 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphical Generative Adversarial Networks
Apr 10, 2018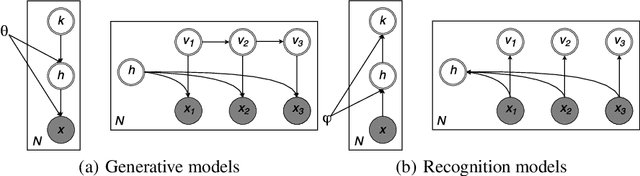
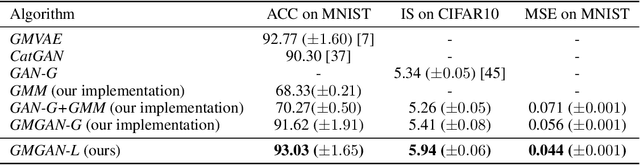
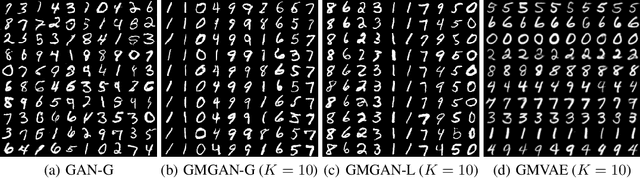
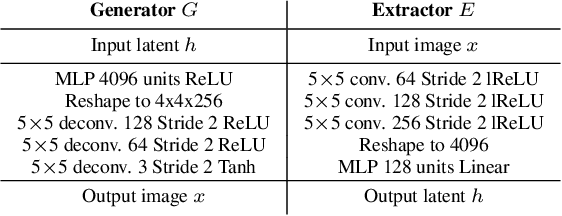
We propose Graphical Generative Adversarial Networks (Graphical-GAN) to model structured data. Graphical-GAN conjoins the power of Bayesian networks on compactly representing the dependency structures among random variables and that of generative adversarial networks on learning expressive dependency functions. We introduce a structured recognition model to infer the posterior distribution of latent variables given observations. We propose two alternative divergence minimization approaches to learn the generative model and recognition model jointly. The first one treats all variables as a whole, while the second one utilizes the structural information by checking the individual local factors defined by the generative model and works better in practice. Finally, we present two important instances of Graphical-GAN, i.e. Gaussian Mixture GAN (GMGAN) and State Space GAN (SSGAN), which can successfully learn the discrete and temporal structures on visual datasets, respectively.
Mean Field Network based Graph Refinement with application to Airway Tree Extraction
Apr 10, 2018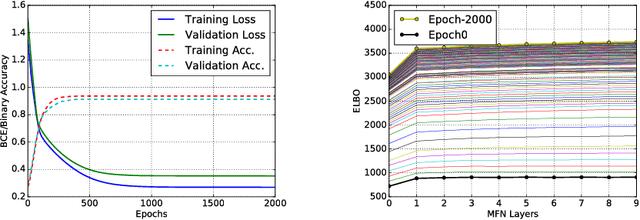

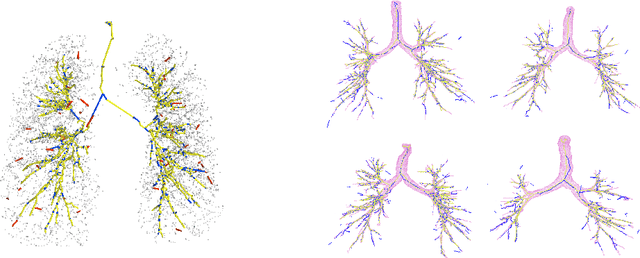
We present tree extraction in 3D images as a graph refinement task, of obtaining a subgraph from an over-complete input graph. To this end, we formulate an approximate Bayesian inference framework on undirected graphs using mean field approximation (MFA). Mean field networks are used for inference based on the interpretation that iterations of MFA can be seen as feed-forward operations in a neural network. This allows us to learn the model parameters from training data using back-propagation algorithm. We demonstrate usefulness of the model to extract airway trees from 3D chest CT data. We first obtain probability images using a voxel classifier that distinguishes airways from background and use Bayesian smoothing to model individual airway branches. This yields us joint Gaussian density estimates of position, orientation and scale as node features of the input graph. Performance of the method is compared with two methods: the first uses probability images from a trained voxel classifier with region growing, which is similar to one of the best performing methods at EXACT'09 airway challenge, and the second method is based on Bayesian smoothing on these probability images. Using centerline distance as error measure the presented method shows significant improvement compared to these two methods.
