 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat the Eyes See, the LLMs Miss: Exploiting Human Perception for Adversarial Text Attacks
Jun 08, 2026Large language model (LLM)-powered content moderation systems have become a critical defense against harmful online content. However, these systems primarily operate on tokenized text and largely ignore the visual cues that humans naturally rely on when interpreting content. We show that this discrepancy creates a fundamental perceptual mismatch: content that is readily recognized as harmful by humans can become effectively invisible to automated moderation systems. To study this vulnerability, we introduce a class of Human-Perceptible Adversarial Attacks (HPAA), in which harmful expressions are embedded into otherwise benign text through visually salient typographic manipulations. Our key insight is that typographic features, including spacing, visual emphasis, and spatial arrangement, can be strategically combined to preserve human recognition of harmful content while substantially reducing machine detectability. Operating in black-box settings with only a small query budget, our attack automatically generates evasive content without requiring model access or gradient information. We evaluate the attack across multiple datasets and ten deployed moderation systems, including commercial APIs and state-of-the-art open-source guardrails. Results reveal a striking gap between human and machine perception: with only three detector queries, generated attacks achieve over 86\% human recognition while maintaining detection rates below 1\% across the evaluated systems. We further conduct ablation studies to identify the typographic factors driving successful evasion, analyze why current moderation architectures fail to capture these signals, and discuss practical defenses. Our findings expose a fundamental blind spot in today's LLM-based moderation ecosystem and highlight need for moderation systems that reason about content in a manner more consistent with human perceptual understanding.
Universally Harmonizing Differential Privacy Mechanisms for Federated Learning: Boosting Accuracy and Convergence
Jul 24, 2024



Differentially private federated learning (DP-FL) is a promising technique for collaborative model training while ensuring provable privacy for clients. However, optimizing the tradeoff between privacy and accuracy remains a critical challenge. To our best knowledge, we propose the first DP-FL framework (namely UDP-FL), which universally harmonizes any randomization mechanism (e.g., an optimal one) with the Gaussian Moments Accountant (viz. DP-SGD) to significantly boost accuracy and convergence. Specifically, UDP-FL demonstrates enhanced model performance by mitigating the reliance on Gaussian noise. The key mediator variable in this transformation is the R\'enyi Differential Privacy notion, which is carefully used to harmonize privacy budgets. We also propose an innovative method to theoretically analyze the convergence for DP-FL (including our UDP-FL ) based on mode connectivity analysis. Moreover, we evaluate our UDP-FL through extensive experiments benchmarked against state-of-the-art (SOTA) methods, demonstrating superior performance on both privacy guarantees and model performance. Notably, UDP-FL exhibits substantial resilience against different inference attacks, indicating a significant advance in safeguarding sensitive data in federated learning environments.
DPOAD: Differentially Private Outsourcing of Anomaly Detection through Iterative Sensitivity Learning
Jun 27, 2022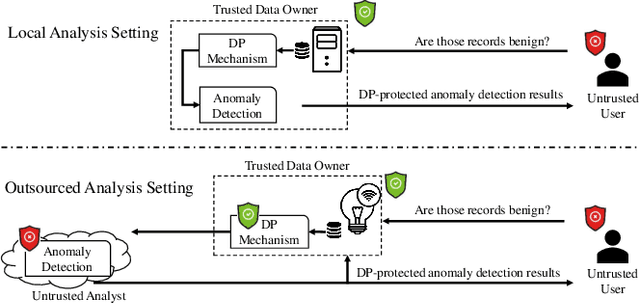
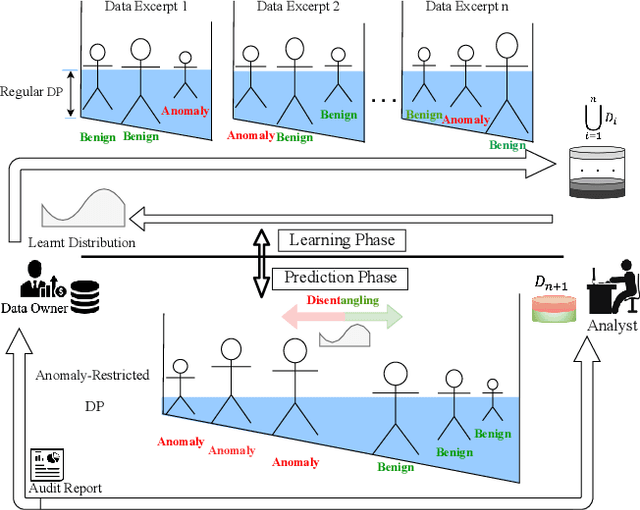
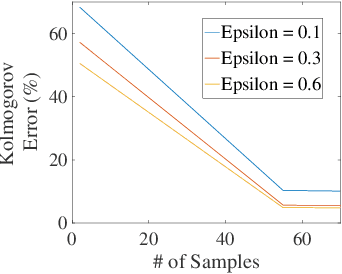
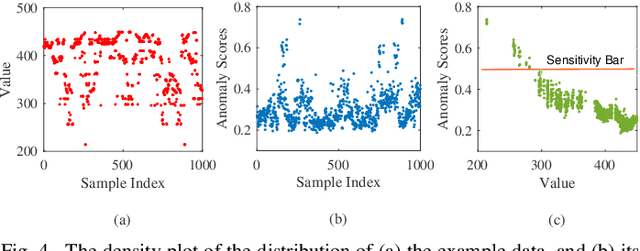
Outsourcing anomaly detection to third-parties can allow data owners to overcome resource constraints (e.g., in lightweight IoT devices), facilitate collaborative analysis (e.g., under distributed or multi-party scenarios), and benefit from lower costs and specialized expertise (e.g., of Managed Security Service Providers). Despite such benefits, a data owner may feel reluctant to outsource anomaly detection without sufficient privacy protection. To that end, most existing privacy solutions would face a novel challenge, i.e., preserving privacy usually requires the difference between data entries to be eliminated or reduced, whereas anomaly detection critically depends on that difference. Such a conflict is recently resolved under a local analysis setting with trusted analysts (where no outsourcing is involved) through moving the focus of differential privacy (DP) guarantee from "all" to only "benign" entries. In this paper, we observe that such an approach is not directly applicable to the outsourcing setting, because data owners do not know which entries are "benign" prior to outsourcing, and hence cannot selectively apply DP on data entries. Therefore, we propose a novel iterative solution for the data owner to gradually "disentangle" the anomalous entries from the benign ones such that the third-party analyst can produce accurate anomaly results with sufficient DP guarantee. We design and implement our Differentially Private Outsourcing of Anomaly Detection (DPOAD) framework, and demonstrate its benefits over baseline Laplace and PainFree mechanisms through experiments with real data from different application domains.