 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Bayesian Learning Algorithms Revisited: From Learning Majorizers to Structured Algorithmic Learning using Neural Networks
Apr 02, 2026Sparse Bayesian Learning is one of the most popular sparse signal recovery methods, and various algorithms exist under the SBL paradigm. However, given a performance metric and a sparse recovery problem, it is difficult to know a-priori the best algorithm to choose. This difficulty is in part due to a lack of a unified framework to derive SBL algorithms. We address this issue by first showing that the most popular SBL algorithms can be derived using the majorization-minimization (MM) principle, providing hitherto unknown convergence guarantees to this class of SBL methods. Moreover, we show that the two most popular SBL update rules not only fall under the MM framework but are both valid descent steps for a common majorizer, revealing a deeper analytical compatibility between these algorithms. Using this insight and properties from MM theory we expand the class of SBL algorithms, and address finding the best SBL algorithm via data within the MM framework. Second, we go beyond the MM framework by introducing the powerful modeling capabilities of deep learning to further expand the class of SBL algorithms, aiming to learn a superior SBL update rule from data. We propose a novel deep learning architecture that can outperform the classical MM based ones across different sparse recovery problems. Our architecture's complexity does not scale with the measurement matrix dimension, hence providing a unique opportunity to test generalization capability across different matrices. For parameterized dictionaries, this invariance allows us to train and test the model across different parameter ranges. We also showcase our model's ability to learn a functional mapping by its zero-shot performance on unseen measurement matrices. Finally, we test our model's performance across different numbers of snapshots, signal-to-noise ratios, and sparsity levels.
A Comparative Study of Invariance-Aware Loss Functions for Deep Learning-based Gridless Direction-of-Arrival Estimation
Mar 16, 2025Covariance matrix reconstruction has been the most widely used guiding objective in gridless direction-of-arrival (DoA) estimation for sparse linear arrays. Many semidefinite programming (SDP)-based methods fall under this category. Although deep learning-based approaches enable the construction of more sophisticated objective functions, most methods still rely on covariance matrix reconstruction. In this paper, we propose new loss functions that are invariant to the scaling of the matrices and provide a comparative study of losses with varying degrees of invariance. The proposed loss functions are formulated based on the scale-invariant signal-to-distortion ratio between the target matrix and the Gram matrix of the prediction. Numerical results show that a scale-invariant loss outperforms its non-invariant counterpart but is inferior to the recently proposed subspace loss that is invariant to the change of basis. These results provide evidence that designing loss functions with greater degrees of invariance is advantageous in deep learning-based gridless DoA estimation.
Adaptive and Self-Tuning SBL with Total Variation Priors for Block-Sparse Signal Recovery
Mar 12, 2025

This letter addresses the problem of estimating block sparse signal with unknown group partitions in a multiple measurement vector (MMV) setup. We propose a Bayesian framework by applying an adaptive total variation (TV) penalty on the hyper-parameter space of the sparse signal. The main contributions are two-fold. 1) We extend the TV penalty beyond the immediate neighbor, thus enabling better capture of the signal structure. 2) A dynamic framework is provided to learn the penalty parameter for regularization. It is based on the statistical dependencies between the entries of tentative blocks, thus eliminating the need for fine-tuning. The superior performance of the proposed method is empirically demonstrated by extensive computer simulations with the state-of-art benchmarks. The proposed solution exhibits both excellent performance and robustness against sparsity model mismatch.
Subspace Representation Learning for Sparse Linear Arrays to Localize More Sources than Sensors: A Deep Learning Methodology
Aug 29, 2024



