 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning In Environments With Polynomial Mixing Times
Dec 13, 2021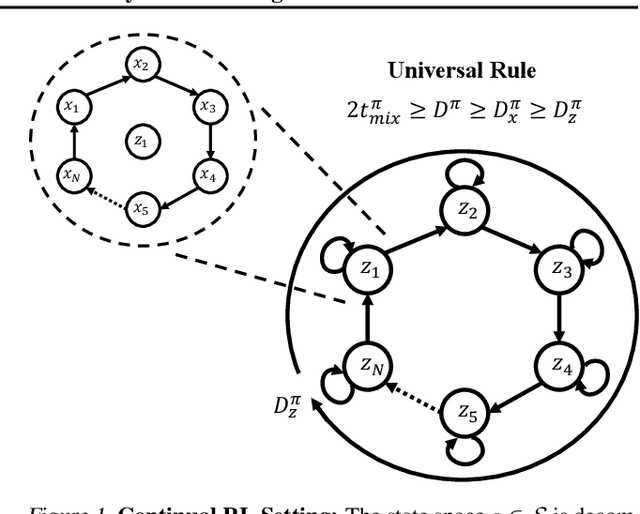

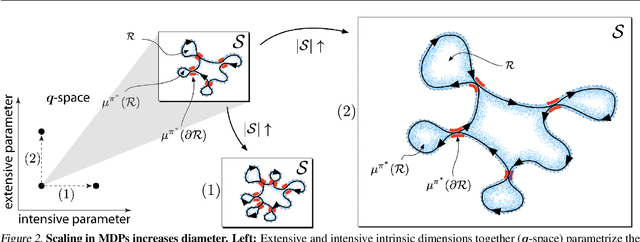
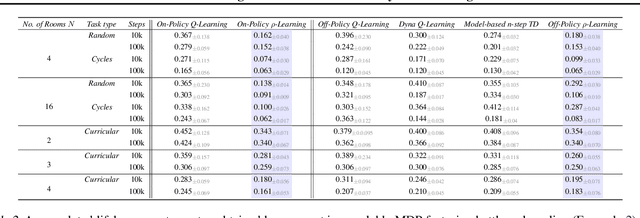
The mixing time of the Markov chain induced by a policy limits performance in real-world continual learning scenarios. Yet, the effect of mixing times on learning in continual reinforcement learning (RL) remains underexplored. In this paper, we characterize problems that are of long-term interest to the development of continual RL, which we call scalable MDPs, through the lens of mixing times. In particular, we establish that scalable MDPs have mixing times that scale polynomially with the size of the problem. We go on to demonstrate that polynomial mixing times present significant difficulties for existing approaches and propose a family of model-based algorithms that speed up learning by directly optimizing for the average reward through a novel bootstrapping procedure. Finally, we perform empirical regret analysis of our proposed approaches, demonstrating clear improvements over baselines and also how scalable MDPs can be used for analysis of RL algorithms as mixing times scale.
Context-Specific Representation Abstraction for Deep Option Learning
Sep 20, 2021
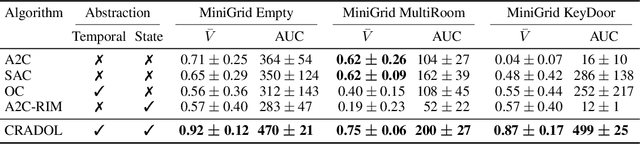
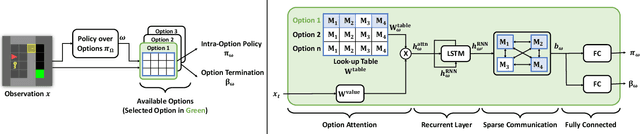
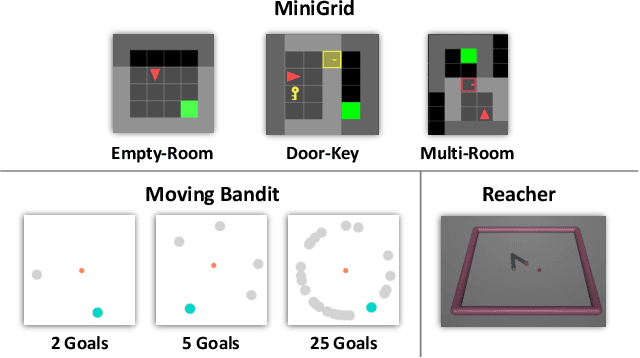
Hierarchical reinforcement learning has focused on discovering temporally extended actions, such as options, that can provide benefits in problems requiring extensive exploration. One promising approach that learns these options end-to-end is the option-critic (OC) framework. We examine and show in this paper that OC does not decompose a problem into simpler sub-problems, but instead increases the size of the search over policy space with each option considering the entire state space during learning. This issue can result in practical limitations of this method, including sample inefficient learning. To address this problem, we introduce Context-Specific Representation Abstraction for Deep Option Learning (CRADOL), a new framework that considers both temporal abstraction and context-specific representation abstraction to effectively reduce the size of the search over policy space. Specifically, our method learns a factored belief state representation that enables each option to learn a policy over only a subsection of the state space. We test our method against hierarchical, non-hierarchical, and modular recurrent neural network baselines, demonstrating significant sample efficiency improvements in challenging partially observable environments.
