infectiousness, an approach we call proactive contact tracing (PCT). We find a deep-learning based PCT method which improves over BCT for equivalent average mobility, suggesting PCT could help in safe re-opening and second-wave prevention.
RNNLogic: Learning Logic Rules for Reasoning on Knowledge Graphs
Oct 08, 2020

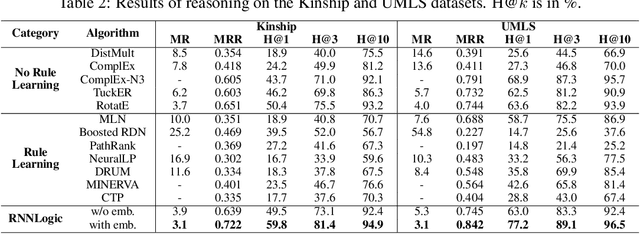
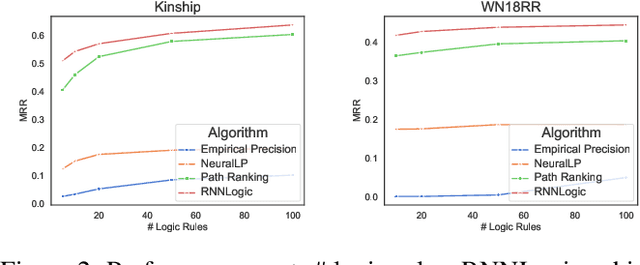
This paper studies learning logic rules for reasoning on knowledge graphs. Logic rules provide interpretable explanations when used for prediction as well as being able to generalize to other tasks, and hence are critical to learn. Existing methods either suffer from the problem of searching in a large search space (e.g., neural logic programming) or ineffective optimization due to sparse rewards (e.g., techniques based on reinforcement learning). To address these limitations, this paper proposes a probabilistic model called RNNLogic. RNNLogic treats logic rules as a latent variable, and simultaneously trains a rule generator as well as a reasoning predictor with logic rules. We develop an EM-based algorithm for optimization. In each iteration, the reasoning predictor is first updated to explore some generated logic rules for reasoning. Then in the E-step, we select a set of high-quality rules from all generated rules with both the rule generator and reasoning predictor via posterior inference; and in the M-step, the rule generator is updated with the rules selected in the E-step. Experiments on four datasets prove the effectiveness of RNNLogic.
Few-shot Relation Extraction via Bayesian Meta-learning on Relation Graphs
Jul 05, 2020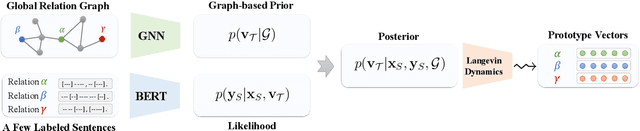
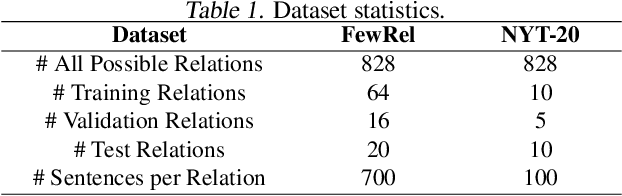
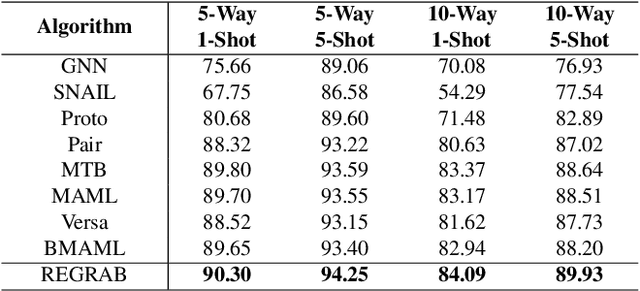

