 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompetition, Alignment, and Equilibria in Digital Marketplaces
Aug 30, 2022
Competition between traditional platforms is known to improve user utility by aligning the platform's actions with user preferences. But to what extent is alignment exhibited in data-driven marketplaces? To study this question from a theoretical perspective, we introduce a duopoly market where platform actions are bandit algorithms and the two platforms compete for user participation. A salient feature of this market is that the quality of recommendations depends on both the bandit algorithm and the amount of data provided by interactions from users. This interdependency between the algorithm performance and the actions of users complicates the structure of market equilibria and their quality in terms of user utility. Our main finding is that competition in this market does not perfectly align market outcomes with user utility. Interestingly, market outcomes exhibit misalignment not only when the platforms have separate data repositories, but also when the platforms have a shared data repository. Nonetheless, the data sharing assumptions impact what mechanism drives misalignment and also affect the specific form of misalignment (e.g. the quality of the best-case and worst-case market outcomes). More broadly, our work illustrates that competition in digital marketplaces has subtle consequences for user utility that merit further investigation.
Supply-Side Equilibria in Recommender Systems
Jun 27, 2022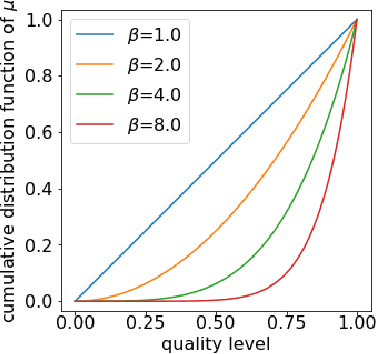
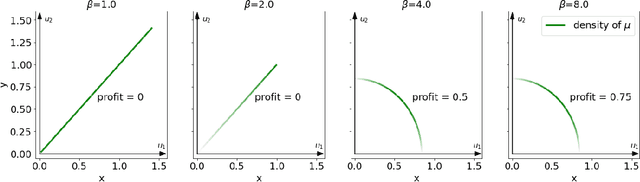
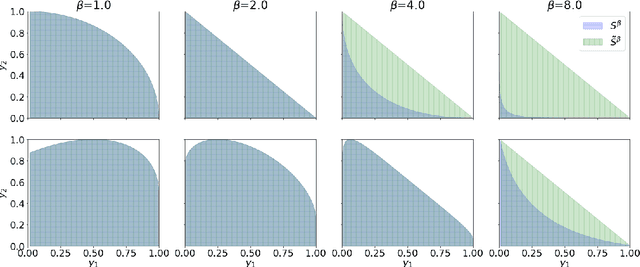
Digital recommender systems such as Spotify and Netflix affect not only consumer behavior but also producer incentives: producers seek to supply content that will be recommended by the system. But what content will be produced? In this paper, we investigate the supply-side equilibria in content recommender systems. We model users and content as $D$-dimensional vectors, and recommend the content that has the highest dot product with each user. The main features of our model are that the producer decision space is high-dimensional and the user base is heterogeneous. This gives rise to new qualitative phenomena at equilibrium: First, the formation of genres, where producers specialize to compete for subsets of users. Using a duality argument, we derive necessary and sufficient conditions for this specialization to occur. Second, we show that producers can achieve positive profit at equilibrium, which is typically impossible under perfect competition. We derive sufficient conditions for this to occur, and show it is closely connected to specialization of content. In both results, the interplay between the geometry of the users and the structure of producer costs influences the structure of the supply-side equilibria. At a conceptual level, our work serves as a starting point to investigate how recommender systems shape supply-side competition between producers.
