 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Subtitle Segmentation for End-to-end Generation Systems
May 19, 2022



Subtitles appear on screen as short pieces of text, segmented based on formal constraints (length) and syntactic/semantic criteria. Subtitle segmentation can be evaluated with sequence segmentation metrics against a human reference. However, standard segmentation metrics cannot be applied when systems generate outputs different than the reference, e.g. with end-to-end subtitling systems. In this paper, we study ways to conduct reference-based evaluations of segmentation accuracy irrespective of the textual content. We first conduct a systematic analysis of existing metrics for evaluating subtitle segmentation. We then introduce $Sigma$, a new Subtitle Segmentation Score derived from an approximate upper-bound of BLEU on segmentation boundaries, which allows us to disentangle the effect of good segmentation from text quality. To compare $Sigma$ with existing metrics, we further propose a boundary projection method from imperfect hypotheses to the true reference. Results show that all metrics are able to reward high quality output but for similar outputs system ranking depends on each metric's sensitivity to error type. Our thorough analyses suggest $Sigma$ is a promising segmentation candidate but its reliability over other segmentation metrics remains to be validated through correlations with human judgements.
Cascade versus Direct Speech Translation: Do the Differences Still Make a Difference?
Jun 02, 2021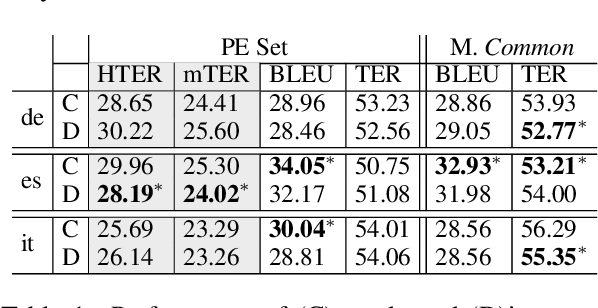
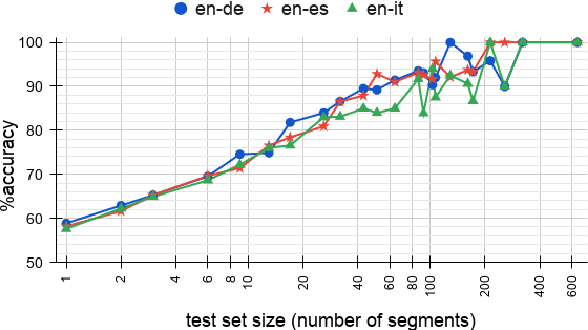
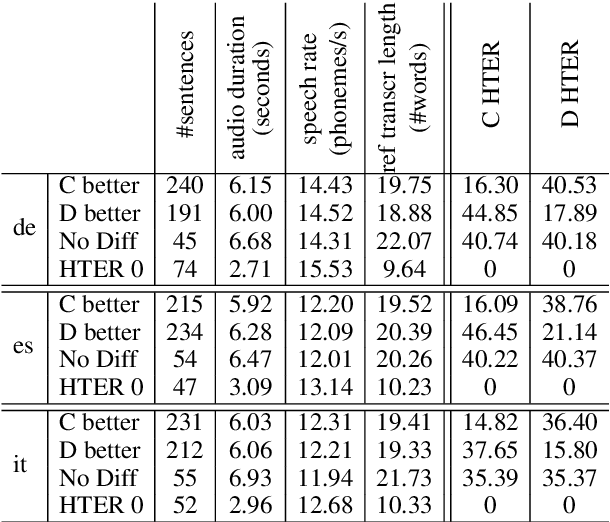

Five years after the first published proofs of concept, direct approaches to speech translation (ST) are now competing with traditional cascade solutions. In light of this steady progress, can we claim that the performance gap between the two is closed? Starting from this question, we present a systematic comparison between state-of-the-art systems representative of the two paradigms. Focusing on three language directions (English-German/Italian/Spanish), we conduct automatic and manual evaluations, exploiting high-quality professional post-edits and annotations. Our multi-faceted analysis on one of the few publicly available ST benchmarks attests for the first time that: i) the gap between the two paradigms is now closed, and ii) the subtle differences observed in their behavior are not sufficient for humans neither to distinguish them nor to prefer one over the other.
