 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking TinyML Systems: Challenges and Direction
Mar 10, 2020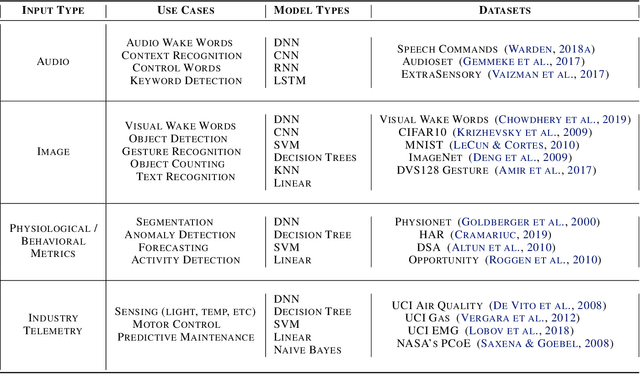
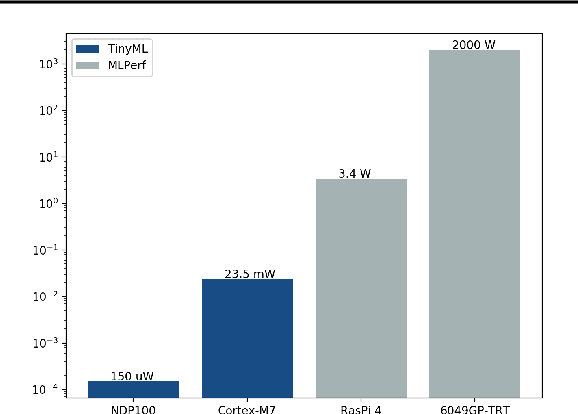
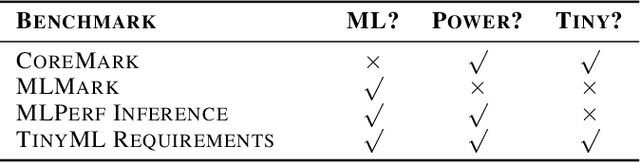
Recent advancements in ultra-low-power machine learning (TinyML) hardware promises to unlock an entirely new class of smart applications. However, continued progress is limited by the lack of a widely accepted benchmark for these systems. Benchmarking allows us to measure and thereby systematically compare, evaluate, and improve the performance of systems. In this position paper, we present the current landscape of TinyML and discuss the challenges and direction towards developing a fair and useful hardware benchmark for TinyML workloads. Our viewpoints reflect the collective thoughts of the TinyMLPerf working group that is comprised of 30 organizations.
Gradient Diversity: a Key Ingredient for Scalable Distributed Learning
Jan 07, 2018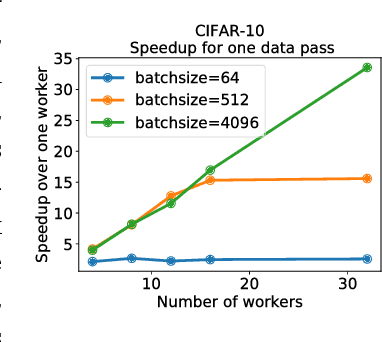

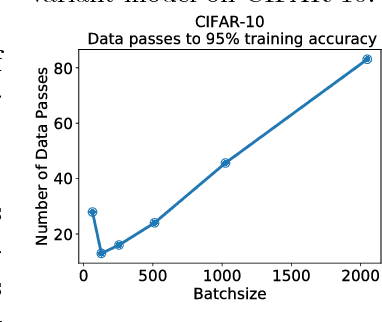
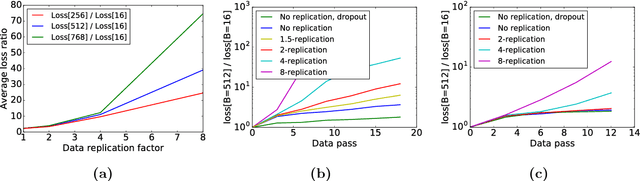
It has been experimentally observed that distributed implementations of mini-batch stochastic gradient descent (SGD) algorithms exhibit speedup saturation and decaying generalization ability beyond a particular batch-size. In this work, we present an analysis hinting that high similarity between concurrently processed gradients may be a cause of this performance degradation. We introduce the notion of gradient diversity that measures the dissimilarity between concurrent gradient updates, and show its key role in the performance of mini-batch SGD. We prove that on problems with high gradient diversity, mini-batch SGD is amenable to better speedups, while maintaining the generalization performance of serial (one sample) SGD. We further establish lower bounds on convergence where mini-batch SGD slows down beyond a particular batch-size, solely due to the lack of gradient diversity. We provide experimental evidence indicating the key role of gradient diversity in distributed learning, and discuss how heuristics like dropout, Langevin dynamics, and quantization can improve it.