This paper studies few-shot relation extraction, which aims at predicting the relation for a pair of entities in a sentence by training with a few labeled examples in each relation. To more effectively generalize to new relations, in this paper we study the relationships between different relations and propose to leverage a global relation graph. We propose a novel Bayesian meta-learning approach to effectively learn the posterior distribution of the prototype vectors of relations, where the initial prior of the prototype vectors is parameterized with a graph neural network on the global relation graph. Moreover, to effectively optimize the posterior distribution of the prototype vectors, we propose to use the stochastic gradient Langevin dynamics, which is related to the MAML algorithm but is able to handle the uncertainty of the prototype vectors. The whole framework can be effectively and efficiently optimized in an end-to-end fashion. Experiments on two benchmark datasets prove the effectiveness of our proposed approach against competitive baselines in both the few-shot and zero-shot settings.
Graph Policy Network for Transferable Active Learning on Graphs
Jun 24, 2020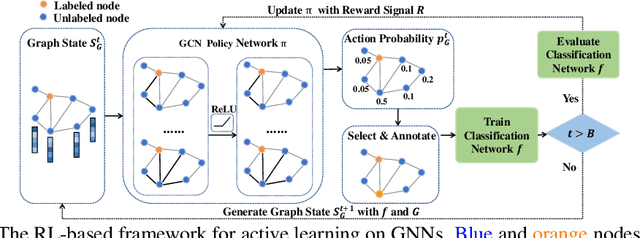
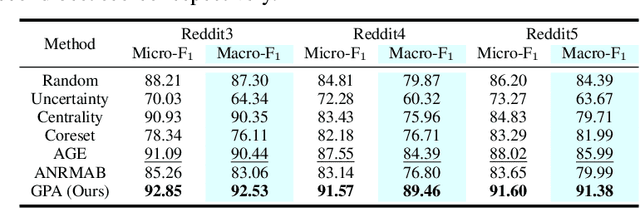
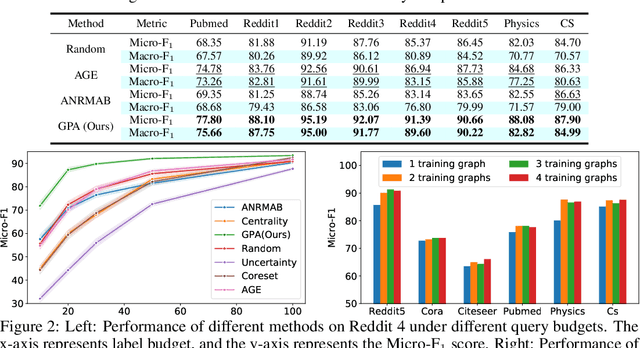