Performative Power
Mar 31, 2022
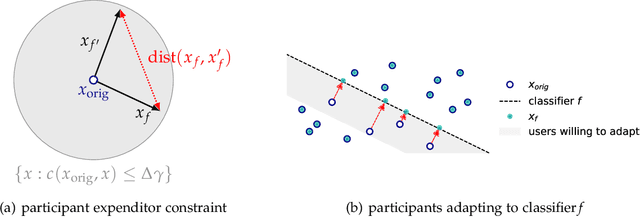
We introduce the notion of performative power, which measures the ability of a firm operating an algorithmic system, such as a digital content recommendation platform, to steer a population. We relate performative power to the economic theory of market power. Traditional economic concepts are well known to struggle with identifying anti-competitive patterns in digital platforms--a core challenge is the difficulty of defining the market, its participants, products, and prices. Performative power sidesteps the problem of market definition by focusing on a directly observable statistical measure instead. High performative power enables a platform to profit from steering participant behavior, whereas low performative power ensures that learning from historical data is close to optimal. Our first general result shows that under low performative power, a firm cannot do better than standard supervised learning on observed data. We draw an analogy with a firm being a price-taker, an economic condition that arises under perfect competition in classical market models. We then contrast this with a market where performative power is concentrated and show that the equilibrium state can differ significantly. We go on to study performative power in a concrete setting of strategic classification where participants can switch between competing firms. We show that monopolies maximize performative power and disutility for the participant, while competition and outside options decrease performative power. We end on a discussion of connections to measures of market power in economics and of the relationship with ongoing antitrust debates.
Regret Minimization with Performative Feedback
Feb 01, 2022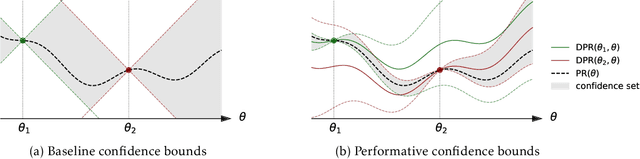
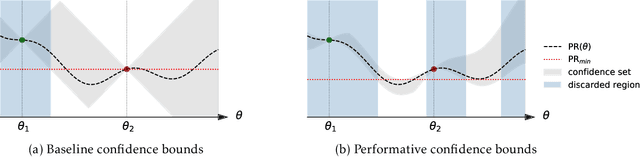
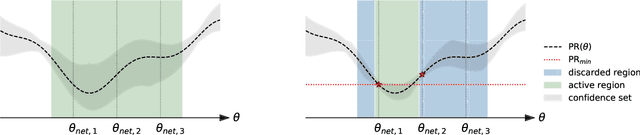
In performative prediction, the deployment of a predictive model triggers a shift in the data distribution. As these shifts are typically unknown ahead of time, the learner needs to deploy a model to get feedback about the distribution it induces. We study the problem of finding near-optimal models under performativity while maintaining low regret. On the surface, this problem might seem equivalent to a bandit problem. However, it exhibits a fundamentally richer feedback structure that we refer to as performative feedback: after every deployment, the learner receives samples from the shifted distribution rather than only bandit feedback about the reward. Our main contribution is regret bounds that scale only with the complexity of the distribution shifts and not that of the reward function. The key algorithmic idea is careful exploration of the distribution shifts that informs a novel construction of confidence bounds on the risk of unexplored models. The construction only relies on smoothness of the shifts and does not assume convexity. More broadly, our work establishes a conceptual approach for leveraging tools from the bandits literature for the purpose of regret minimization with performative feedback.
