 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Conformal Prediction under Data Heterogeneity
Dec 25, 2023



Conformal Prediction (CP) stands out as a robust framework for uncertainty quantification, which is crucial for ensuring the reliability of predictions. However, common CP methods heavily rely on data exchangeability, a condition often violated in practice. Existing approaches for tackling non-exchangeability lead to methods that are not computable beyond the simplest examples. This work introduces a new efficient approach to CP that produces provably valid confidence sets for fairly general non-exchangeable data distributions. We illustrate the general theory with applications to the challenging setting of federated learning under data heterogeneity between agents. Our method allows constructing provably valid personalized prediction sets for agents in a fully federated way. The effectiveness of the proposed method is demonstrated in a series of experiments on real-world datasets.
Dirichlet-based Uncertainty Quantification for Personalized Federated Learning with Improved Posterior Networks
Dec 18, 2023



In modern federated learning, one of the main challenges is to account for inherent heterogeneity and the diverse nature of data distributions for different clients. This problem is often addressed by introducing personalization of the models towards the data distribution of the particular client. However, a personalized model might be unreliable when applied to the data that is not typical for this client. Eventually, it may perform worse for these data than the non-personalized global model trained in a federated way on the data from all the clients. This paper presents a new approach to federated learning that allows selecting a model from global and personalized ones that would perform better for a particular input point. It is achieved through a careful modeling of predictive uncertainties that helps to detect local and global in- and out-of-distribution data and use this information to select the model that is confident in a prediction. The comprehensive experimental evaluation on the popular real-world image datasets shows the superior performance of the model in the presence of out-of-distribution data while performing on par with state-of-the-art personalized federated learning algorithms in the standard scenarios.
LM-Polygraph: Uncertainty Estimation for Language Models
Nov 13, 2023



Recent advancements in the capabilities of large language models (LLMs) have paved the way for a myriad of groundbreaking applications in various fields. However, a significant challenge arises as these models often "hallucinate", i.e., fabricate facts without providing users an apparent means to discern the veracity of their statements. Uncertainty estimation (UE) methods are one path to safer, more responsible, and more effective use of LLMs. However, to date, research on UE methods for LLMs has been focused primarily on theoretical rather than engineering contributions. In this work, we tackle this issue by introducing LM-Polygraph, a framework with implementations of a battery of state-of-the-art UE methods for LLMs in text generation tasks, with unified program interfaces in Python. Additionally, it introduces an extendable benchmark for consistent evaluation of UE techniques by researchers, and a demo web application that enriches the standard chat dialog with confidence scores, empowering end-users to discern unreliable responses. LM-Polygraph is compatible with the most recent LLMs, including BLOOMz, LLaMA-2, ChatGPT, and GPT-4, and is designed to support future releases of similarly-styled LMs.
Selective Nonparametric Regression via Testing
Sep 28, 2023



Prediction with the possibility of abstention (or selective prediction) is an important problem for error-critical machine learning applications. While well-studied in the classification setup, selective approaches to regression are much less developed. In this work, we consider the nonparametric heteroskedastic regression problem and develop an abstention procedure via testing the hypothesis on the value of the conditional variance at a given point. Unlike existing methods, the proposed one allows to account not only for the value of the variance itself but also for the uncertainty of the corresponding variance predictor. We prove non-asymptotic bounds on the risk of the resulting estimator and show the existence of several different convergence regimes. Theoretical analysis is illustrated with a series of experiments on simulated and real-world data.
Optimal Estimation in Mixed-Membership Stochastic Block Models
Jul 26, 2023



Community detection is one of the most critical problems in modern network science. Its applications can be found in various fields, from protein modeling to social network analysis. Recently, many papers appeared studying the problem of overlapping community detection, where each node of a network may belong to several communities. In this work, we consider Mixed-Membership Stochastic Block Model (MMSB) first proposed by Airoldi et al. (2008). MMSB provides quite a general setting for modeling overlapping community structure in graphs. The central question of this paper is to reconstruct relations between communities given an observed network. We compare different approaches and establish the minimax lower bound on the estimation error. Then, we propose a new estimator that matches this lower bound. Theoretical results are proved under fairly general conditions on the considered model. Finally, we illustrate the theory in a series of experiments.
Conformal Prediction for Federated Uncertainty Quantification Under Label Shift
Jun 08, 2023



Federated Learning (FL) is a machine learning framework where many clients collaboratively train models while keeping the training data decentralized. Despite recent advances in FL, the uncertainty quantification topic (UQ) remains partially addressed. Among UQ methods, conformal prediction (CP) approaches provides distribution-free guarantees under minimal assumptions. We develop a new federated conformal prediction method based on quantile regression and take into account privacy constraints. This method takes advantage of importance weighting to effectively address the label shift between agents and provides theoretical guarantees for both valid coverage of the prediction sets and differential privacy. Extensive experimental studies demonstrate that this method outperforms current competitors.
Scalable Batch Acquisition for Deep Bayesian Active Learning
Jan 13, 2023In deep active learning, it is especially important to choose multiple examples to markup at each step to work efficiently, especially on large datasets. At the same time, existing solutions to this problem in the Bayesian setup, such as BatchBALD, have significant limitations in selecting a large number of examples, associated with the exponential complexity of computing mutual information for joint random variables. We, therefore, present the Large BatchBALD algorithm, which gives a well-grounded approximation to the BatchBALD method that aims to achieve comparable quality while being more computationally efficient. We provide a complexity analysis of the algorithm, showing a reduction in computation time, especially for large batches. Furthermore, we present an extensive set of experimental results on image and text data, both on toy datasets and larger ones such as CIFAR-100.
Active Learning for Abstractive Text Summarization
Jan 09, 2023