Sylvester Normalizing Flows for Variational Inference
Mar 15, 2018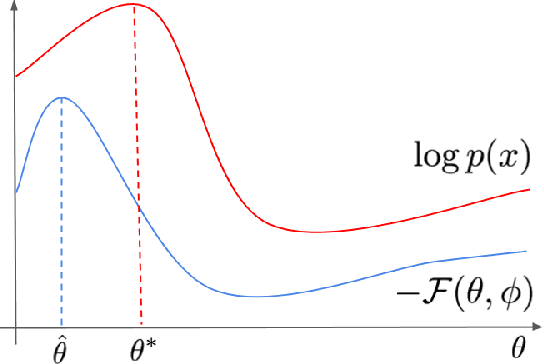
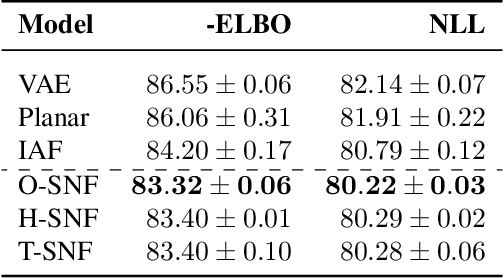

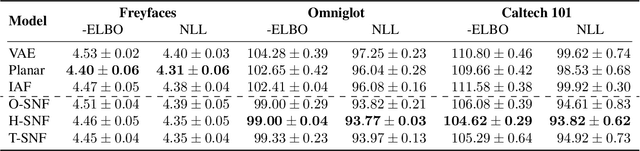
Variational inference relies on flexible approximate posterior distributions. Normalizing flows provide a general recipe to construct flexible variational posteriors. We introduce Sylvester normalizing flows, which can be seen as a generalization of planar flows. Sylvester normalizing flows remove the well-known single-unit bottleneck from planar flows, making a single transformation much more flexible. We compare the performance of Sylvester normalizing flows against planar flows and inverse autoregressive flows and demonstrate that they compare favorably on several datasets.
Variational Bayes In Private Settings (VIPS)
Mar 06, 2018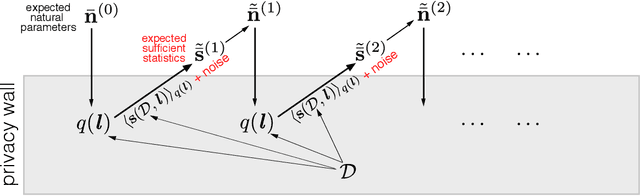
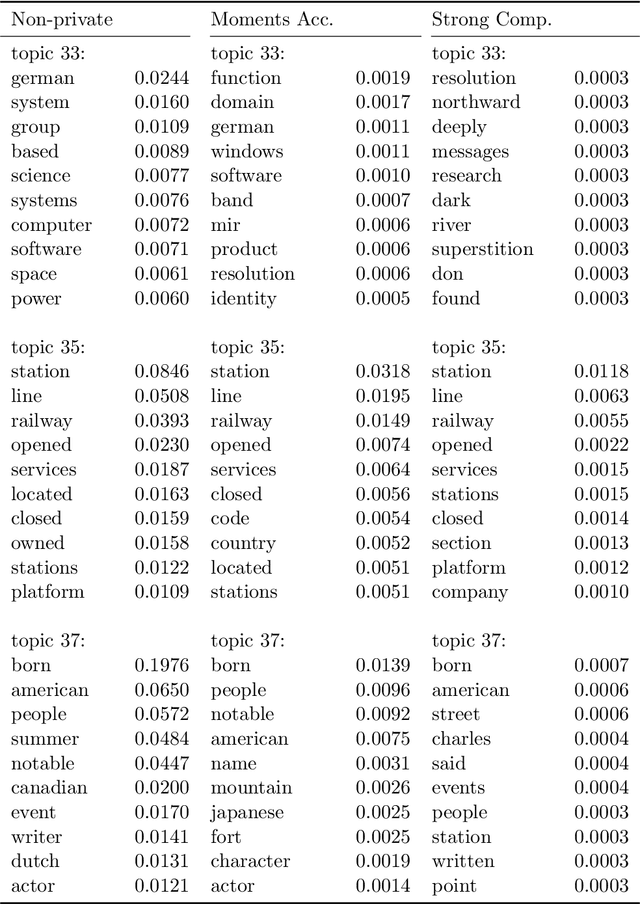
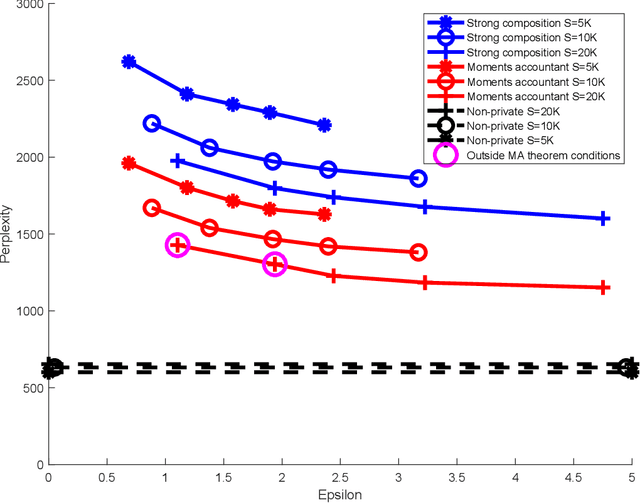
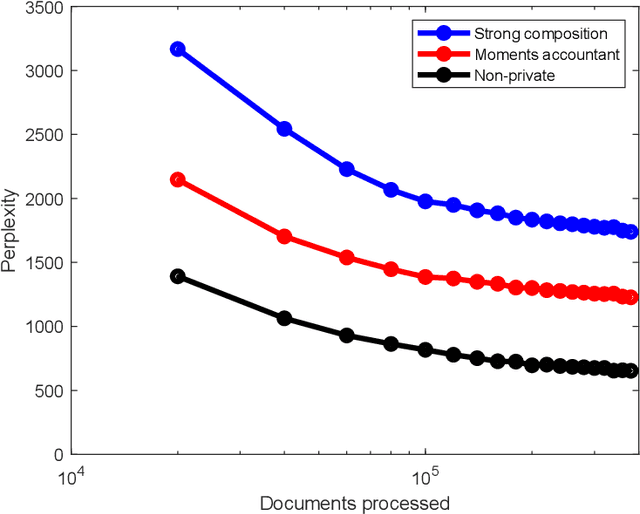
Many applications of Bayesian data analysis involve sensitive information, motivating methods which ensure that privacy is protected. We introduce a general privacy-preserving framework for Variational Bayes (VB), a widely used optimization-based Bayesian inference method. Our framework respects differential privacy, the gold-standard privacy criterion, and encompasses a large class of probabilistic models, called the Conjugate Exponential (CE) family. We observe that we can straightforwardly privatise VB's approximate posterior distributions for models in the CE family, by perturbing the expected sufficient statistics of the complete-data likelihood. For a broadly-used class of non-CE models, those with binomial likelihoods, we show how to bring such models into the CE family, such that inferences in the modified model resemble the private variational Bayes algorithm as closely as possible, using the Polya-Gamma data augmentation scheme. The iterative nature of variational Bayes presents a further challenge since iterations increase the amount of noise needed. We overcome this by combining: (1) an improved composition method for differential privacy, called the moments accountant, which provides a tight bound on the privacy cost of multiple VB iterations and thus significantly decreases the amount of additive noise; and (2) the privacy amplification effect of subsampling mini-batches from large-scale data in stochastic learning. We empirically demonstrate the effectiveness of our method in CE and non-CE models including latent Dirichlet allocation, Bayesian logistic regression, and sigmoid belief networks, evaluated on real-world datasets.