Towards Continual Reinforcement Learning: A Review and Perspectives
Dec 25, 2020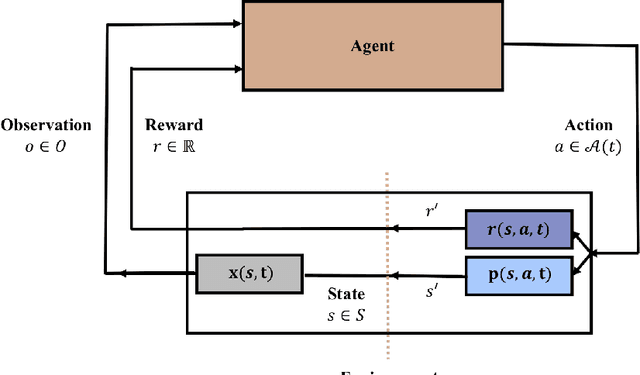

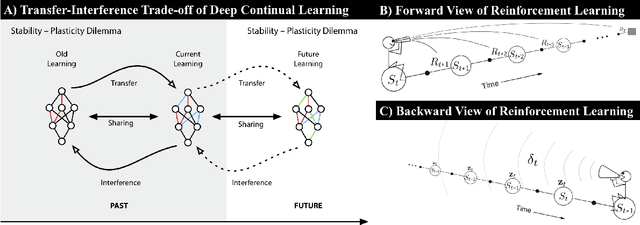
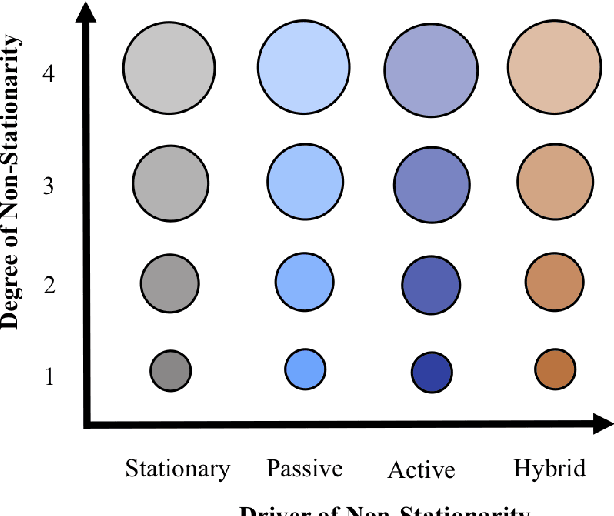
In this article, we aim to provide a literature review of different formulations and approaches to continual reinforcement learning (RL), also known as lifelong or non-stationary RL. We begin by discussing our perspective on why RL is a natural fit for studying continual learning. We then provide a taxonomy of different continual RL formulations and mathematically characterize the non-stationary dynamics of each setting. We go on to discuss evaluation of continual RL agents, providing an overview of benchmarks used in the literature and important metrics for understanding agent performance. Finally, we highlight open problems and challenges in bridging the gap between the current state of continual RL and findings in neuroscience. While still in its early days, the study of continual RL has the promise to develop better incremental reinforcement learners that can function in increasingly realistic applications where non-stationarity plays a vital role. These include applications such as those in the fields of healthcare, education, logistics, and robotics.