Localizing more sources than sensors with a sparse linear array (SLA) has long relied on minimizing a distance between two covariance matrices and recent algorithms often utilize semidefinite programming (SDP). Although deep neural network (DNN)-based methods offer new alternatives, they still depend on covariance matrix fitting. In this paper, we develop a novel methodology that estimates the co-array subspaces from a sample covariance for SLAs. Our methodology trains a DNN to learn signal and noise subspace representations that are invariant to the selection of bases. To learn such representations, we propose loss functions that gauge the separation between the desired and the estimated subspace. In particular, we propose losses that measure the length of the shortest path between subspaces viewed on a union of Grassmannians, and prove that it is possible for a DNN to approximate signal subspaces. The computation of learning subspaces of different dimensions is accelerated by a new batch sampling strategy called consistent rank sampling. The methodology is robust to array imperfections due to its geometry-agnostic and data-driven nature. In addition, we propose a fully end-to-end gridless approach that directly learns angles to study the possibility of bypassing subspace methods. Numerical results show that learning such subspace representations is more beneficial than learning covariances or angles. It outperforms conventional SDP-based methods such as the sparse and parametric approach (SPA) and existing DNN-based covariance reconstruction methods for a wide range of signal-to-noise ratios (SNRs), snapshots, and source numbers for both perfect and imperfect arrays.
Novel Active Sensing and Inference for mmWave Beam Alignment Using Single RF Chain Systems
Apr 11, 2024We propose a novel sensing approach for the beam alignment problem in millimeter wave systems using a single Radio Frequency (RF) chain. Conventionally, beam alignment using a single phased array involves comparing beamformer output power across different spatial regions. This incurs large training overhead due to the need to perform the beam scan operation. The proposed Synthesis of Virtual Array Manifold (SVAM) sensing methodology is inspired from synthetic aperture radar systems and realizes a virtual array geometry over temporal measurements. We demonstrate the benefits of SVAM using Cram\'er-Rao bound (CRB) analysis over schemes that repeat beam pattern to boost signal-to-noise (SNR) ratio. We also showcase versatile applicability of the proposed SVAM sensing by incorporating it within existing beam alignment procedures that assume perfect knowledge of the small-scale fading coefficient. We further consider the practical scenario wherein we estimate the fading coefficient and propose a novel beam alignment procedure based on efficient computation of an approximate posterior density on dominant path angle. We provide numerical experiments to study the impact of parameters involved in the procedure. The performance of the proposed sensing and beam alignment algorithm is empirically observed to approach the fading coefficient-perfectly known performance, even at low SNR.
Regularized Neural Detection for One-Bit Massive MIMO Communication Systems
May 24, 2023Detection for one-bit massive MIMO systems presents several challenges especially for higher order constellations. Recent advances in both model-based analysis and deep learning frameworks have resulted in several robust one-bit detector designs. Our work builds on the current state-of-the-art gradient descent (GD)-based detector. We introduce two novel contributions in our detector design: (i) We augment each GD iteration with a deep learning-aided regularization step, and (ii) We introduce a novel constellation-based loss function for our regularized DNN detector. This one-bit detection strategy is applied to two different DNN architectures based on algorithm unrolling, namely, a deep unfolded neural network and a deep recurrent neural network. Being trained on multiple randomly sampled channel matrices, these networks are developed as general one-bit detectors. The numerical results show that the combination of the DNN-augmented regularized GD and constellation-based loss function improve the quality of our one-bit detector, especially for higher order M-QAM constellations.
A DNN based Normalized Time-frequency Weighted Criterion for Robust Wideband DoA Estimation
Feb 20, 2023



Deep neural networks (DNNs) have greatly benefited direction of arrival (DoA) estimation methods for speech source localization in noisy environments. However, their localization accuracy is still far from satisfactory due to the vulnerability to nonspeech interference. To improve the robustness against interference, we propose a DNN based normalized time-frequency (T-F) weighted criterion which minimizes the distance between the candidate steering vectors and the filtered snapshots in the T-F domain. Our method requires no eigendecomposition and uses a simple normalization to prevent the optimization objective from being misled by noisy filtered snapshots. We also study different designs of T-F weights guided by a DNN. We find that duplicating the Hadamard product of speech ratio masks is highly effective and better than other techniques such as direct masking and taking the mean in the proposed approach. However, the best-performing design of T-F weights is criterion-dependent in general. Experiments show that the proposed method outperforms popular DNN based DoA estimation methods including widely used subspace methods in noisy and reverberant environments.
Vector Quantization Methods for Access Point Placement in Cell-Free Massive MIMO Systems
Nov 23, 2022



