 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaled Gradient Descent for Ill-Conditioned Low-Rank Matrix Recovery with Optimal Sampling Complexity
Mar 31, 2026The low-rank matrix recovery problem seeks to reconstruct an unknown $n_1 \times n_2$ rank-$r$ matrix from $m$ linear measurements, where $m\ll n_1n_2$. This problem has been extensively studied over the past few decades, leading to a variety of algorithms with solid theoretical guarantees. Among these, gradient descent based non-convex methods have become particularly popular due to their computational efficiency. However, these methods typically suffer from two key limitations: a sub-optimal sample complexity of $O((n_1 + n_2)r^2)$ and an iteration complexity of $O(κ\log(1/ε))$ to achieve $ε$-accuracy, resulting in slow convergence when the target matrix is ill-conditioned. Here, $κ$ denotes the condition number of the unknown matrix. Recent studies show that a preconditioned variant of GD, known as scaled gradient descent (ScaledGD), can significantly reduce the iteration complexity to $O(\log(1/ε))$. Nonetheless, its sample complexity remains sub-optimal at $O((n_1 + n_2)r^2)$. In contrast, a delicate virtual sequence technique demonstrates that the standard GD in the positive semidefinite (PSD) setting achieves the optimal sample complexity $O((n_1 + n_2)r)$, but converges more slowly with an iteration complexity $O(κ^2 \log(1/ε))$. In this paper, through a more refined analysis, we show that ScaledGD achieves both the optimal sample complexity $O((n_1 + n_2)r)$ and the improved iteration complexity $O(\log(1/ε))$. Notably, our results extend beyond the PSD setting to general low-rank matrix recovery problem. Numerical experiments further validate that ScaledGD accelerates convergence for ill-conditioned matrices with the optimal sampling complexity.
Reinforcement Learning from Demonstrations by Novel Interactive Expert and Application to Automatic Berthing Control Systems for Unmanned Surface Vessel
Feb 23, 2022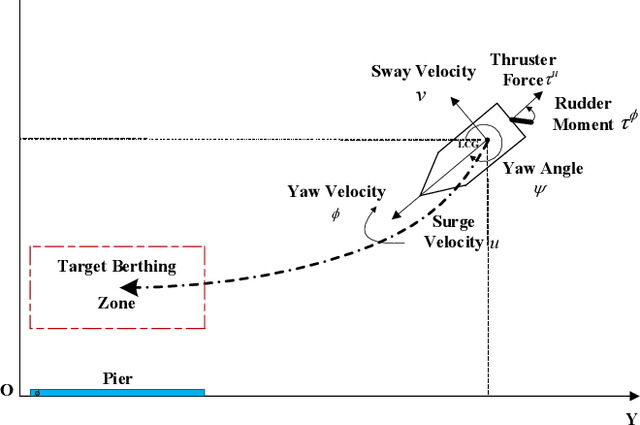
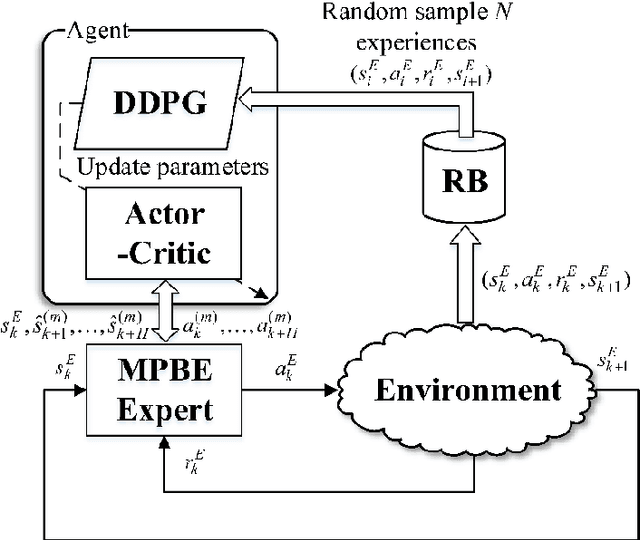
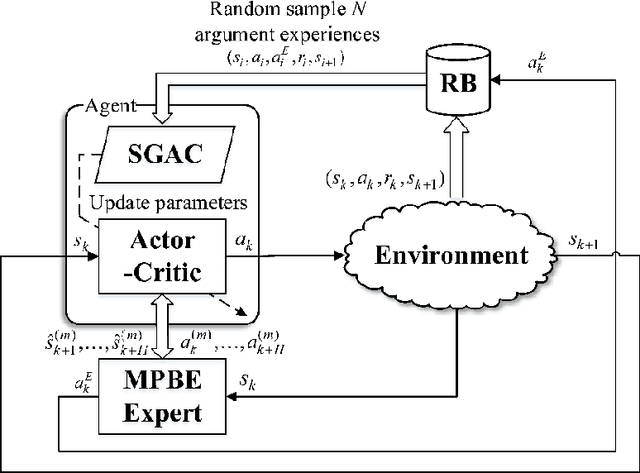
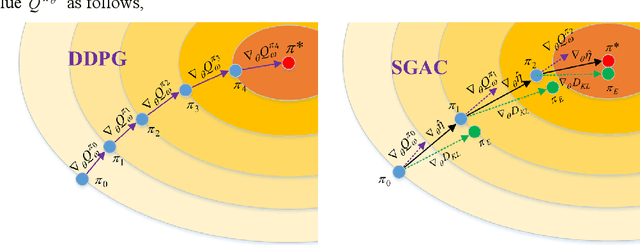
In this paper, two novel practical methods of Reinforcement Learning from Demonstration (RLfD) are developed and applied to automatic berthing control systems for Unmanned Surface Vessel. A new expert data generation method, called Model Predictive Based Expert (MPBE) which combines Model Predictive Control and Deep Deterministic Policy Gradient, is developed to provide high quality supervision data for RLfD algorithms. A straightforward RLfD method, model predictive Deep Deterministic Policy Gradient (MP-DDPG), is firstly introduced by replacing the RL agent with MPBE to directly interact with the environment. Then distribution mismatch problem is analyzed for MP-DDPG, and two techniques that alleviate distribution mismatch are proposed. Furthermore, another novel RLfD algorithm based on the MP-DDPG, called Self-Guided Actor-Critic (SGAC) is present, which can effectively leverage MPBE by continuously querying it to generate high quality expert data online. The distribution mismatch problem leading to unstable learning process is addressed by SGAC in a DAgger manner. In addition, theoretical analysis is given to prove that SGAC algorithm can converge with guaranteed monotonic improvement. Simulation results verify the effectiveness of MP-DDPG and SGAC to accomplish the ship berthing control task, and show advantages of SGAC comparing with other typical reinforcement learning algorithms and MP-DDPG.