 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Deformed Neural Networks
Oct 21, 2020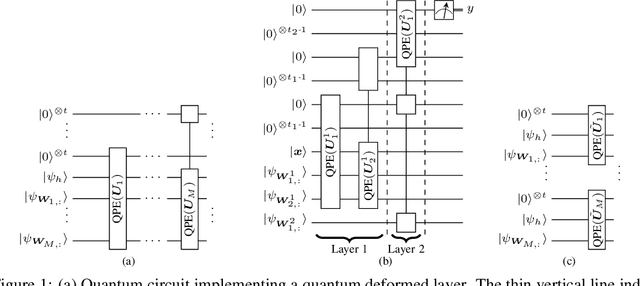
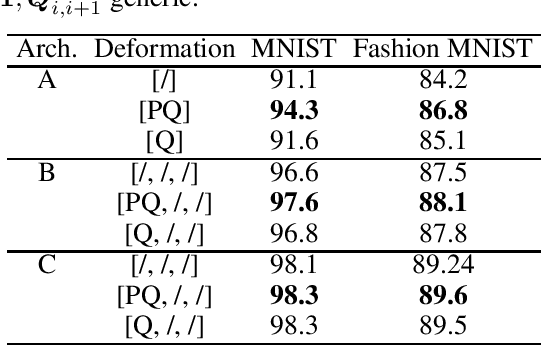
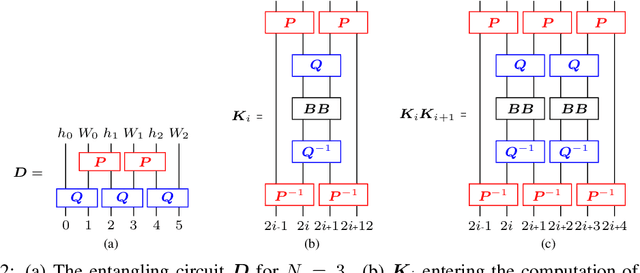
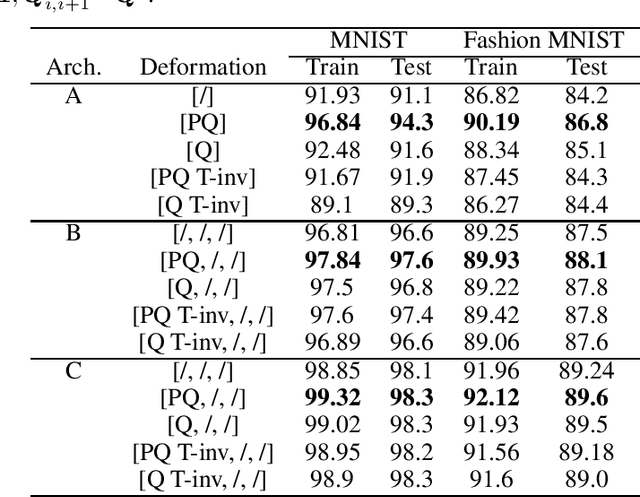
We develop a new quantum neural network layer designed to run efficiently on a quantum computer but that can be simulated on a classical computer when restricted in the way it entangles input states. We first ask how a classical neural network architecture, both fully connected or convolutional, can be executed on a quantum computer using quantum phase estimation. We then deform the classical layer into a quantum design which entangles activations and weights into quantum superpositions. While the full model would need the exponential speedups delivered by a quantum computer, a restricted class of designs represent interesting new classical network layers that still use quantum features. We show that these quantum deformed neural networks can be trained and executed on normal data such as images, and even classically deliver modest improvements over standard architectures.