We examine the problem of uplink cell-free access point (AP) placement in the context of optimal throughput. In this regard, we formulate two main placement problems, namely the sum rate and minimum rate maximization problems, and discuss the challenges associated with solving the underlying optimization problem with the help of some simple scenarios. As a practical solution to the AP placement problem, we suggest a vector quantization (VQ) approach. The suitability of the VQ approach to cell-free AP placement is investigated by examining three VQ-based solutions. First, the standard VQ approach, that is the Lloyd algorithm (using the squared error distortion function) is described. Second, the tree-structured VQ (TSVQ), which performs successive partitioning of the distribution space is applied. Third, a probability density function optimized VQ (PDFVQ) procedure is outlined, which enables efficient, low complexity, and scalable placement, and is aimed at a massive distributed multiple-input-multiple-output (MIMO) scenario. While the VQ-based solutions do not solve the cell-free AP placement problems explicitly, numerical experiments show that their sum and minimum rate performances are good enough, and offer a good starting point for gradient-based optimization methods. Among the VQ solutions, PDFVQ, with advantages over the other VQ methods, offers a good trade-off between sum and minimum rates.
Improved Bounds on Neural Complexity for Representing Piecewise Linear Functions
Oct 13, 2022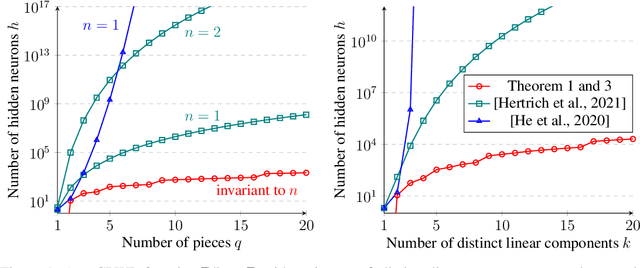

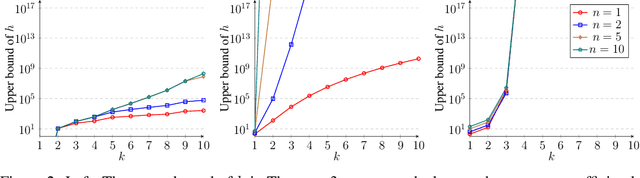

A deep neural network using rectified linear units represents a continuous piecewise linear (CPWL) function and vice versa. Recent results in the literature estimated that the number of neurons needed to exactly represent any CPWL function grows exponentially with the number of pieces or exponentially in terms of the factorial of the number of distinct linear components. Moreover, such growth is amplified linearly with the input dimension. These existing results seem to indicate that the cost of representing a CPWL function is expensive. In this paper, we propose much tighter bounds and establish a polynomial time algorithm to find a network satisfying these bounds for any given CPWL function. We prove that the number of hidden neurons required to exactly represent any CPWL function is at most a quadratic function of the number of pieces. In contrast to all previous results, this upper bound is invariant to the input dimension. Besides the number of pieces, we also study the number of distinct linear components in CPWL functions. When such a number is also given, we prove that the quadratic complexity turns into bilinear, which implies a lower neural complexity because the number of distinct linear components is always not greater than the minimum number of pieces in a CPWL function. When the number of pieces is unknown, we prove that, in terms of the number of distinct linear components, the neural complexity of any CPWL function is at most polynomial growth for low-dimensional inputs and a factorial growth for the worst-case scenario, which are significantly better than existing results in the literature.
Maximum Likelihood-based Gridless DoA Estimation Using Structured Covariance Matrix Recovery and SBL with Grid Refinement
Oct 07, 2022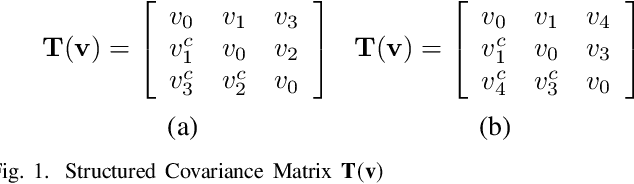