Learning Equilibria in Matching Markets from Bandit Feedback
Aug 19, 2021
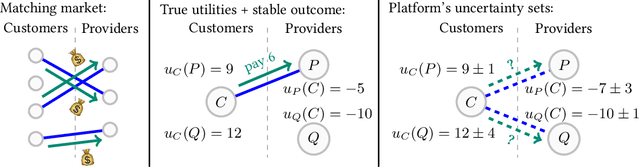
Large-scale, two-sided matching platforms must find market outcomes that align with user preferences while simultaneously learning these preferences from data. However, since preferences are inherently uncertain during learning, the classical notion of stability (Gale and Shapley, 1962; Shapley and Shubik, 1971) is unattainable in these settings. To bridge this gap, we develop a framework and algorithms for learning stable market outcomes under uncertainty. Our primary setting is matching with transferable utilities, where the platform both matches agents and sets monetary transfers between them. We design an incentive-aware learning objective that captures the distance of a market outcome from equilibrium. Using this objective, we analyze the complexity of learning as a function of preference structure, casting learning as a stochastic multi-armed bandit problem. Algorithmically, we show that "optimism in the face of uncertainty," the principle underlying many bandit algorithms, applies to a primal-dual formulation of matching with transfers and leads to near-optimal regret bounds. Our work takes a first step toward elucidating when and how stable matchings arise in large, data-driven marketplaces.
Alternative Microfoundations for Strategic Classification
Jun 24, 2021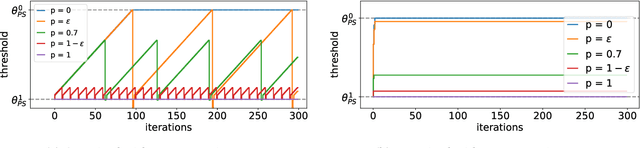
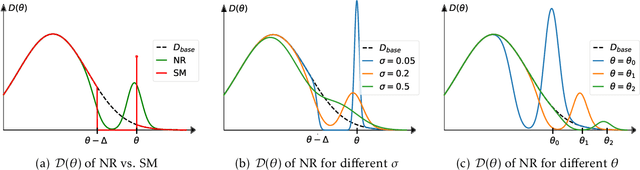
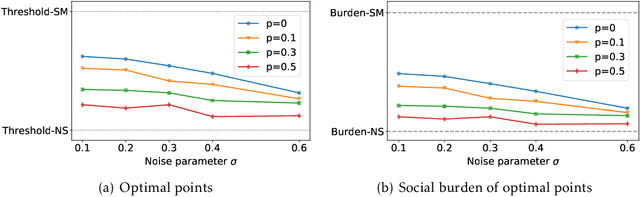
When reasoning about strategic behavior in a machine learning context it is tempting to combine standard microfoundations of rational agents with the statistical decision theory underlying classification. In this work, we argue that a direct combination of these standard ingredients leads to brittle solution concepts of limited descriptive and prescriptive value. First, we show that rational agents with perfect information produce discontinuities in the aggregate response to a decision rule that we often do not observe empirically. Second, when any positive fraction of agents is not perfectly strategic, desirable stable points -- where the classifier is optimal for the data it entails -- cease to exist. Third, optimal decision rules under standard microfoundations maximize a measure of negative externality known as social burden within a broad class of possible assumptions about agent behavior. Recognizing these limitations we explore alternatives to standard microfoundations for binary classification. We start by describing a set of desiderata that help navigate the space of possible assumptions about how agents respond to a decision rule. In particular, we analyze a natural constraint on feature manipulations, and discuss properties that are sufficient to guarantee the robust existence of stable points. Building on these insights, we then propose the noisy response model. Inspired by smoothed analysis and empirical observations, noisy response incorporates imperfection in the agent responses, which we show mitigates the limitations of standard microfoundations. Our model retains analytical tractability, leads to more robust insights about stable points, and imposes a lower social burden at optimality.