Consolidation via Policy Information Regularization in Deep RL for Multi-Agent Games
Nov 23, 2020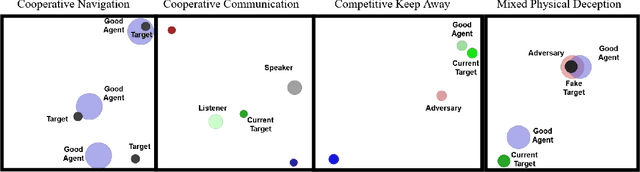
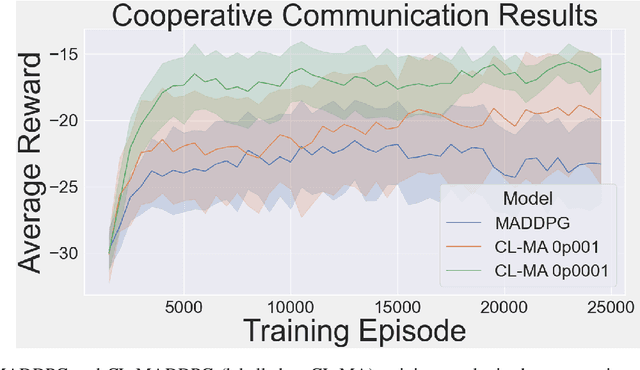
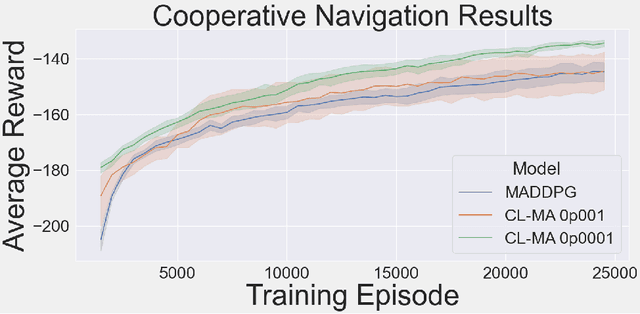
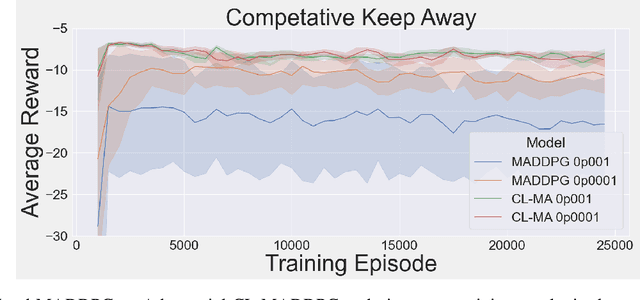
This paper introduces an information-theoretic constraint on learned policy complexity in the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) reinforcement learning algorithm. Previous research with a related approach in continuous control experiments suggests that this method favors learning policies that are more robust to changing environment dynamics. The multi-agent game setting naturally requires this type of robustness, as other agents' policies change throughout learning, introducing a nonstationary environment. For this reason, recent methods in continual learning are compared to our approach, termed Capacity-Limited MADDPG. Results from experimentation in multi-agent cooperative and competitive tasks demonstrate that the capacity-limited approach is a good candidate for improving learning performance in these environments.