Orbital MCMC
Oct 15, 2020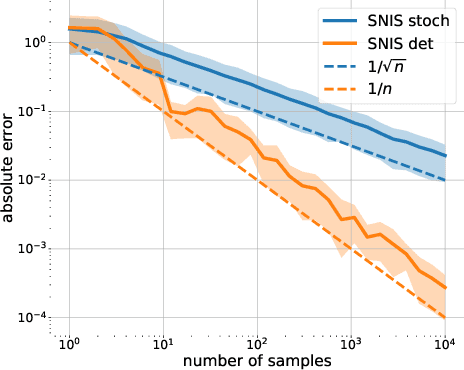
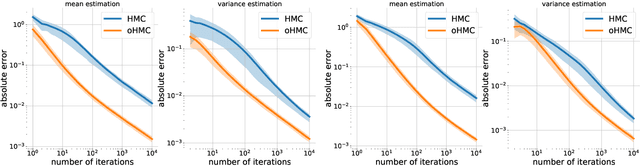
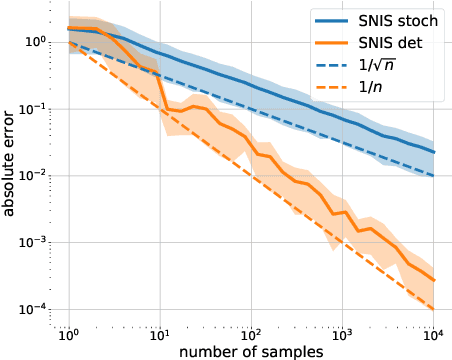
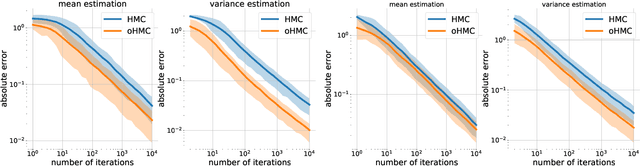
Markov Chain Monte Carlo (MCMC) is a computational approach to fundamental problems such as inference, integration, optimization, and simulation. Recently, the framework (Involutive MCMC) was proposed describing a large body of MCMC algorithms via two components: a stochastic acceptance test and an involutive deterministic function. This paper demonstrates that this framework is a special case of a larger family of algorithms operating on orbits of continuous deterministic bijections. We describe this family by deriving a novel MCMC kernel, which we call orbital MCMC (oMCMC). We provide a theoretical analysis and illustrate its utility using simple examples.
Natural Graph Networks
Jul 16, 2020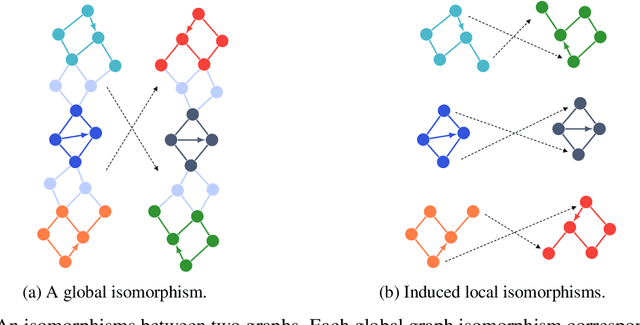
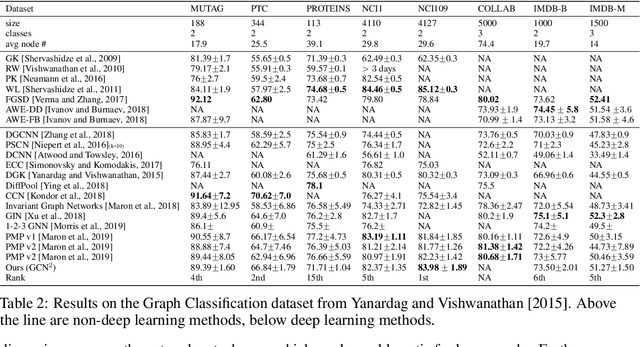
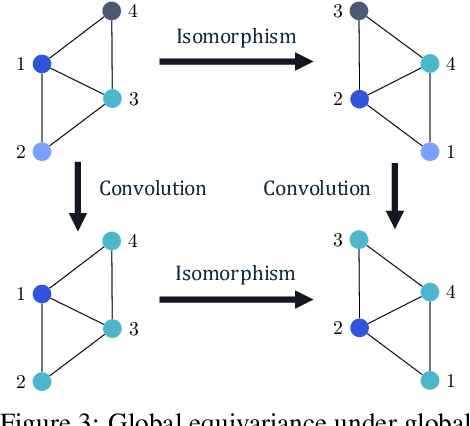
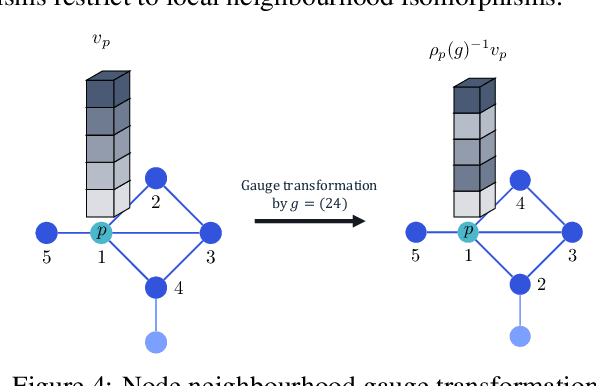
Conventional neural message passing algorithms are invariant under permutation of the messages and hence forget how the information flows through the network. Studying the local symmetries of graphs, we propose a more general algorithm that uses different kernels on different edges, making the network equivariant to local and global graph isomorphisms and hence more expressive. Using elementary category theory, we formalize many distinct equivariant neural networks as natural networks, and show that their kernels are 'just' a natural transformation between two functors. We give one practical instantiation of a natural network on graphs which uses a equivariant message network parameterization, yielding good performance on several benchmarks.