Inductive Bias of Multi-Channel Linear Convolutional Networks with Bounded Weight Norm
Feb 24, 2021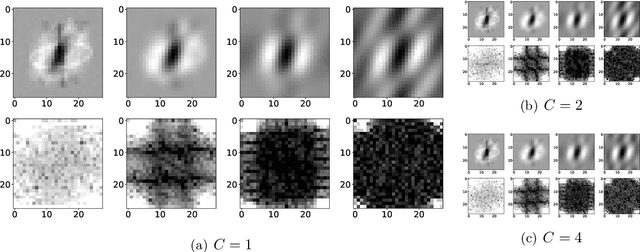
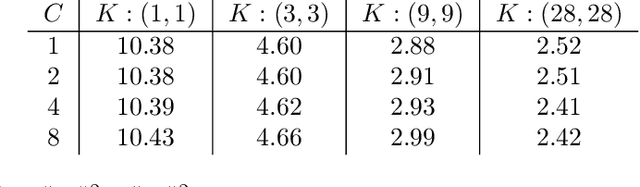

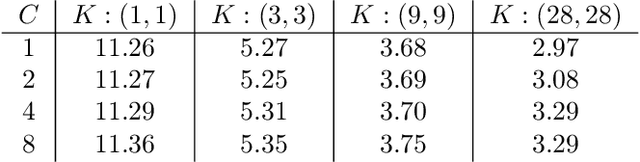
We study the function space characterization of the inductive bias resulting from controlling the $\ell_2$ norm of the weights in linear convolutional networks. We view this in terms of an induced regularizer in the function space given by the minimum norm of weights required to realize a linear function. For two layer linear convolutional networks with $C$ output channels and kernel size $K$, we show the following: (a) If the inputs to the network have a single channel, the induced regularizer for any $K$ is a norm given by a semidefinite program (SDP) that is independent of the number of output channels $C$. We further validate these results through a binary classification task on MNIST. (b) In contrast, for networks with multi-channel inputs, multiple output channels can be necessary to merely realize all matrix-valued linear functions and thus the inductive bias does depend on $C$. Further, for sufficiently large $C$, the induced regularizer for $K=1$ and $K=D$ are the nuclear norm and the $\ell_{2,1}$ group-sparse norm, respectively, of the Fourier coefficients -- both of which promote sparse structures.
Individual Fairness in Pipelines
Apr 12, 2020

It is well understood that a system built from individually fair components may not itself be individually fair. In this work, we investigate individual fairness under pipeline composition. Pipelines differ from ordinary sequential or repeated composition in that individuals may drop out at any stage, and classification in subsequent stages may depend on the remaining "cohort" of individuals. As an example, a company might hire a team for a new project and at a later point promote the highest performer on the team. Unlike other repeated classification settings, where the degree of unfairness degrades gracefully over multiple fair steps, the degree of unfairness in pipelines can be arbitrary, even in a pipeline with just two stages. Guided by a panoply of real-world examples, we provide a rigorous framework for evaluating different types of fairness guarantees for pipelines. We show that na\"{i}ve auditing is unable to uncover systematic unfairness and that, in order to ensure fairness, some form of dependence must exist between the design of algorithms at different stages in the pipeline. Finally, we provide constructions that permit flexibility at later stages, meaning that there is no need to lock in the entire pipeline at the time that the early stage is constructed.
Fairness in ad auctions through inverse proportionality
Mar 31, 2020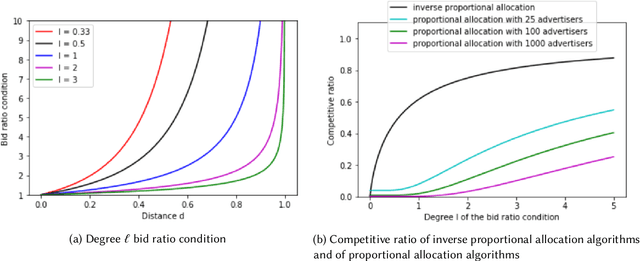
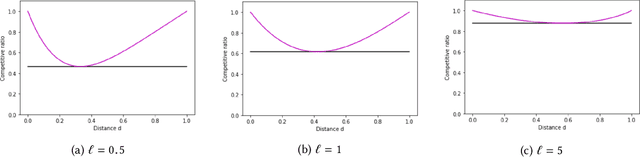
We study the tradeoff between social welfare maximization and fairness in the context of ad auctions. We study an ad auction setting where users arrive in an online fashion, $k$ advertisers submit bids for each user, and the auction assigns a distribution over ads to the user. Following the works of Dwork and Ilvento (2019) and Chawla et al. (2020), our goal is to design a truthful auction that satisfies multiple-task fairness in its outcomes: informally speaking, users that are similar to each other should obtain similar allocations of ads. We develop a new class of allocation algorithms that we call inverse-proportional allocation. These allocation algorithms are truthful, online, and do not explicitly need to know the fairness constraint over the users. In terms of fairness, they guarantee fair outcomes as long as every advertiser's bids are non-discriminatory across users. In terms of social welfare, inverse-proportional allocation achieves a constant factor approximation in social welfare against the optimal (unfair) allocation, independent of the number of advertisers in the system. In this respect, these allocation algorithms greatly surpass the guarantees achieved in previous work; in fact, they achieve the optimal tradeoffs between fairness and social welfare in some contexts. We also extend our results to broader notions of fairness that we call subset fairness.