A Policy Gradient Algorithm for Learning to Learn in Multiagent Reinforcement Learning
Oct 31, 2020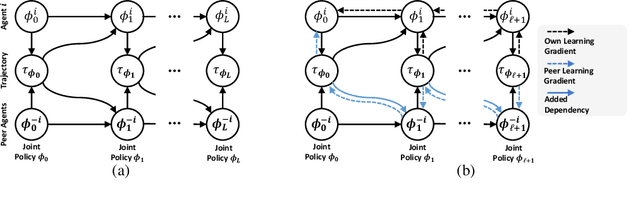
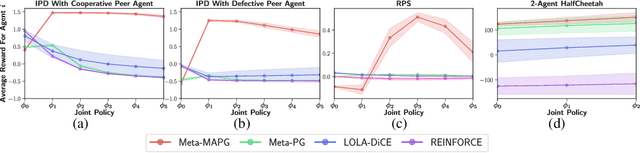

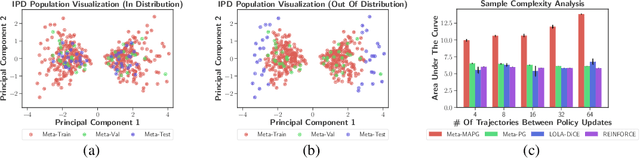
A fundamental challenge in multiagent reinforcement learning is to learn beneficial behaviors in a shared environment with other agents that are also simultaneously learning. In particular, each agent perceives the environment as effectively non-stationary due to the changing policies of other agents. Moreover, each agent is itself constantly learning, leading to natural nonstationarity in the distribution of experiences encountered. In this paper, we propose a novel meta-multiagent policy gradient theorem that directly accommodates for the non-stationary policy dynamics inherent to these multiagent settings. This is achieved by modeling our gradient updates to directly consider both an agent's own non-stationary policy dynamics and the non-stationary policy dynamics of other agents interacting with it in the environment. We find that our theoretically grounded approach provides a general solution to the multiagent learning problem, which inherently combines key aspects of previous state of the art approaches on this topic. We test our method on several multiagent benchmarks and demonstrate a more efficient ability to adapt to new agents as they learn than previous related approaches across the spectrum of mixed incentive, competitive, and cooperative environments.
Deep RL With Information Constrained Policies: Generalization in Continuous Control
Oct 09, 2020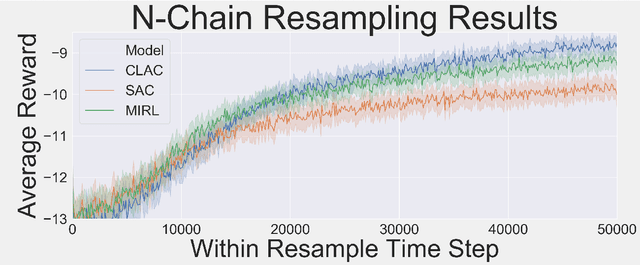
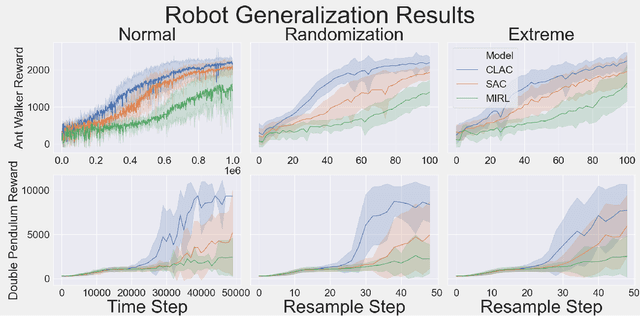
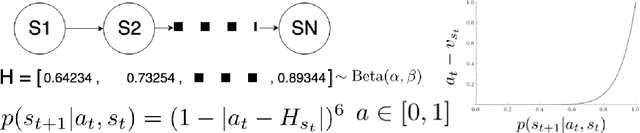
Biological agents learn and act intelligently in spite of a highly limited capacity to process and store information. Many real-world problems involve continuous control, which represents a difficult task for artificial intelligence agents. In this paper we explore the potential learning advantages a natural constraint on information flow might confer onto artificial agents in continuous control tasks. We focus on the model-free reinforcement learning (RL) setting and formalize our approach in terms of an information-theoretic constraint on the complexity of learned policies. We show that our approach emerges in a principled fashion from the application of rate-distortion theory. We implement a novel Capacity-Limited Actor-Critic (CLAC) algorithm and situate it within a broader family of RL algorithms such as the Soft Actor Critic (SAC) and Mutual Information Reinforcement Learning (MIRL) algorithm. Our experiments using continuous control tasks show that compared to alternative approaches, CLAC offers improvements in generalization between training and modified test environments. This is achieved in the CLAC model while displaying the high sample efficiency of similar methods.