Beyond Voice Activity Detection: Hybrid Audio Segmentation for Direct Speech Translation
Apr 23, 2021
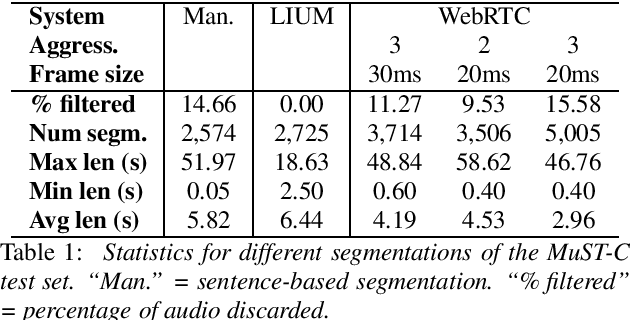
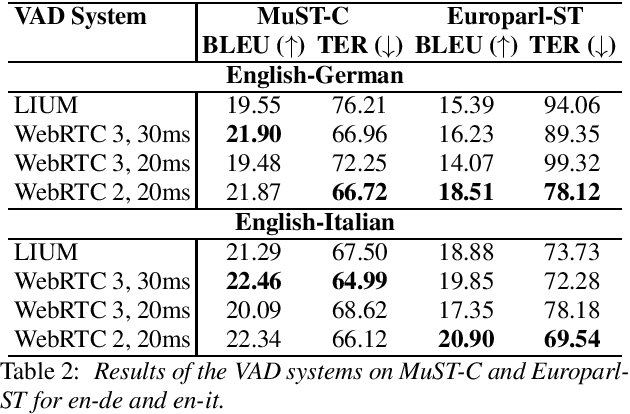
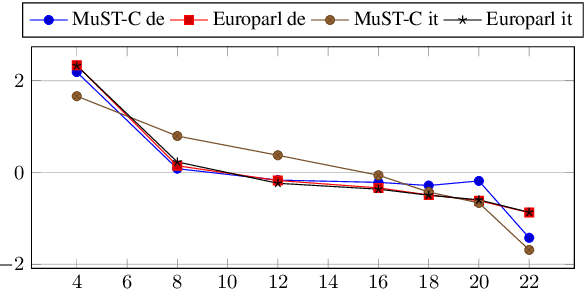
The audio segmentation mismatch between training data and those seen at run-time is a major problem in direct speech translation. Indeed, while systems are usually trained on manually segmented corpora, in real use cases they are often presented with continuous audio requiring automatic (and sub-optimal) segmentation. After comparing existing techniques (VAD-based, fixed-length and hybrid segmentation methods), in this paper we propose enhanced hybrid solutions to produce better results without sacrificing latency. Through experiments on different domains and language pairs, we show that our methods outperform all the other techniques, reducing by at least 30% the gap between the traditional VAD-based approach and optimal manual segmentation.
CTC-based Compression for Direct Speech Translation
Feb 02, 2021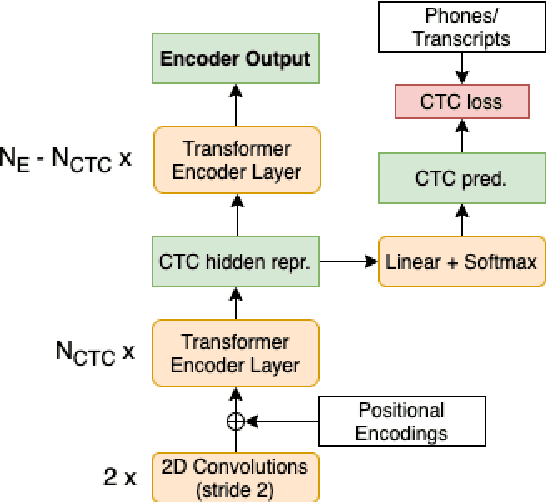
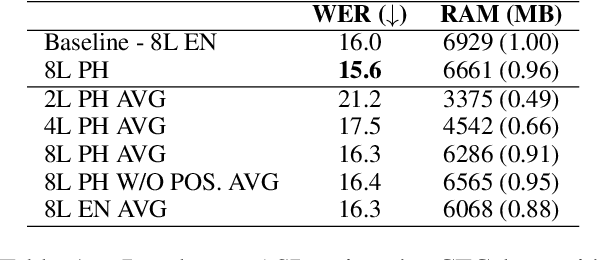
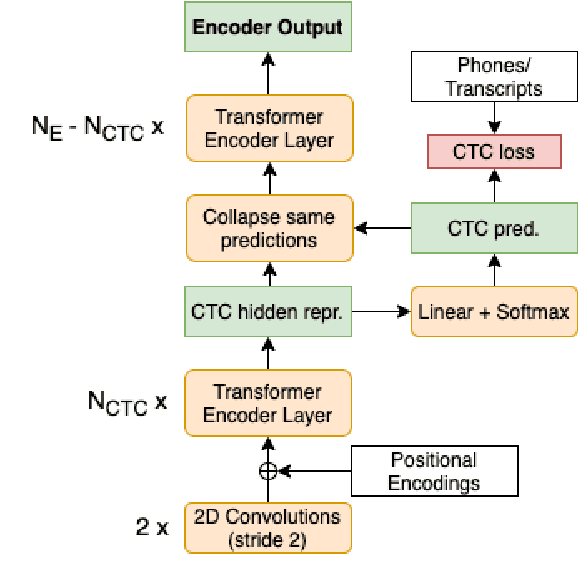
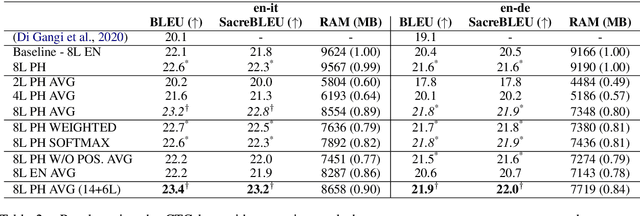
Previous studies demonstrated that a dynamic phone-informed compression of the input audio is beneficial for speech translation (ST). However, they required a dedicated model for phone recognition and did not test this solution for direct ST, in which a single model translates the input audio into the target language without intermediate representations. In this work, we propose the first method able to perform a dynamic compression of the input indirect ST