 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIFT: LLM-Guided State-Reward Interface for Financial Reinforcement Learning
Jun 07, 2026Financial portfolio trading is naturally formulated as a reinforcement learning problem, where an agent sequentially rebalances assets under changing market conditions to balance return, risk, and transaction costs. Yet in non-stationary markets, raw OHLCV states and short-horizon return rewards often provide an under-specified learning interface, motivating large language models as a way to inject financial knowledge into state and reward design while constraining open-ended generation. To this end, we propose GIFT, an LLM-guided framework for state-reward interface design in PPO-based financial reinforcement learning. Rather than using the LLM to make trading decisions, GIFT uses Factor-guided State Enhancement to generate state features from financial-factor primitives, Risk-rule-guided Reward Shaping to generate auxiliary rewards from portfolio-risk rules, and Diagnostic-guided Refinement to revise candidate interfaces using PPO rollout diagnostics. After refinement, GIFT fixes the selected state-reward interface before evaluation, with no further LLM queries or interface updates at test time. Comprehensive rolling-window experiments across diverse market regimes and portfolio scenarios demonstrate that GIFT improves learning-signal quality and out-of-sample risk-adjusted portfolio performance over baselines. Code and data are available at: https://github.com/KAG778/GIFT .
Feature-based Recognition Framework for Super-resolution Images
Dec 04, 2021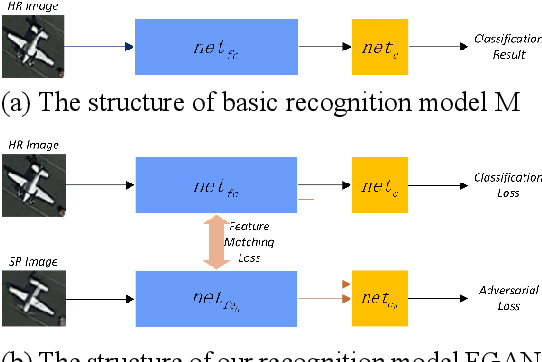
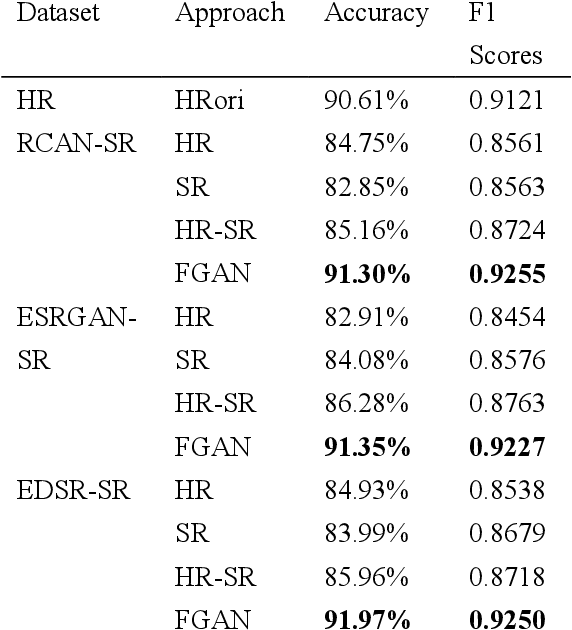

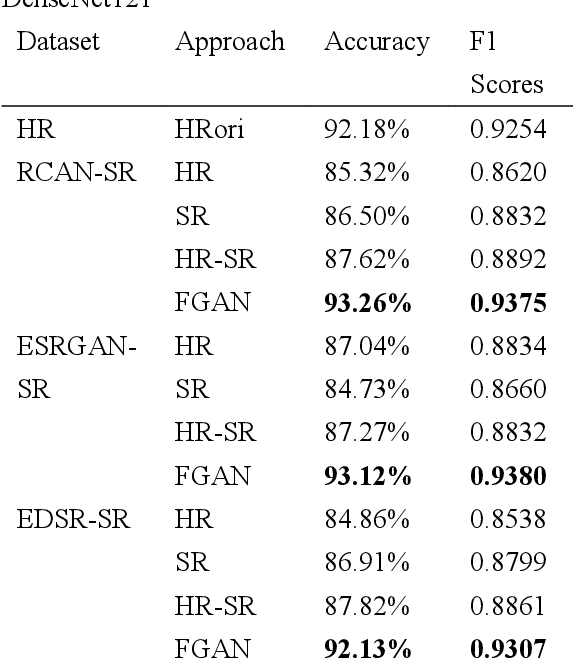
In practical application, the performance of recognition network usually decreases when being applied on super-resolution images. In this paper, we propose a feature-based recognition network combined with GAN (FGAN). Our network improves the recognition accuracy by extracting more features that benefit recognition from SR images. In the experiment, we build three datasets using three different super-resolution algorithm, and our network increases the recognition accuracy by more than 6% comparing with ReaNet50 and DenseNet121.