HexaConv
Mar 06, 2018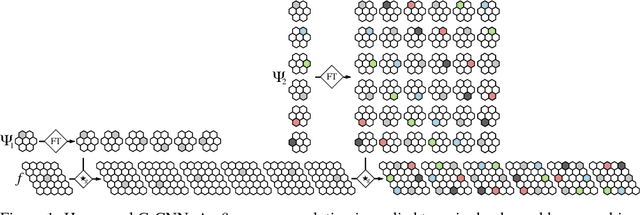
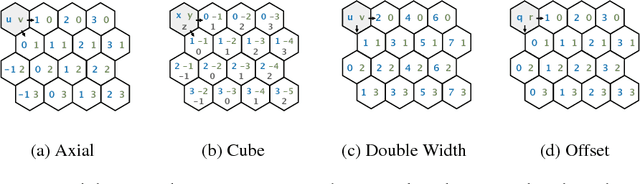
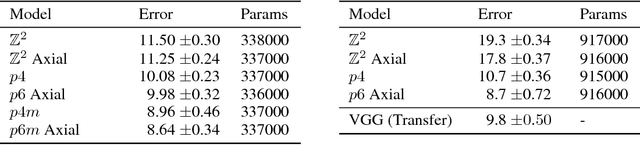
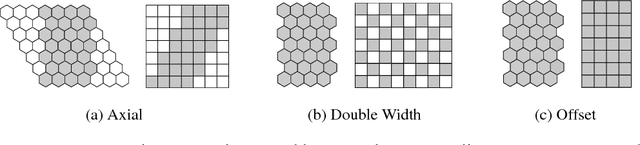
The effectiveness of Convolutional Neural Networks stems in large part from their ability to exploit the translation invariance that is inherent in many learning problems. Recently, it was shown that CNNs can exploit other invariances, such as rotation invariance, by using group convolutions instead of planar convolutions. However, for reasons of performance and ease of implementation, it has been necessary to limit the group convolution to transformations that can be applied to the filters without interpolation. Thus, for images with square pixels, only integer translations, rotations by multiples of 90 degrees, and reflections are admissible. Whereas the square tiling provides a 4-fold rotational symmetry, a hexagonal tiling of the plane has a 6-fold rotational symmetry. In this paper we show how one can efficiently implement planar convolution and group convolution over hexagonal lattices, by re-using existing highly optimized convolution routines. We find that, due to the reduced anisotropy of hexagonal filters, planar HexaConv provides better accuracy than planar convolution with square filters, given a fixed parameter budget. Furthermore, we find that the increased degree of symmetry of the hexagonal grid increases the effectiveness of group convolutions, by allowing for more parameter sharing. We show that our method significantly outperforms conventional CNNs on the AID aerial scene classification dataset, even outperforming ImageNet pre-trained models.