models. In particular, we exploit the Connectionist Temporal Classification (CTC) to compress the input sequence according to its phonetic characteristics. Our experiments demonstrate that our solution brings a 1.3-1.5 BLEU improvement over a strong baseline on two language pairs (English-Italian and English-German), contextually reducing the memory footprint by more than 10%.
Contextualized Translation of Automatically Segmented Speech
Aug 05, 2020
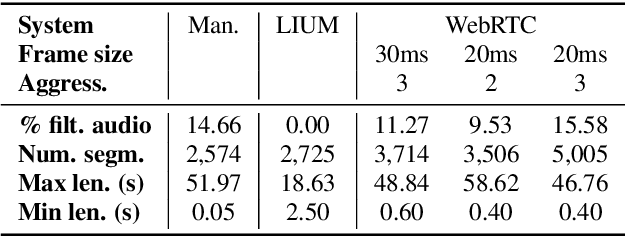
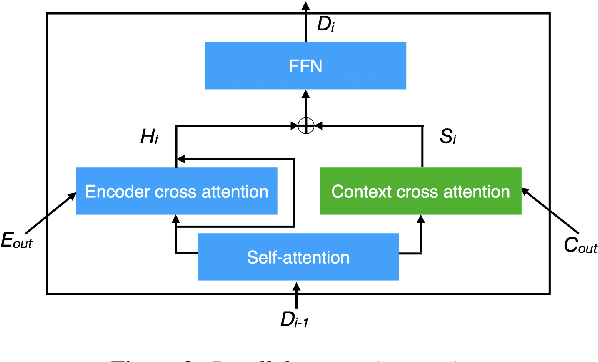
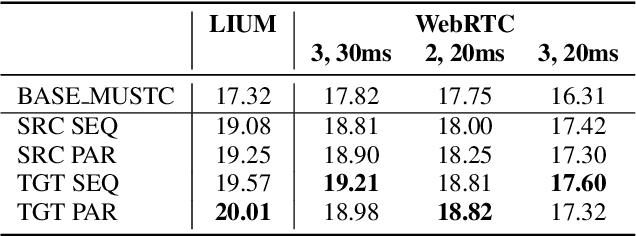
Direct speech-to-text translation (ST) models are usually trained on corpora segmented at sentence level, but at inference time they are commonly fed with audio split by a voice activity detector (VAD). Since VAD segmentation is not syntax-informed, the resulting segments do not necessarily correspond to well-formed sentences uttered by the speaker but, most likely, to fragments of one or more sentences. This segmentation mismatch degrades considerably the quality of ST models' output. So far, researchers have focused on improving audio segmentation towards producing sentence-like splits. In this paper, instead, we address the issue in the model, making it more robust to a different, potentially sub-optimal segmentation. To this aim, we train our models on randomly segmented data and compare two approaches: fine-tuning and adding the previous segment as context. We show that our context-aware solution is more robust to VAD-segmented input, outperforming a strong base model and the fine-tuning on different VAD segmentations of an English-German test set by up to 4.25 BLEU points.