Individual Fairness in Sponsored Search Auctions
Jun 20, 2019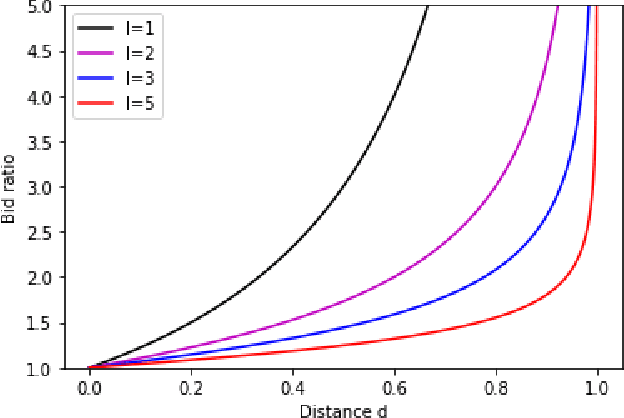

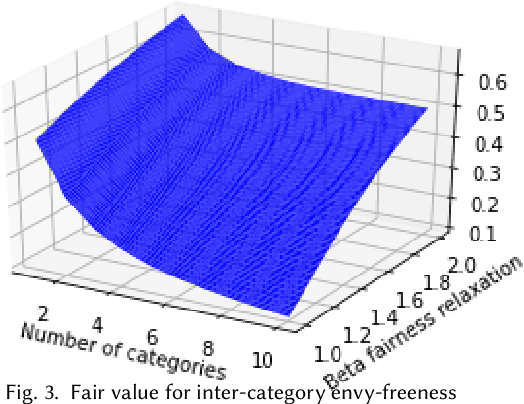
Fairness in advertising is a topic of particular interest in both the computer science and economics literatures, supported by theoretical and empirical observations. We initiate the study of tradeoffs between individual fairness and performance in online advertising, where advertisers place bids on ad slots for each user and the platform must determine which ads to display. Our main focus is to investigate the "cost of fairness": more specifically, whether a fair allocation mechanism can achieve utility close to that of a utility-optimal unfair mechanism. Motivated by practice, we consider both the case of many advertisers in a single category, e.g. sponsored results on a job search website, and ads spanning multiple categories, e.g. personalized display advertising on a social networking site, and show the tradeoffs are inherently different in these settings. We prove lower and upper bounds on the cost of fairness for each of these settings. For the single category setting, we show constraints on the "fairness" of advertisers' bids are necessary to achieve good utility. Moreover, with bid fairness constraints, we construct a mechanism that simultaneously achieves a high utility and a strengthening of typical fairness constraints that we call total variation fairness. For the multiple category setting, we show that fairness relaxations are necessary to achieve good utility. We consider a relaxed definition based on user-specified category preferences that we call user-directed fairness, and we show that with this fairness notion a high utility is achievable. Finally, we show that our mechanisms in the single and multiple category settings compose well, yielding a high utility combined mechanism that satisfies user-directed fairness across categories and conditional total variation fairness within categories.