Graph neural networks (GNNs) have been attracting increasing popularity due to their simplicity and effectiveness in a variety of fields. However, a large number of labeled data is generally required to train these networks, which could be very expensive to obtain in some domains. In this paper, we study active learning for GNNs, i.e., how to efficiently label the nodes on a graph to reduce the annotation cost of training GNNs. We formulate the problem as a sequential decision process on graphs and train a GNN-based policy network with reinforcement learning to learn the optimal query strategy. By jointly optimizing over several source graphs with full labels, we learn a transferable active learning policy which can directly generalize to unlabeled target graphs under a zero-shot transfer setting. Experimental results on multiple graphs from different domains prove the effectiveness of our proposed approach in both settings of transferring between graphs in the same domain and across different domains.
COVI White Paper
May 18, 2020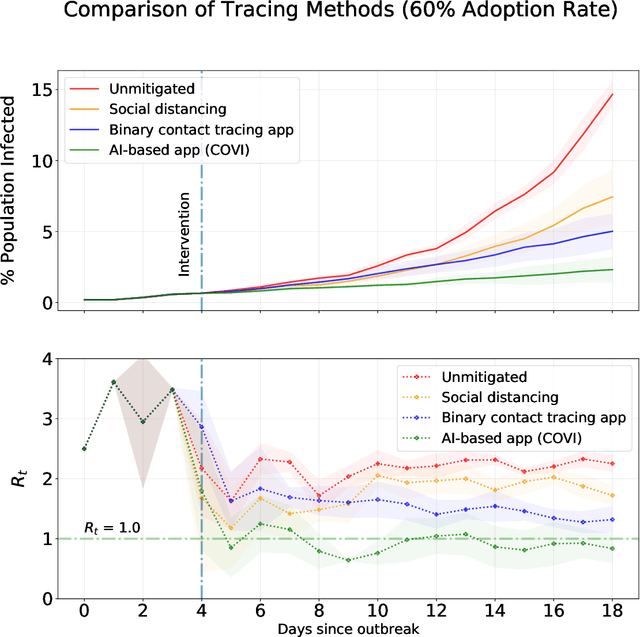
The SARS-CoV-2 (Covid-19) pandemic has caused significant strain on public health institutions around the world. Contact tracing is an essential tool to change the course of the Covid-19 pandemic. Manual contact tracing of Covid-19 cases has significant challenges that limit the ability of public health authorities to minimize community infections. Personalized peer-to-peer contact tracing through the use of mobile apps has the potential to shift the paradigm. Some countries have deployed centralized tracking systems, but more privacy-protecting decentralized systems offer much of the same benefit without concentrating data in the hands of a state authority or for-profit corporations. Machine learning methods can circumvent some of the limitations of standard digital tracing by incorporating many clues and their uncertainty into a more graded and precise estimation of infection risk. The estimated risk can provide early risk awareness, personalized recommendations and relevant information to the user. Finally, non-identifying risk data can inform epidemiological models trained jointly with the machine learning predictor. These models can provide statistical evidence for the importance of factors involved in disease transmission. They can also be used to monitor, evaluate and optimize health policy and (de)confinement scenarios according to medical and economic productivity indicators. However, such a strategy based on mobile apps and machine learning should proactively mitigate potential ethical and privacy risks, which could have substantial impacts on society (not only impacts on health but also impacts such as stigmatization and abuse of personal data). Here, we present an overview of the rationale, design, ethical considerations and privacy strategy of `COVI,' a Covid-19 public peer-to-peer contact tracing and risk awareness mobile application developed in Canada.
Continuous Graph Neural Networks
Dec 02, 2019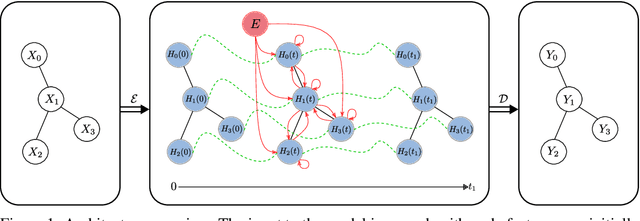


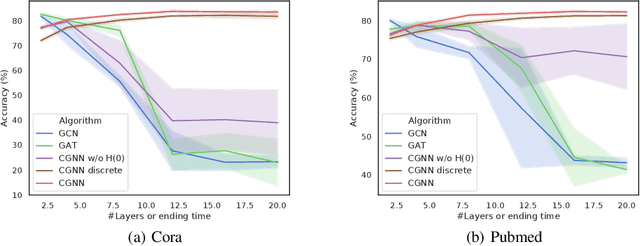
This paper builds the connection between graph neural networks and traditional dynamical systems. Existing graph neural networks essentially define a discrete dynamic on node representations with multiple graph convolution layers. We propose continuous graph neural networks (CGNN), which generalise existing graph neural networks into the continuous-time dynamic setting. The key idea is how to characterise the continuous dynamics of node representations, i.e. the derivatives of node representations w.r.t. time. Inspired by existing diffusion-based methods on graphs (e.g. PageRank and epidemic models on social networks), we define the derivatives as a combination of the current node representations, the representations of neighbors, and the initial values of the nodes. We propose and analyse different possible dynamics on graphs---including each dimension of node representations (a.k.a. the feature channel) change independently or interact with each other---both with theoretical justification. The proposed continuous graph neural networks are robust to over-smoothing and hence capture the long-range dependencies between nodes. Experimental results on the task of node classification prove the effectiveness of our proposed approach over competitive baselines.
GraphMix: Regularized Training of Graph Neural Networks for Semi-Supervised Learning
Sep 25, 2019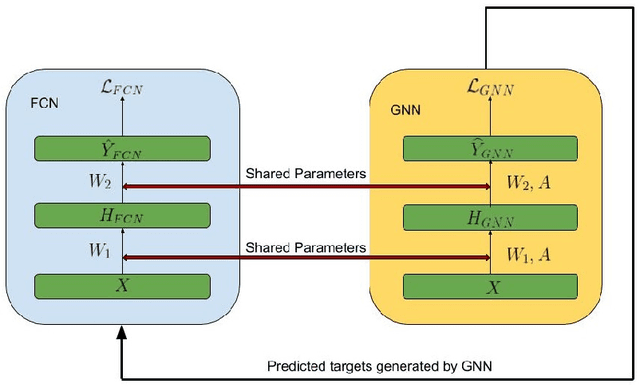
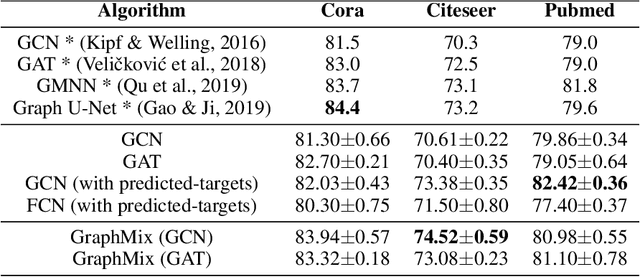

