 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNS-RGS: Newton-Schulz based Riemannian gradient method for orthogonal group synchronization
Apr 07, 2026Group synchronization is a fundamental task involving the recovery of group elements from pairwise measurements. For orthogonal group synchronization, the most common approach reformulates the problem as a constrained nonconvex optimization and solves it using projection-based methods, such as the generalized power method. However, these methods rely on exact SVD or QR decompositions in each iteration, which are computationally expensive and become a bottleneck for large-scale problems. In this paper, we propose a Newton-Schulz-based Riemannian Gradient Scheme (NS-RGS) for orthogonal group synchronization that significantly reduces computational cost by replacing the SVD or QR step with the Newton-Schulz iteration. This approach leverages efficient matrix multiplications and aligns perfectly with modern GPU/TPU architectures. By employing a refined leave-one-out analysis, we overcome the challenge arising from statistical dependencies, and establish that NS-RGS with spectral initialization achieves linear convergence to the target solution up to near-optimal statistical noise levels. Experiments on synthetic data and real-world global alignment tasks demonstrate that NS-RGS attains accuracy comparable to state-of-the-art methods such as the generalized power method, while achieving nearly a 2$\times$ speedup.
Scaled Gradient Descent for Ill-Conditioned Low-Rank Matrix Recovery with Optimal Sampling Complexity
Mar 31, 2026The low-rank matrix recovery problem seeks to reconstruct an unknown $n_1 \times n_2$ rank-$r$ matrix from $m$ linear measurements, where $m\ll n_1n_2$. This problem has been extensively studied over the past few decades, leading to a variety of algorithms with solid theoretical guarantees. Among these, gradient descent based non-convex methods have become particularly popular due to their computational efficiency. However, these methods typically suffer from two key limitations: a sub-optimal sample complexity of $O((n_1 + n_2)r^2)$ and an iteration complexity of $O(κ\log(1/ε))$ to achieve $ε$-accuracy, resulting in slow convergence when the target matrix is ill-conditioned. Here, $κ$ denotes the condition number of the unknown matrix. Recent studies show that a preconditioned variant of GD, known as scaled gradient descent (ScaledGD), can significantly reduce the iteration complexity to $O(\log(1/ε))$. Nonetheless, its sample complexity remains sub-optimal at $O((n_1 + n_2)r^2)$. In contrast, a delicate virtual sequence technique demonstrates that the standard GD in the positive semidefinite (PSD) setting achieves the optimal sample complexity $O((n_1 + n_2)r)$, but converges more slowly with an iteration complexity $O(κ^2 \log(1/ε))$. In this paper, through a more refined analysis, we show that ScaledGD achieves both the optimal sample complexity $O((n_1 + n_2)r)$ and the improved iteration complexity $O(\log(1/ε))$. Notably, our results extend beyond the PSD setting to general low-rank matrix recovery problem. Numerical experiments further validate that ScaledGD accelerates convergence for ill-conditioned matrices with the optimal sampling complexity.
No existence of linear algorithm for Fourier phase retrieval
Sep 13, 2022Fourier phase retrieval, which seeks to reconstruct a signal from its Fourier magnitude, is of fundamental importance in fields of engineering and science. In this paper, we give a theoretical understanding of algorithms for Fourier phase retrieval. Particularly, we show if there exists an algorithm which could reconstruct an arbitrary signal ${\mathbf x}\in {\mathbb C}^N$ in $ \mbox{Poly}(N) \log(1/\epsilon)$ time to reach $\epsilon$-precision from its magnitude of discrete Fourier transform and its initial value $x(0)$, then $\mathcal{ P}=\mathcal{NP}$. This demystifies the phenomenon that, although almost all signals are determined uniquely by their Fourier magnitude with a prior conditions, there is no algorithm with theoretical guarantees being proposed over the past few decades. Our proofs employ the result in computational complexity theory that Product Partition problem is NP-complete in the strong sense.