A Study of Compositional Generalization in Neural Models
Jul 08, 2020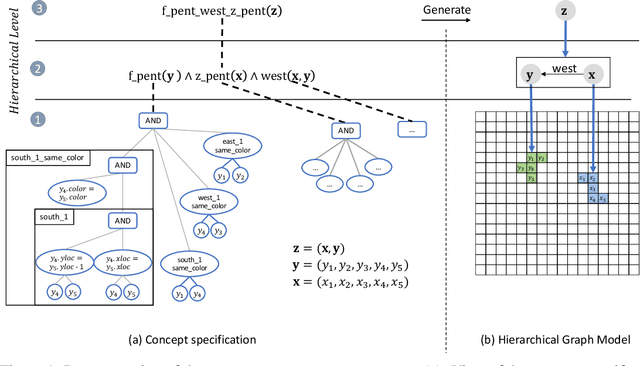
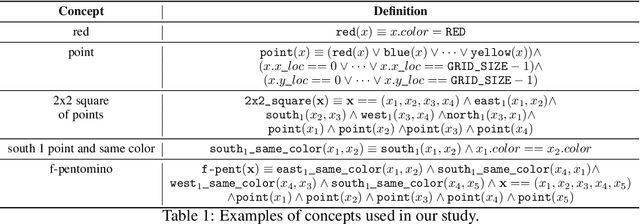
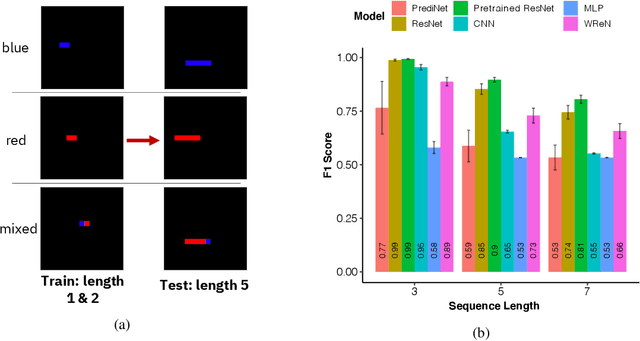
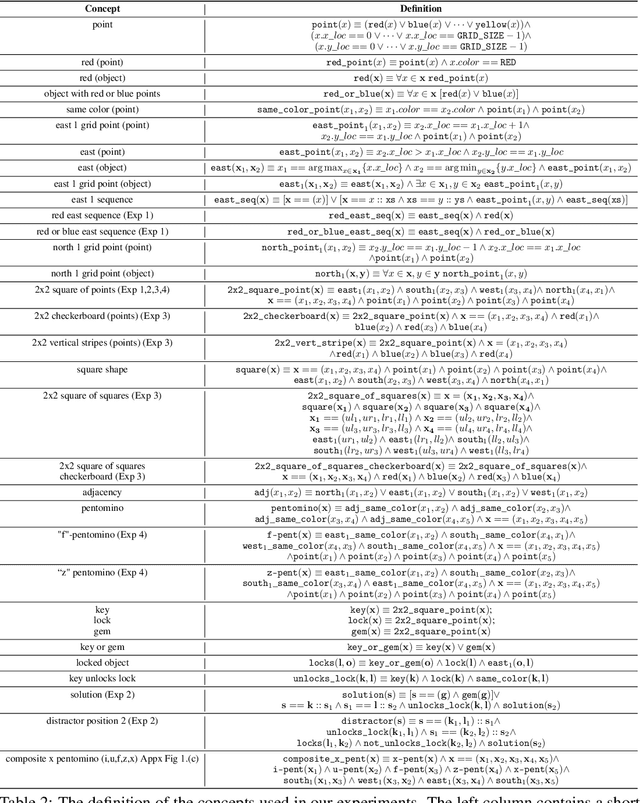
Compositional and relational learning is a hallmark of human intelligence, but one which presents challenges for neural models. One difficulty in the development of such models is the lack of benchmarks with clear compositional and relational task structure on which to systematically evaluate them. In this paper, we introduce an environment called ConceptWorld, which enables the generation of images from compositional and relational concepts, defined using a logical domain specific language. We use it to generate images for a variety of compositional structures: 2x2 squares, pentominoes, sequences, scenes involving these objects, and other more complex concepts. We perform experiments to test the ability of standard neural architectures to generalize on relations with compositional arguments as the compositional depth of those arguments increases and under substitution. We compare standard neural networks such as MLP, CNN and ResNet, as well as state-of-the-art relational networks including WReN and PrediNet in a multi-class image classification setting. For simple problems, all models generalize well to close concepts but struggle with longer compositional chains. For more complex tests involving substitutivity, all models struggle, even with short chains. In highlighting these difficulties and providing an environment for further experimentation, we hope to encourage the development of models which are able to generalize effectively in compositional, relational domains.