Construction of human-curated annotated datasets for abstractive text summarization (ATS) is very time-consuming and expensive because creating each instance requires a human annotator to read a long document and compose a shorter summary that would preserve the key information relayed by the original document. Active Learning (AL) is a technique developed to reduce the amount of annotation required to achieve a certain level of machine learning model performance. In information extraction and text classification, AL can reduce the amount of labor up to multiple times. Despite its potential for aiding expensive annotation, as far as we know, there were no effective AL query strategies for ATS. This stems from the fact that many AL strategies rely on uncertainty estimation, while as we show in our work, uncertain instances are usually noisy, and selecting them can degrade the model performance compared to passive annotation. We address this problem by proposing the first effective query strategy for AL in ATS based on diversity principles. We show that given a certain annotation budget, using our strategy in AL annotation helps to improve the model performance in terms of ROUGE and consistency scores. Additionally, we analyze the effect of self-learning and show that it can further increase the performance of the model.
ScaleFace: Uncertainty-aware Deep Metric Learning
Sep 12, 2022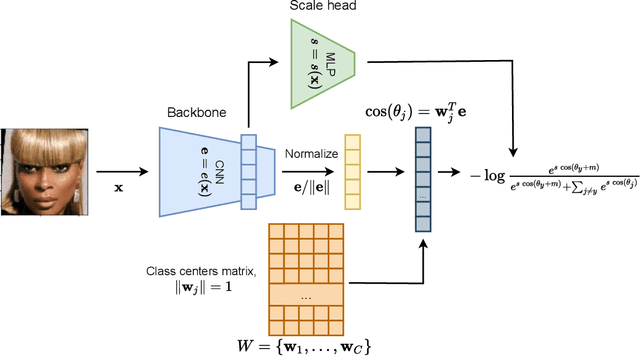
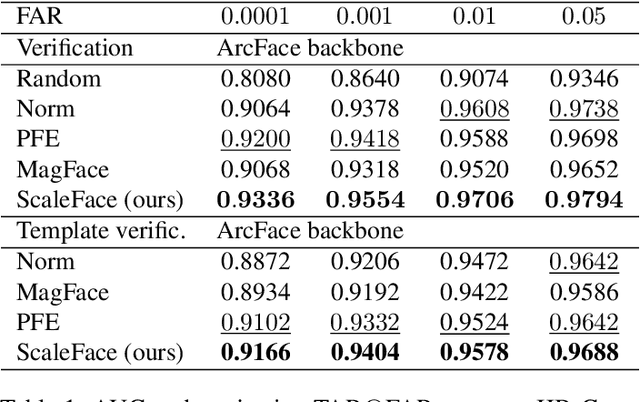

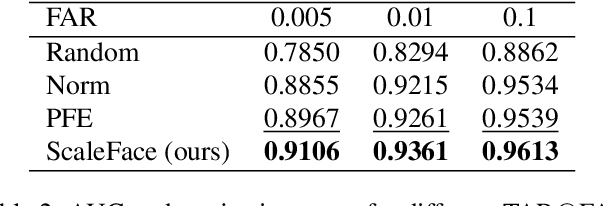
The performance of modern deep learning-based systems dramatically depends on the quality of input objects. For example, face recognition quality would be lower for blurry or corrupted inputs. However, it is hard to predict the influence of input quality on the resulting accuracy in more complex scenarios. We propose an approach for deep metric learning that allows direct estimation of the uncertainty with almost no additional computational cost. The developed \textit{ScaleFace} algorithm uses trainable scale values that modify similarities in the space of embeddings. These input-dependent scale values represent a measure of confidence in the recognition result, thus allowing uncertainty estimation. We provide comprehensive experiments on face recognition tasks that show the superior performance of ScaleFace compared to other uncertainty-aware face recognition approaches. We also extend the results to the task of text-to-image retrieval showing that the proposed approach beats the competitors with significant margin.
Towards OOD Detection in Graph Classification from Uncertainty Estimation Perspective
Jun 21, 2022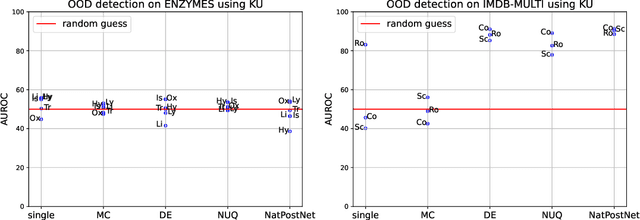
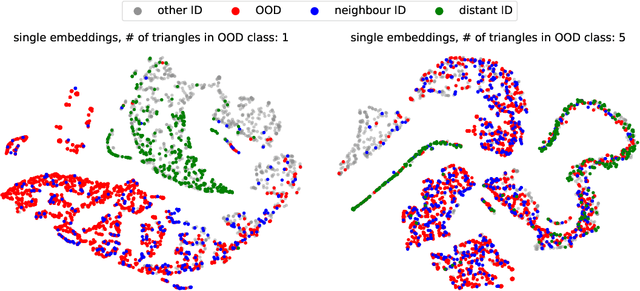

The problem of out-of-distribution detection for graph classification is far from being solved. The existing models tend to be overconfident about OOD examples or completely ignore the detection task. In this work, we consider this problem from the uncertainty estimation perspective and perform the comparison of several recently proposed methods. In our experiment, we find that there is no universal approach for OOD detection, and it is important to consider both graph representations and predictive categorical distribution.