Findings of the 2016 WMT Shared Task on Cross-lingual Pronoun Prediction
Nov 27, 2019
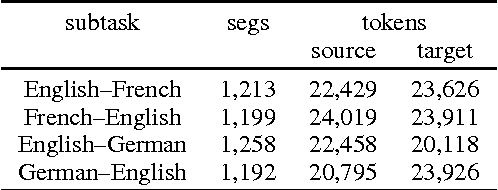

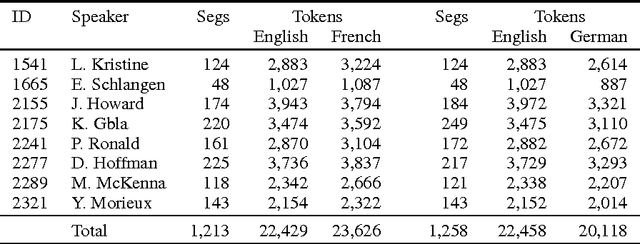
We describe the design, the evaluation setup, and the results of the 2016 WMT shared task on cross-lingual pronoun prediction. This is a classification task in which participants are asked to provide predictions on what pronoun class label should replace a placeholder value in the target-language text, provided in lemmatised and PoS-tagged form. We provided four subtasks, for the English-French and English-German language pairs, in both directions. Eleven teams participated in the shared task; nine for the English-French subtask, five for French-English, nine for English-German, and six for German-English. Most of the submissions outperformed two strong language-model based baseline systems, with systems using deep recurrent neural networks outperforming those using other architectures for most language pairs.
* cross-lingual pronoun prediction, WMT, shared task, English, German, French
A Comparison of Transformer and Recurrent Neural Networks on Multilingual Neural Machine Translation
Jun 20, 2018

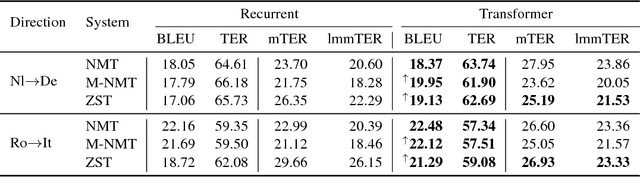
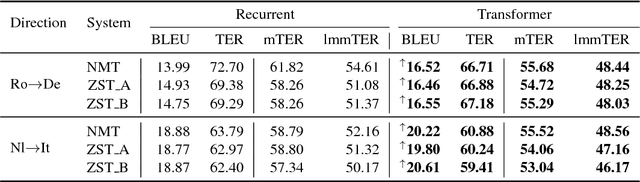
Recently, neural machine translation (NMT) has been extended to multilinguality, that is to handle more than one translation direction with a single system. Multilingual NMT showed competitive performance against pure bilingual systems. Notably, in low-resource settings, it proved to work effectively and efficiently, thanks to shared representation space that is forced across languages and induces a sort of transfer-learning. Furthermore, multilingual NMT enables so-called zero-shot inference across language pairs never seen at training time. Despite the increasing interest in this framework, an in-depth analysis of what a multilingual NMT model is capable of and what it is not is still missing. Motivated by this, our work (i) provides a quantitative and comparative analysis of the translations produced by bilingual, multilingual and zero-shot systems; (ii) investigates the translation quality of two of the currently dominant neural architectures in MT, which are the Recurrent and the Transformer ones; and (iii) quantitatively explores how the closeness between languages influences the zero-shot translation. Our analysis leverages multiple professional post-edits of automatic translations by several different systems and focuses both on automatic standard metrics (BLEU and TER) and on widely used error categories, which are lexical, morphology, and word order errors.
