 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianGrasper: 3D Language Gaussian Splatting for Open-vocabulary Robotic Grasping
Mar 14, 2024



Constructing a 3D scene capable of accommodating open-ended language queries, is a pivotal pursuit, particularly within the domain of robotics. Such technology facilitates robots in executing object manipulations based on human language directives. To tackle this challenge, some research efforts have been dedicated to the development of language-embedded implicit fields. However, implicit fields (e.g. NeRF) encounter limitations due to the necessity of processing a large number of input views for reconstruction, coupled with their inherent inefficiencies in inference. Thus, we present the GaussianGrasper, which utilizes 3D Gaussian Splatting to explicitly represent the scene as a collection of Gaussian primitives. Our approach takes a limited set of RGB-D views and employs a tile-based splatting technique to create a feature field. In particular, we propose an Efficient Feature Distillation (EFD) module that employs contrastive learning to efficiently and accurately distill language embeddings derived from foundational models. With the reconstructed geometry of the Gaussian field, our method enables the pre-trained grasping model to generate collision-free grasp pose candidates. Furthermore, we propose a normal-guided grasp module to select the best grasp pose. Through comprehensive real-world experiments, we demonstrate that GaussianGrasper enables robots to accurately query and grasp objects with language instructions, providing a new solution for language-guided manipulation tasks. Data and codes can be available at https://github.com/MrSecant/GaussianGrasper.
Chi-square Loss for Softmax: an Echo of Neural Network Structure
Aug 31, 2021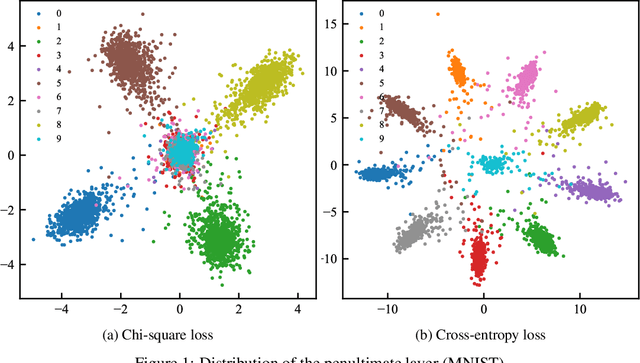
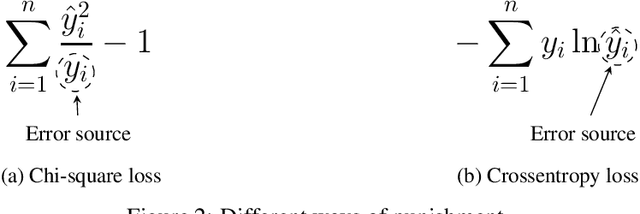
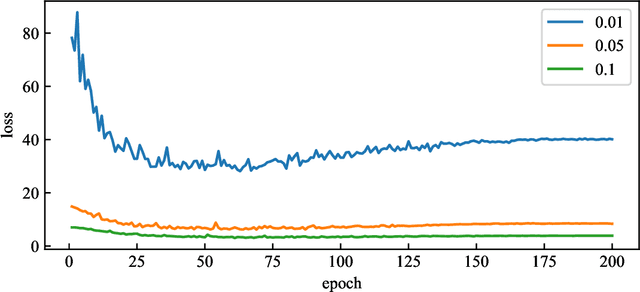
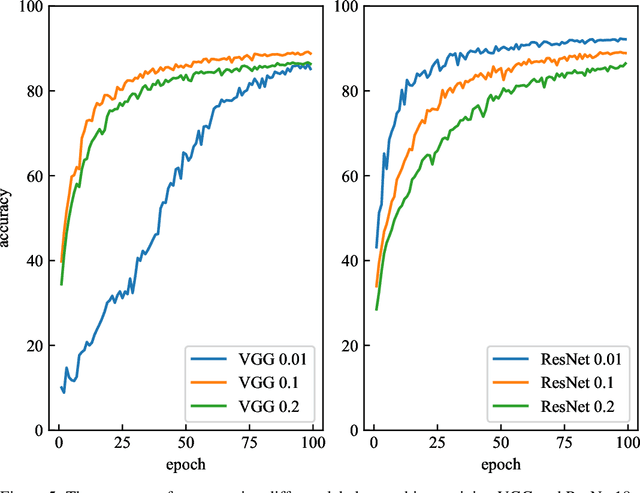
Softmax working with cross-entropy is widely used in classification, which evaluates the similarity between two discrete distribution columns (predictions and true labels). Inspired by chi-square test, we designed a new loss function called chi-square loss, which is also works for Softmax. Chi-square loss has a statistical background. We proved that it is unbiased in optimization, and clarified its using conditions (its formula determines that it must work with label smoothing). In addition, we studied the sample distribution of this loss function by visualization and found that the distribution is related to the neural network structure, which is distinct compared to cross-entropy. In the past, the influence of structure was often ignored when visualizing. Chi-square loss can notice changes in neural network structure because it is very strict, and we explained the reason for this strictness. We also studied the influence of label smoothing and discussed the relationship between label smoothing and training accuracy and stability. Since the chi-square loss is very strict, the performance will degrade when dealing samples of very many classes.