 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked and Predictive Self-Supervised Foundation Models for 3D Brain MRI
Jun 11, 2026Self-supervised foundation models have shown strong promise in medical imaging. However, existing MRI foundation-model studies have primarily emphasized segmentation and dense prediction tasks, while systematic investigation of self-supervised foundation models for MRI-based disease detection remains limited. In this work, we investigate two major self-supervised pretraining paradigms for MRI-based disease detection: reconstruction-based learning via Masked Autoencoders (MAE) and predictive representation learning via Joint Embedding Predictive Architectures (JEPA). We study the role of auxiliary objectives by introducing a novel spectral-domain reconstruction loss for MAE to enhance sensitivity to fine-grained anatomical structure, and by integrating variance--covariance regularization (VCR) within our JEPA framework to encourage decorrelated latent representations. Our models are pretrained on heterogeneous single-contrast MRI volumes in a contrast-agnostic setting, without modality concatenation. Across five downstream disease detection tasks, our results highlight the importance of self-supervised objective design for medical foundation model pretraining, demonstrating that the downstream benefit of each objective is determined by its relevance to the task's structure. Specifically, spectral regularization yields the largest improvements when the downstream discriminative signal is characterized by strong high-frequency anatomical structures, while covariance regularization is most beneficial when discriminative information spans multiple decorrelated feature dimensions. MAE with spectral-domain supervision consistently achieves superior downstream performance for MRI-based disease detection. These findings suggest that self-supervised objectives in medical imaging encode specific biases, and their downstream benefit is fundamentally conditioned on the task's structure.
GAN-based Intrinsic Exploration For Sample Efficient Reinforcement Learning
Jun 28, 2022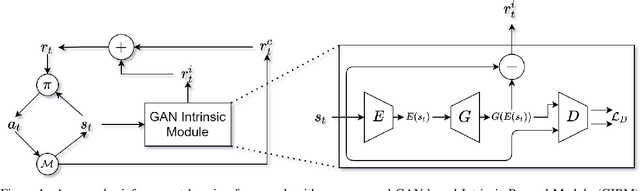