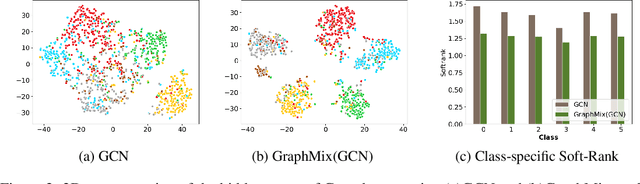
We present GraphMix, a regularization technique for Graph Neural Network based semi-supervised object classification, leveraging the recent advances in the regularization of classical deep neural networks. Specifically, we propose a unified approach in which we train a fully-connected network jointly with the graph neural network via parameter sharing, interpolation-based regularization, and self-predicted-targets. Our proposed method is architecture agnostic in the sense that it can be applied to any variant of graph neural networks which applies a parametric transformation to the features of the graph nodes. Despite its simplicity, with GraphMix we can consistently improve results and achieve or closely match state-of-the-art performance using even simpler architectures such as Graph Convolutional Networks, across three established graph benchmarks: the Cora, Citeseer and Pubmed citation network datasets, as well as three newly proposed datasets : Cora-Full, Co-author-CS and Co-author-Physics.
Collaborative Policy Learning for Open Knowledge Graph Reasoning
Aug 31, 2019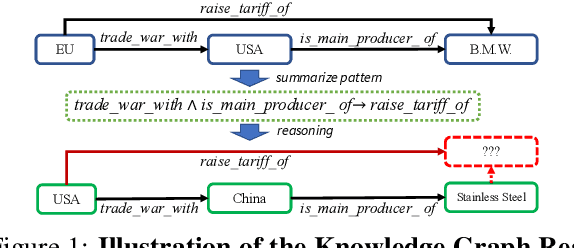

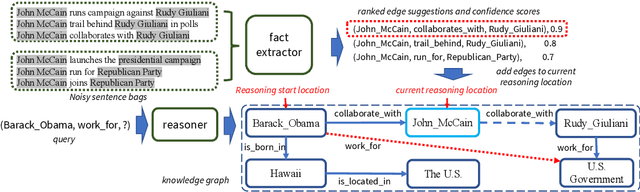

In recent years, there has been a surge of interests in interpretable graph reasoning methods. However, these models often suffer from limited performance when working on sparse and incomplete graphs, due to the lack of evidential paths that can reach target entities. Here we study open knowledge graph reasoning---a task that aims to reason for missing facts over a graph augmented by a background text corpus. A key challenge of the task is to filter out "irrelevant" facts extracted from corpus, in order to maintain an effective search space during path inference. We propose a novel reinforcement learning framework to train two collaborative agents jointly, i.e., a multi-hop graph reasoner and a fact extractor. The fact extraction agent generates fact triples from corpora to enrich the graph on the fly; while the reasoning agent provides feedback to the fact extractor and guides it towards promoting facts that are helpful for the interpretable reasoning. Experiments on two public datasets demonstrate the effectiveness of the proposed approach. Source code and datasets used in this paper can be downloaded at https://github.com/shanzhenren/CPL
Weakly-supervised Knowledge Graph Alignment with Adversarial Learning
Jul 06, 2019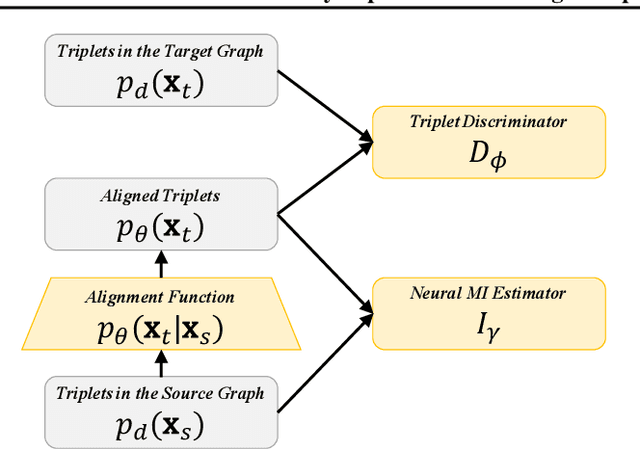