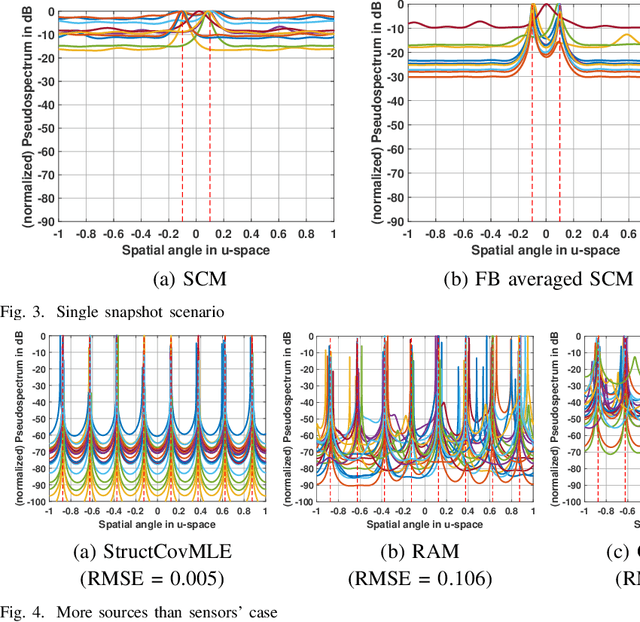
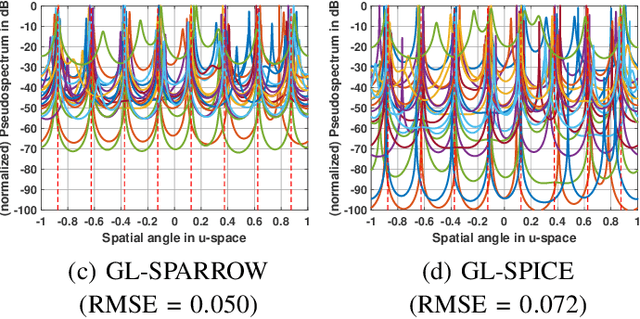
We consider the parametric data model employed in applications such as line spectral estimation and direction-of-arrival estimation. We focus on the stochastic maximum likelihood estimation (MLE) framework and offer approaches to estimate the parameter of interest in a gridless manner, overcoming the model complexities of the past. This progress is enabled by the modern trend of reparameterization of the objective and exploiting the sparse Bayesian learning (SBL) approach. The latter is shown to be a correlation-aware method, and for the underlying problem it is identified as a grid-based technique for recovering a structured covariance matrix of the measurements. For the case when the structured matrix is expressible as a sampled Toeplitz matrix, such as when measurements are sampled in time or space at regular intervals, additional constraints and reparameterization of the SBL objective leads to the proposed structured matrix recovery technique based on MLE. The proposed optimization problem is non-convex, and we propose a majorization-minimization based iterative procedure to estimate the structured matrix; each iteration solves a semidefinite program. We recover the parameter of interest in a gridless manner by appealing to the Caratheodory-Fejer result on decomposition of PSD Toeplitz matrices. For the general case of irregularly spaced time or spatial samples, we propose an iterative SBL procedure that refines grid points to increase resolution near potential source locations, while maintaining a low per iteration complexity. We provide numerical results to evaluate and compare the performance of the proposed techniques with other gridless techniques, and the CRB. The proposed correlation-aware approach is more robust to environmental/system effects such as low number of snapshots, correlated sources, small separation between source locations and improves sources identifiability.