VAE with a VampPrior
Feb 26, 2018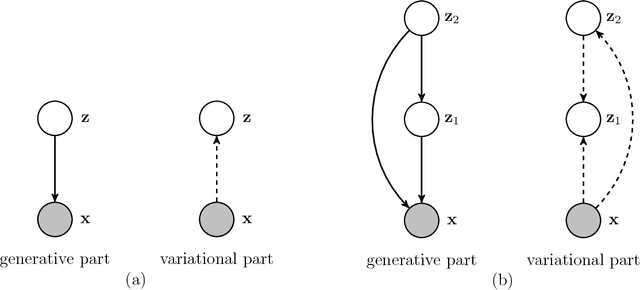
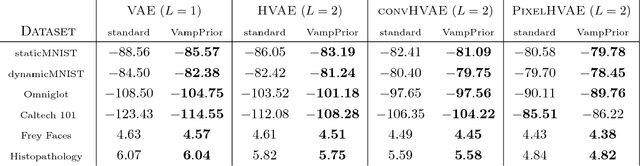
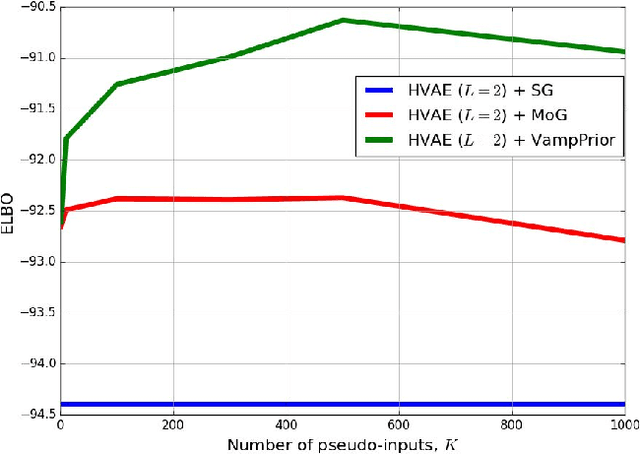
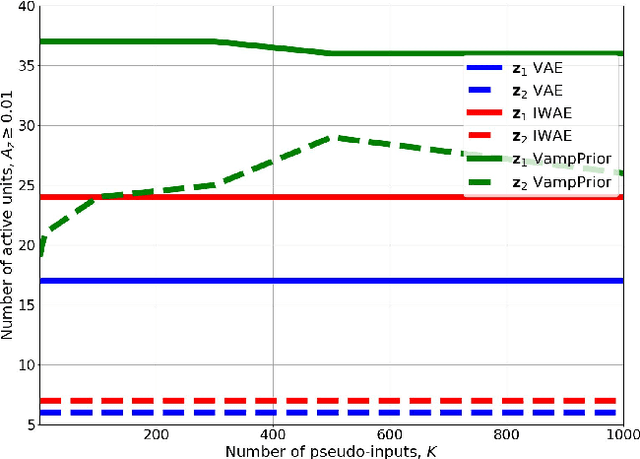
Many different methods to train deep generative models have been introduced in the past. In this paper, we propose to extend the variational auto-encoder (VAE) framework with a new type of prior which we call "Variational Mixture of Posteriors" prior, or VampPrior for short. The VampPrior consists of a mixture distribution (e.g., a mixture of Gaussians) with components given by variational posteriors conditioned on learnable pseudo-inputs. We further extend this prior to a two layer hierarchical model and show that this architecture with a coupled prior and posterior, learns significantly better models. The model also avoids the usual local optima issues related to useless latent dimensions that plague VAEs. We provide empirical studies on six datasets, namely, static and binary MNIST, OMNIGLOT, Caltech 101 Silhouettes, Frey Faces and Histopathology patches, and show that applying the hierarchical VampPrior delivers state-of-the-art results on all datasets in the unsupervised permutation invariant setting and the best results or comparable to SOTA methods for the approach with convolutional networks.
Spherical CNNs
Feb 25, 2018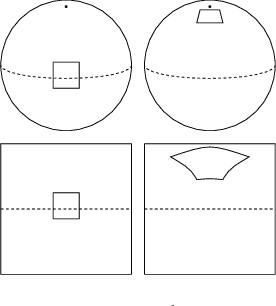
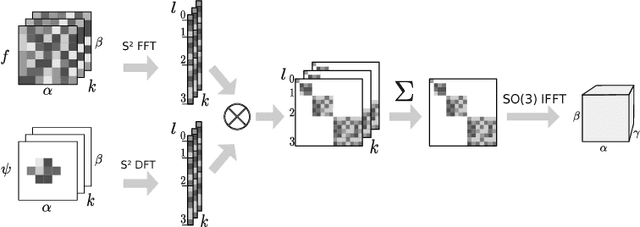

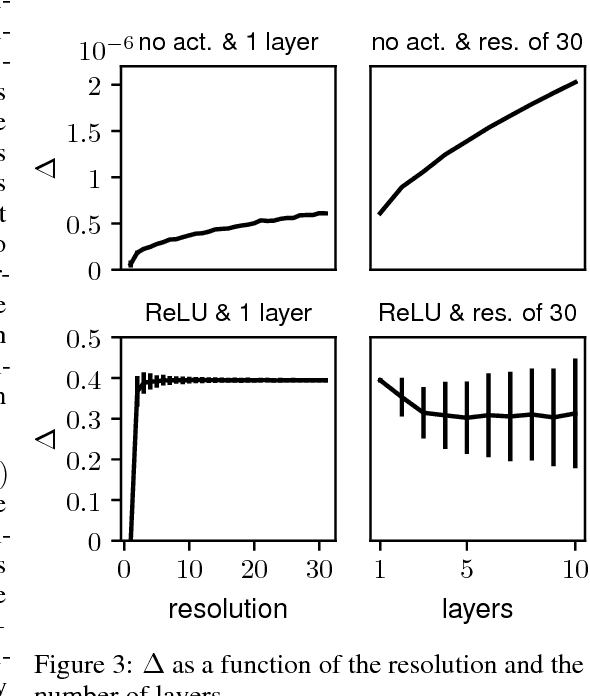