"Let Your Characters Tell Their Story": A Dataset for Character-Centric Narrative Understanding
Sep 12, 2021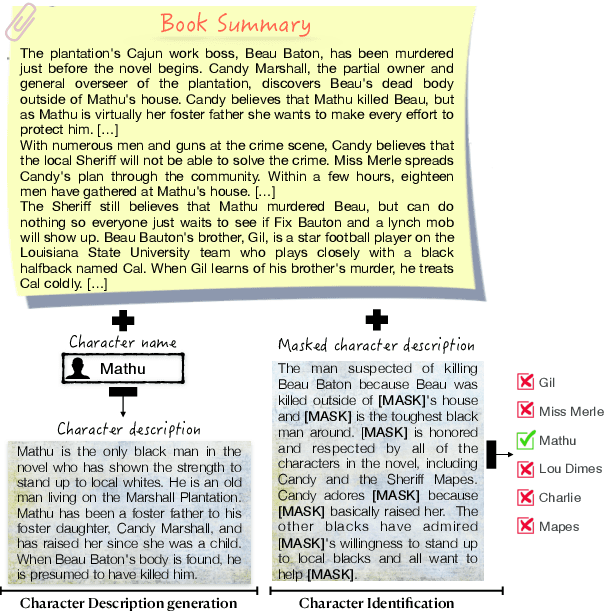
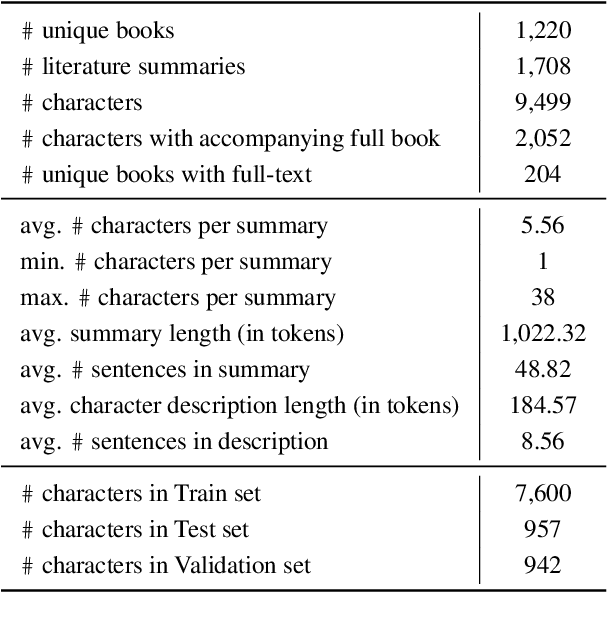
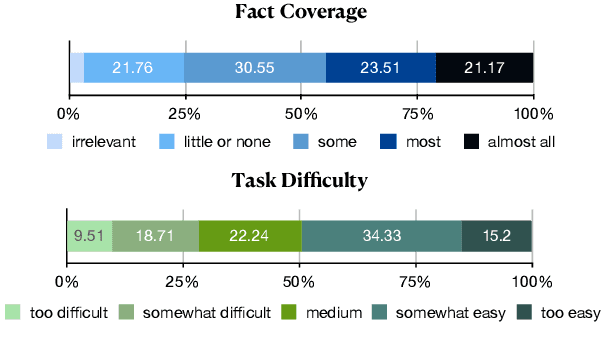
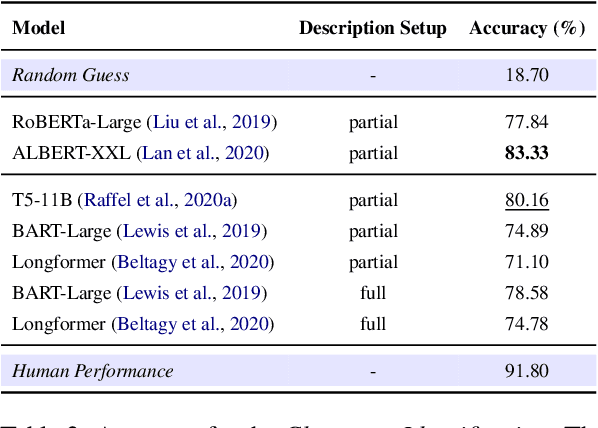
When reading a literary piece, readers often make inferences about various characters' roles, personalities, relationships, intents, actions, etc. While humans can readily draw upon their past experiences to build such a character-centric view of the narrative, understanding characters in narratives can be a challenging task for machines. To encourage research in this field of character-centric narrative understanding, we present LiSCU -- a new dataset of literary pieces and their summaries paired with descriptions of characters that appear in them. We also introduce two new tasks on LiSCU: Character Identification and Character Description Generation. Our experiments with several pre-trained language models adapted for these tasks demonstrate that there is a need for better models of narrative comprehension.