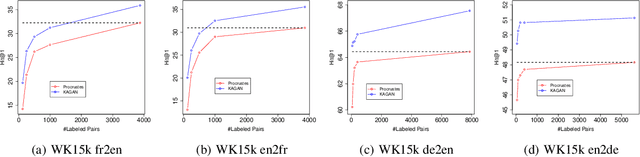
This paper studies aligning knowledge graphs from different sources or languages. Most existing methods train supervised methods for the alignment, which usually require a large number of aligned knowledge triplets. However, such a large number of aligned knowledge triplets may not be available or are expensive to obtain in many domains. Therefore, in this paper we propose to study aligning knowledge graphs in fully-unsupervised or weakly-supervised fashion, i.e., without or with only a few aligned triplets. We propose an unsupervised framework to align the entity and relation embddings of different knowledge graphs with an adversarial learning framework. Moreover, a regularization term which maximizes the mutual information between the embeddings of different knowledge graphs is used to mitigate the problem of mode collapse when learning the alignment functions. Such a framework can be further seamlessly integrated with existing supervised methods by utilizing a limited number of aligned triples as guidance. Experimental results on multiple datasets prove the effectiveness of our proposed approach in both the unsupervised and the weakly-supervised settings.
Probabilistic Logic Neural Networks for Reasoning
Jun 20, 2019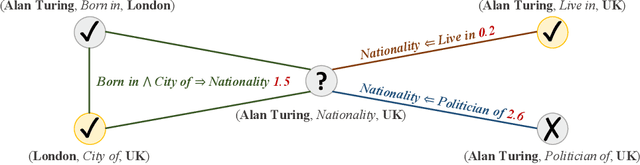
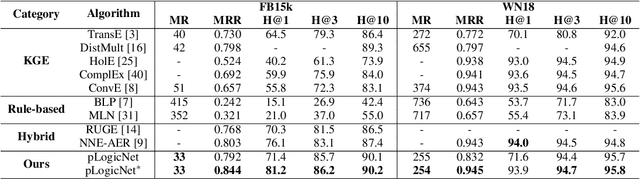
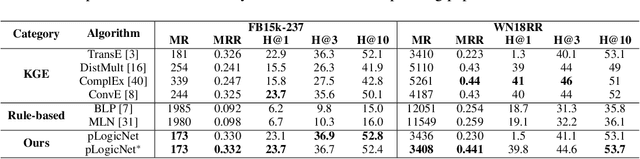

Knowledge graph reasoning, which aims at predicting the missing facts through reasoning with the observed facts, is critical to many applications. Such a problem has been widely explored by traditional logic rule-based approaches and recent knowledge graph embedding methods. A principled logic rule-based approach is the Markov Logic Network (MLN), which is able to leverage domain knowledge with first-order logic and meanwhile handle their uncertainty. However, the inference of MLNs is usually very difficult due to the complicated graph structures. Different from MLNs, knowledge graph embedding methods (e.g. TransE, DistMult) learn effective entity and relation embeddings for reasoning, which are much more effective and efficient. However, they are unable to leverage domain knowledge. In this paper, we propose the probabilistic Logic Neural Network (pLogicNet), which combines the advantages of both methods. A pLogicNet defines the joint distribution of all possible triplets by using a Markov logic network with first-order logic, which can be efficiently optimized with the variational EM algorithm. In the E-step, a knowledge graph embedding model is used for inferring the missing triplets, while in the M-step, the weights of logic rules are updated based on both the observed and predicted triplets. Experiments on multiple knowledge graphs prove the effectiveness of pLogicNet over many competitive baselines.