Unsupervised Clustering of Commercial Domains for Adaptive Machine Translation
Dec 14, 2016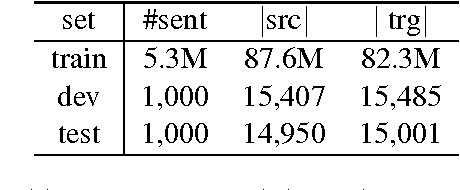
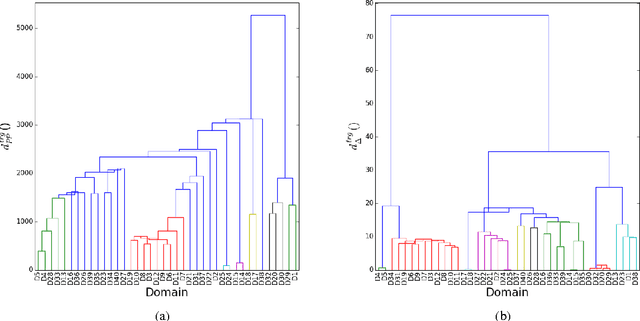
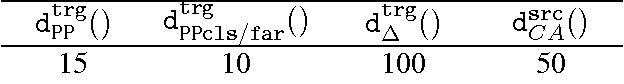
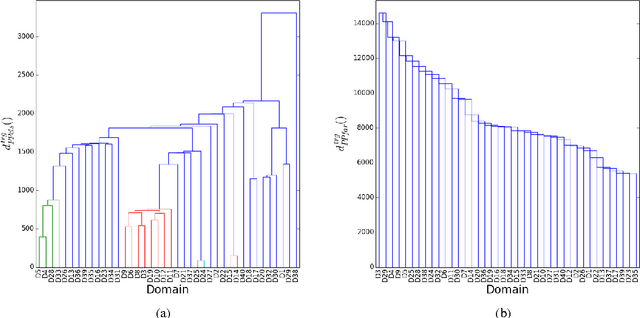
In this paper, we report on domain clustering in the ambit of an adaptive MT architecture. A standard bottom-up hierarchical clustering algorithm has been instantiated with five different distances, which have been compared, on an MT benchmark built on 40 commercial domains, in terms of dendrograms, intrinsic and extrinsic evaluations. The main outcome is that the most expensive distance is also the only one able to allow the MT engine to guarantee good performance even with few, but highly populated clusters of domains.
Neural versus Phrase-Based Machine Translation Quality: a Case Study
Oct 09, 2016
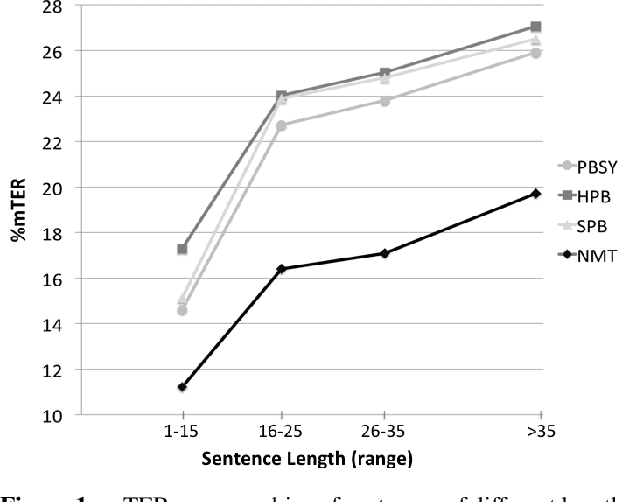
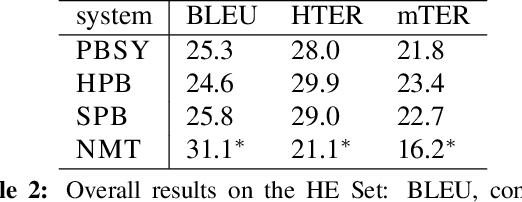
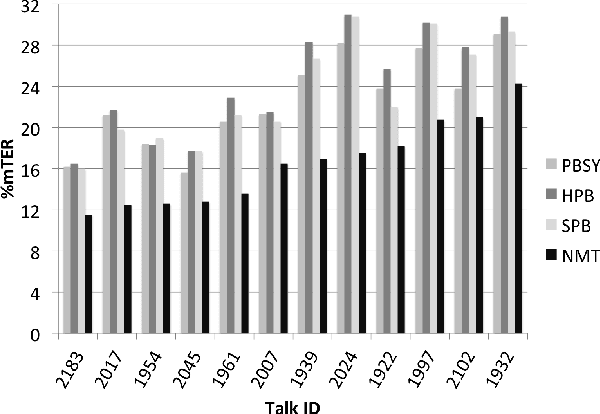
Within the field of Statistical Machine Translation (SMT), the neural approach (NMT) has recently emerged as the first technology able to challenge the long-standing dominance of phrase-based approaches (PBMT). In particular, at the IWSLT 2015 evaluation campaign, NMT outperformed well established state-of-the-art PBMT systems on English-German, a language pair known to be particularly hard because of morphology and syntactic differences. To understand in what respects NMT provides better translation quality than PBMT, we perform a detailed analysis of neural versus phrase-based SMT outputs, leveraging high quality post-edits performed by professional translators on the IWSLT data. For the first time, our analysis provides useful insights on what linguistic phenomena are best modeled by neural models -- such as the reordering of verbs -- while pointing out other aspects that remain to be improved.