Federated Learning of User Authentication Models
Jul 09, 2020
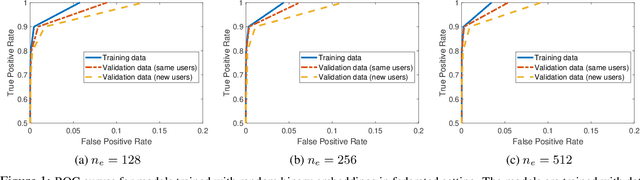
Machine learning-based User Authentication (UA) models have been widely deployed in smart devices. UA models are trained to map input data of different users to highly separable embedding vectors, which are then used to accept or reject new inputs at test time. Training UA models requires having direct access to the raw inputs and embedding vectors of users, both of which are privacy-sensitive information. In this paper, we propose Federated User Authentication (FedUA), a framework for privacy-preserving training of UA models. FedUA adopts federated learning framework to enable a group of users to jointly train a model without sharing the raw inputs. It also allows users to generate their embeddings as random binary vectors, so that, unlike the existing approach of constructing the spread out embeddings by the server, the embedding vectors are kept private as well. We show our method is privacy-preserving, scalable with number of users, and allows new users to be added to training without changing the output layer. Our experimental results on the VoxCeleb dataset for speaker verification shows our method reliably rejects data of unseen users at very high true positive rates.
SurVAE Flows: Surjections to Bridge the Gap between VAEs and Flows
Jul 06, 2020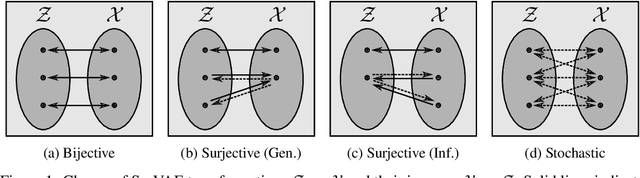


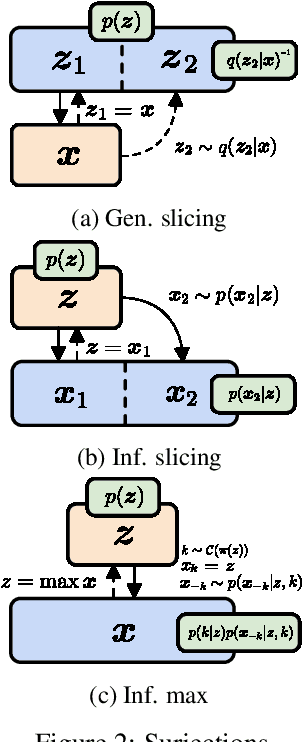
Normalizing flows and variational autoencoders are powerful generative models that can represent complicated density functions. However, they both impose constraints on the models: Normalizing flows use bijective transformations to model densities whereas VAEs learn stochastic transformations that are non-invertible and thus typically do not provide tractable estimates of the marginal likelihood. In this paper, we introduce SurVAE Flows: A modular framework of composable transformations that encompasses VAEs and normalizing flows. SurVAE Flows bridge the gap between normalizing flows and VAEs with surjective transformations, wherein the transformations are deterministic in one direction -- thereby allowing exact likelihood computation, and stochastic in the reverse direction -- hence providing a lower bound on the corresponding likelihood. We show that several recently proposed methods, including dequantization and augmented normalizing flows, can be expressed as SurVAE Flows. Finally, we introduce common operations such as the max value, the absolute value, sorting and stochastic permutation as composable layers in SurVAE Flows.