Convolutional Neural Networks (CNNs) have become the method of choice for learning problems involving 2D planar images. However, a number of problems of recent interest have created a demand for models that can analyze spherical images. Examples include omnidirectional vision for drones, robots, and autonomous cars, molecular regression problems, and global weather and climate modelling. A naive application of convolutional networks to a planar projection of the spherical signal is destined to fail, because the space-varying distortions introduced by such a projection will make translational weight sharing ineffective. In this paper we introduce the building blocks for constructing spherical CNNs. We propose a definition for the spherical cross-correlation that is both expressive and rotation-equivariant. The spherical correlation satisfies a generalized Fourier theorem, which allows us to compute it efficiently using a generalized (non-commutative) Fast Fourier Transform (FFT) algorithm. We demonstrate the computational efficiency, numerical accuracy, and effectiveness of spherical CNNs applied to 3D model recognition and atomization energy regression.
Improved Bayesian Compression
Dec 07, 2017
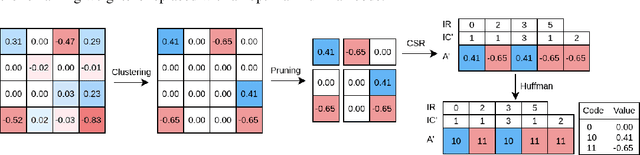
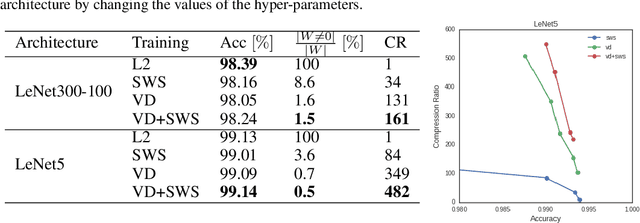
Compression of Neural Networks (NN) has become a highly studied topic in recent years. The main reason for this is the demand for industrial scale usage of NNs such as deploying them on mobile devices, storing them efficiently, transmitting them via band-limited channels and most importantly doing inference at scale. In this work, we propose to join the Soft-Weight Sharing and Variational Dropout approaches that show strong results to define a new state-of-the-art in terms of model compression.