An Arabic-Hebrew parallel corpus of TED talks
Oct 03, 2016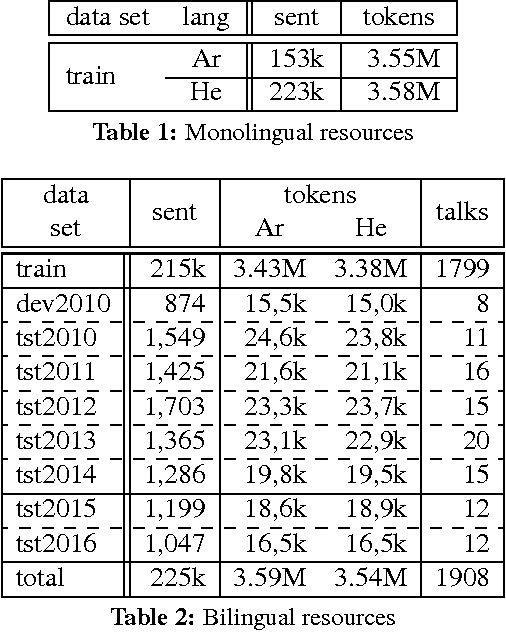
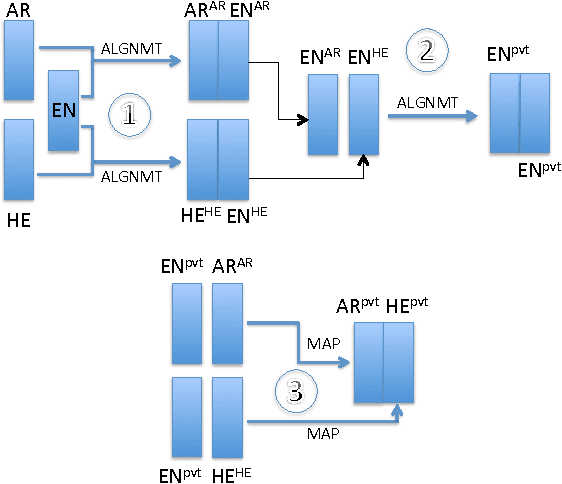
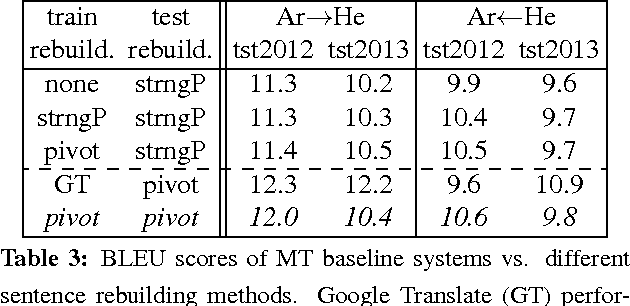
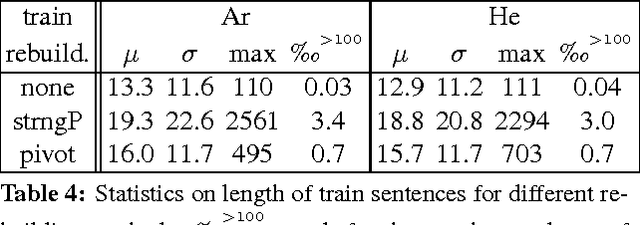
We describe an Arabic-Hebrew parallel corpus of TED talks built upon WIT3, the Web inventory that repurposes the original content of the TED website in a way which is more convenient for MT researchers. The benchmark consists of about 2,000 talks, whose subtitles in Arabic and Hebrew have been accurately aligned and rearranged in sentences, for a total of about 3.5M tokens per language. Talks have been partitioned in train, development and test sets similarly in all respects to the MT tasks of the IWSLT 2016 evaluation campaign. In addition to describing the benchmark, we list the problems encountered in preparing it and the novel methods designed to solve them. Baseline MT results and some measures on sentence length are provided as an extrinsic evaluation of the quality of the benchmark.