RE-MIMO: Recurrent and Permutation Equivariant Neural MIMO Detection
Jun 30, 2020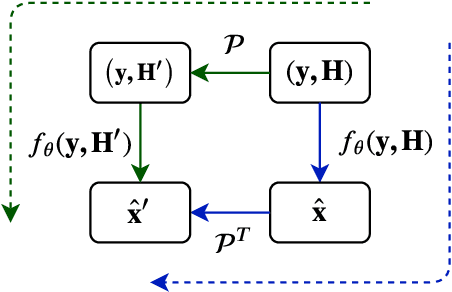



In this paper, we present a novel neural network for MIMO symbol detection. It is motivated by several important considerations in wireless communication systems; permutation equivariance and a variable number of users. The neural detector learns an iterative decoding algorithm that is implemented as a stack of iterative units. Each iterative unit is a neural computation module comprising of 3 sub-modules: the likelihood module, the encoder module, and the predictor module. The likelihood module injects information about the generative (forward) process into the neural network. The encoder-predictor modules together update the state vector and symbol estimates. The encoder module updates the state vector and employs a transformer based attention network to handle the interactions among the users in a permutation equivariant manner. The predictor module refines the symbol estimates. The modular and permutation equivariant architecture allows for dealing with a varying number of users. The resulting neural detector architecture is unique and exhibits several desirable properties unseen in any of the previously proposed neural detectors. We compare its performance against existing methods and the results show the ability of our network to efficiently handle a variable number of transmitters with high accuracy.
MDP Homomorphic Networks: Group Symmetries in Reinforcement Learning
Jun 30, 2020
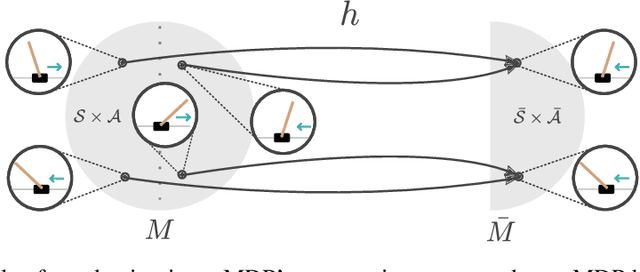
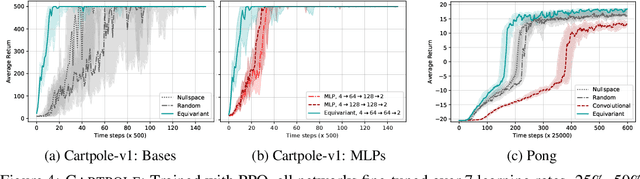
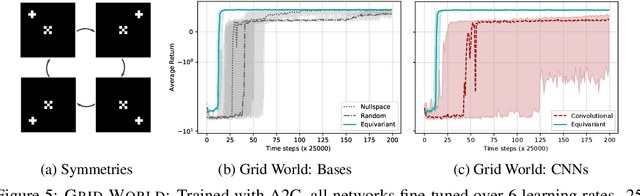
This paper introduces MDP homomorphic networks for deep reinforcement learning. MDP homomorphic networks are neural networks that are equivariant under symmetries in the joint state-action space of an MDP. Current approaches to deep reinforcement learning do not usually exploit knowledge about such structure. By building this prior knowledge into policy and value networks using an equivariance constraint, we can reduce the size of the solution space. We specifically focus on group-structured symmetries (invertible transformations). Additionally, we introduce an easy method for constructing equivariant network layers numerically, so the system designer need not solve the constraints by hand, as is typically done. We construct MDP homomorphic MLPs and CNNs that are equivariant under either a group of reflections or rotations. We show that such networks converge faster than unstructured baselines on CartPole, a grid world and Pong.
Involutive MCMC: a Unifying Framework
Jun 30, 2020
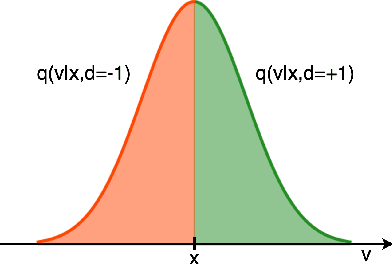

Markov Chain Monte Carlo (MCMC) is a computational approach to fundamental problems such as inference, integration, optimization, and simulation. The field has developed a broad spectrum of algorithms, varying in the way they are motivated, the way they are applied and how efficiently they sample. Despite all the differences, many of them share the same core principle, which we unify as the Involutive MCMC (iMCMC) framework. Building upon this, we describe a wide range of MCMC algorithms in terms of iMCMC, and formulate a number of "tricks" which one can use as design principles for developing new MCMC algorithms. Thus, iMCMC provides a unified view of many known MCMC algorithms, which facilitates the derivation of powerful extensions. We demonstrate the latter with two examples where we transform known reversible MCMC algorithms into more efficient irreversible ones.