Deep Learning with Permutation-invariant Operator for Multi-instance Histopathology Classification
Dec 05, 2017
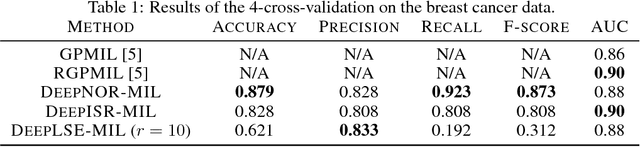
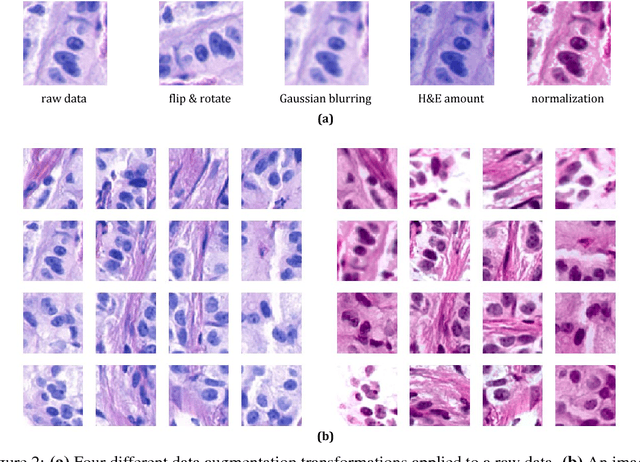
The computer-aided analysis of medical scans is a longstanding goal in the medical imaging field. Currently, deep learning has became a dominant methodology for supporting pathologists and radiologist. Deep learning algorithms have been successfully applied to digital pathology and radiology, nevertheless, there are still practical issues that prevent these tools to be widely used in practice. The main obstacles are low number of available cases and large size of images (a.k.a. the small n, large p problem in machine learning), and a very limited access to annotation at a pixel level that can lead to severe overfitting and large computational requirements. We propose to handle these issues by introducing a framework that processes a medical image as a collection of small patches using a single, shared neural network. The final diagnosis is provided by combining scores of individual patches using a permutation-invariant operator (combination). In machine learning community such approach is called a multi-instance learning (MIL).
Causal Effect Inference with Deep Latent-Variable Models
Nov 06, 2017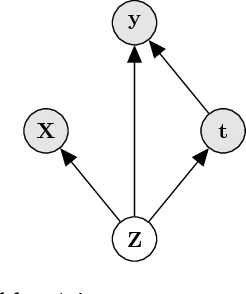
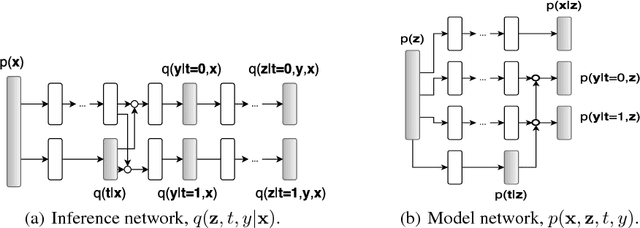
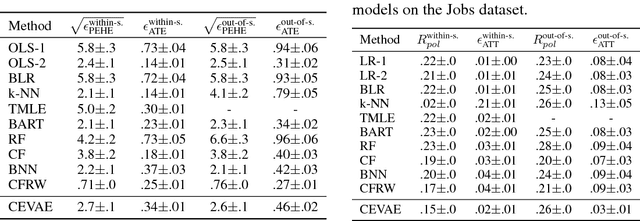
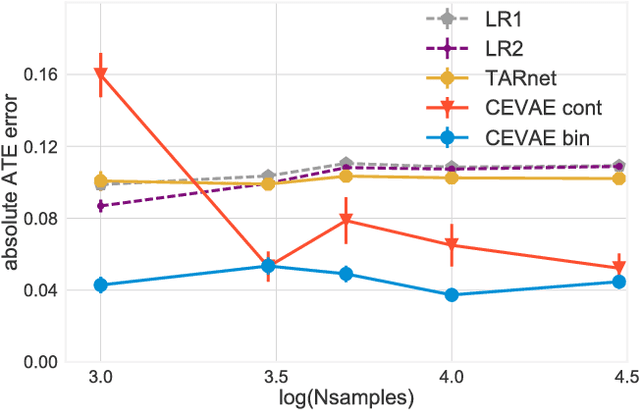
Learning individual-level causal effects from observational data, such as inferring the most effective medication for a specific patient, is a problem of growing importance for policy makers. The most important aspect of inferring causal effects from observational data is the handling of confounders, factors that affect both an intervention and its outcome. A carefully designed observational study attempts to measure all important confounders. However, even if one does not have direct access to all confounders, there may exist noisy and uncertain measurement of proxies for confounders. We build on recent advances in latent variable modeling to simultaneously estimate the unknown latent space summarizing the confounders and the causal effect. Our method is based on Variational Autoencoders (VAE) which follow the causal structure of inference with proxies. We show our method is significantly more robust than existing methods, and matches the state-of-the-art on previous benchmarks focused on individual treatment effects.