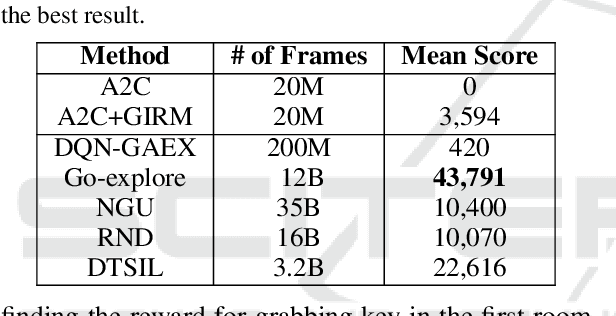

In this study, we address the problem of efficient exploration in reinforcement learning. Most common exploration approaches depend on random action selection, however these approaches do not work well in environments with sparse or no rewards. We propose Generative Adversarial Network-based Intrinsic Reward Module that learns the distribution of the observed states and sends an intrinsic reward that is computed as high for states that are out of distribution, in order to lead agent to unexplored states. We evaluate our approach in Super Mario Bros for a no reward setting and in Montezuma's Revenge for a sparse reward setting and show that our approach is indeed capable of exploring efficiently. We discuss a few weaknesses and conclude by discussing future works.
CHAOS Challenge -- Combined (CT-MR) Healthy Abdominal Organ Segmentation
Jan 17, 2020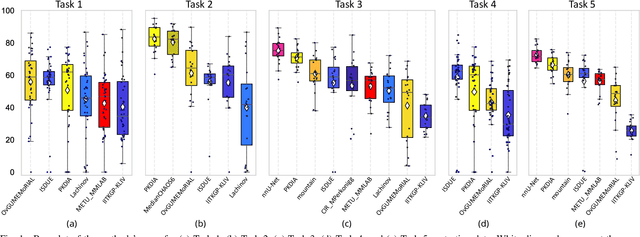
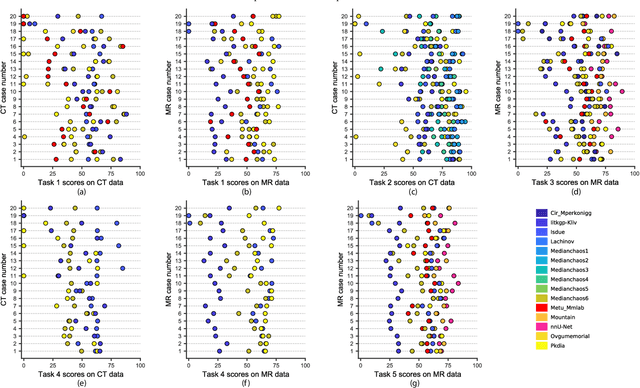
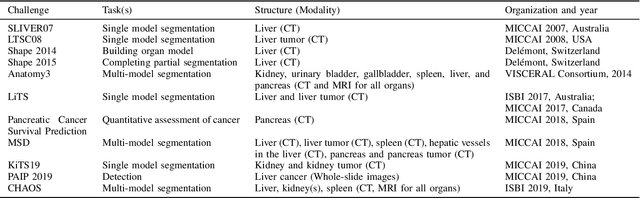
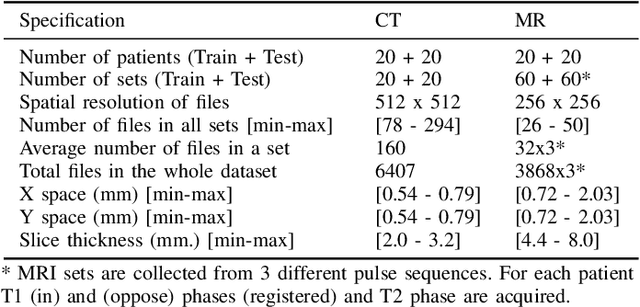
Segmentation of abdominal organs has been a comprehensive, yet unresolved, research field for many years. In the last decade, intensive developments in deep learning (DL) have introduced new state-of-the-art segmentation systems. Despite outperforming the overall accuracy of existing systems, the effects of DL model properties and parameters on the performance is hard to interpret. This makes comparative analysis a necessary tool to achieve explainable studies and systems. Moreover, the performance of DL for emerging learning approaches such as cross-modality and multi-modal tasks have been rarely discussed. In order to expand the knowledge in these topics, CHAOS -- Combined (CT-MR) Healthy Abdominal Organ Segmentation challenge has been organized in the IEEE International Symposium on Biomedical Imaging (ISBI), 2019, in Venice, Italy. Despite a large number of the previous abdomen related challenges, the majority of which are focused on tumor/lesion detection and/or classification with a single modality, CHAOS provides both abdominal CT and MR data from healthy subjects. Five different and complementary tasks have been designed to analyze the capabilities of the current approaches from multiple perspectives. The results are investigated thoroughly, compared with manual annotations and interactive methods. The outcomes are reported in detail to reflect the latest advancements in the field. CHAOS challenge and data will be available online to provide a continuous benchmark resource for segmentation.
Multi Modal Convolutional Neural Networks for Brain Tumor Segmentation
Sep 20, 2018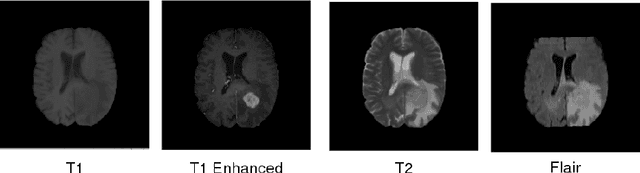

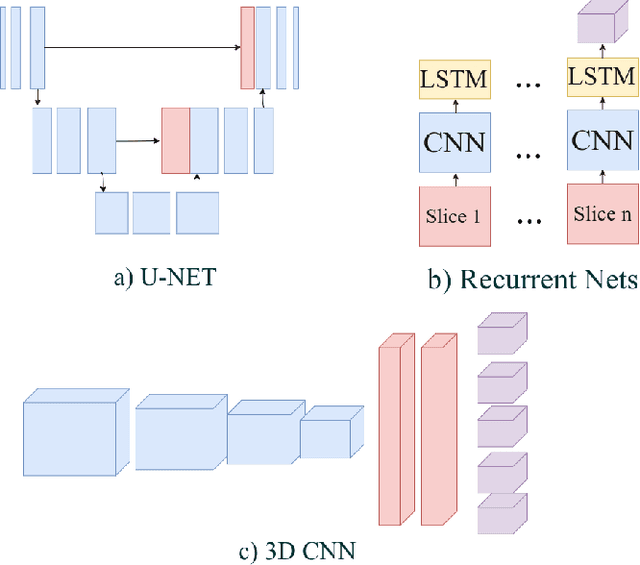
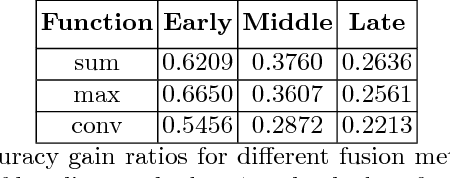
In this work, we propose a multi-modal Convolutional Neural Network (CNN) approach for brain tumor segmentation. We investigate how to combine different modalities efficiently in the CNN framework.We adapt various fusion methods, which are previously employed on video recognition problem, to the brain tumor segmentation problem,and we investigate their efficiency in terms of memory and performance.Our experiments, which are performed on BRATS dataset, lead us to the conclusion that learning separate representations for each modality and combining them for brain tumor segmentation could increase the performance of CNN systems.