SE(3)-Transformers: 3D Roto-Translation Equivariant Attention Networks
Jun 22, 2020
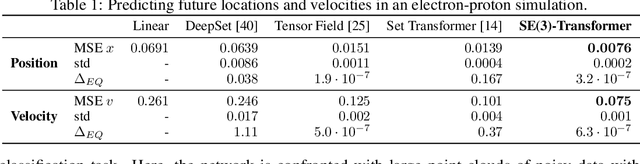
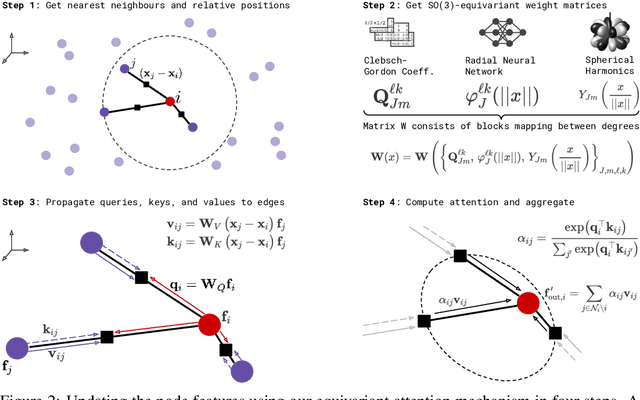

We introduce the SE(3)-Transformer, a variant of the self-attention module for 3D point clouds, which is equivariant under continuous 3D roto-translations. Equivariance is important to ensure stable and predictable performance in the presence of nuisance transformations of the data input. A positive corollary of equivariance is increased weight-tying within the model, leading to fewer trainable parameters and thus decreased sample complexity (i.e. we need less training data). The SE(3)-Transformer leverages the benefits of self-attention to operate on large point clouds with varying number of points, while guaranteeing SE(3)-equivariance for robustness. We evaluate our model on a toy $N$-body particle simulation dataset, showcasing the robustness of the predictions under rotations of the input. We further achieve competitive performance on two real-world datasets, ScanObjectNN and QM9. In all cases, our model outperforms a strong, non-equivariant attention baseline and an equivariant model without attention.
Amortized Causal Discovery: Learning to Infer Causal Graphs from Time-Series Data
Jun 18, 2020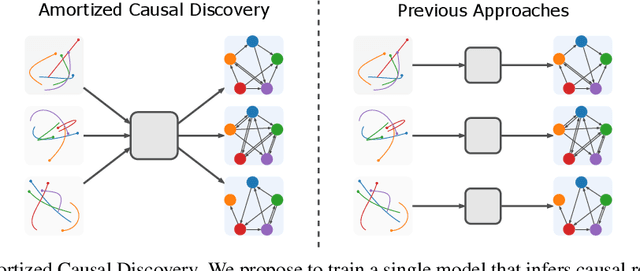
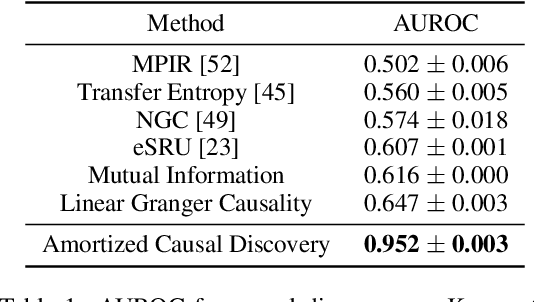
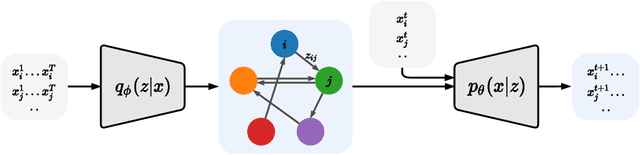
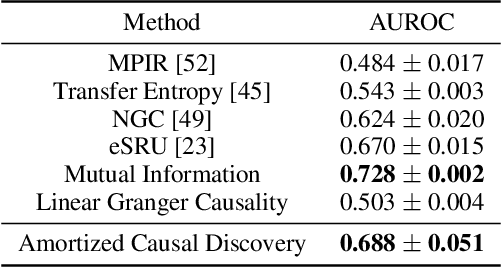
Standard causal discovery methods must fit a new model whenever they encounter samples from a new underlying causal graph. However, these samples often share relevant information - for instance, the dynamics describing the effects of causal relations - which is lost when following this approach. We propose Amortized Causal Discovery, a novel framework that leverages such shared dynamics to learn to infer causal relations from time-series data. This enables us to train a single, amortized model that infers causal relations across samples with different underlying causal graphs, and thus makes use of the information that is shared. We demonstrate experimentally that this approach, implemented as a variational model, leads to significant improvements in causal discovery performance, and show how it can be extended to perform well under hidden confounding.