Finding Macro-Actions with Disentangled Effects for Efficient Planning with the Goal-Count Heuristic
Apr 28, 2020

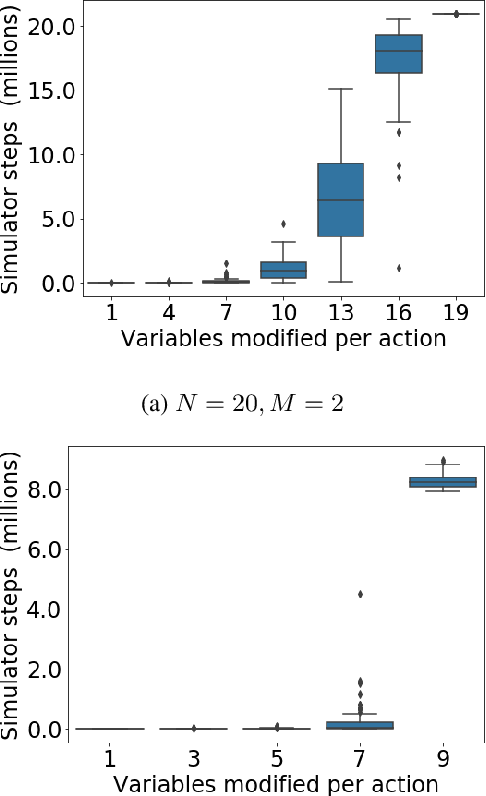

The difficulty of classical planning increases exponentially with search-tree depth. Heuristic search can make planning more efficient, but good heuristics often require domain-specific assumptions and may not generalize to new problems. Rather than treating the planning problem as fixed and carefully designing a heuristic to match it, we instead construct macro-actions that support efficient planning with the simple and general-purpose "goal-count" heuristic. Our approach searches for macro-actions that modify only a small number of state variables (we call this measure "entanglement"). We show experimentally that reducing entanglement exponentially decreases planning time with the goal-count heuristic. Our method discovers macro-actions with disentangled effects that dramatically improve planning efficiency for 15-puzzle and Rubik's cube, reliably solving each domain without prior knowledge, and solving Rubik's cube with orders of magnitude less data than competing approaches.
On the Role of Weight Sharing During Deep Option Learning
Feb 06, 2020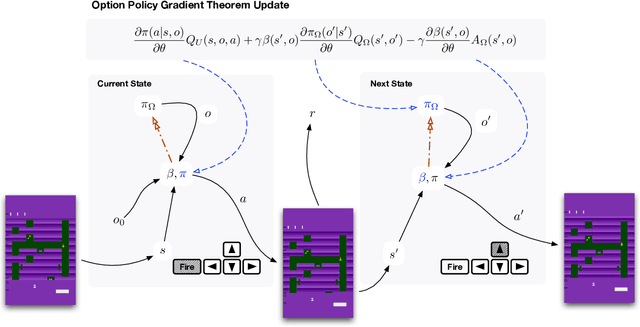
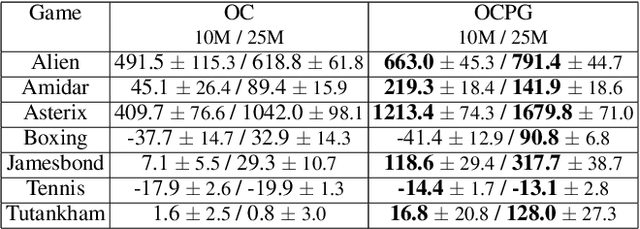


The options framework is a popular approach for building temporally extended actions in reinforcement learning. In particular, the option-critic architecture provides general purpose policy gradient theorems for learning actions from scratch that are extended in time. However, past work makes the key assumption that each of the components of option-critic has independent parameters. In this work we note that while this key assumption of the policy gradient theorems of option-critic holds in the tabular case, it is always violated in practice for the deep function approximation setting. We thus reconsider this assumption and consider more general extensions of option-critic and hierarchical option-critic training that optimize for the full architecture with each update. It turns out that not assuming parameter independence challenges a belief in prior work that training the policy over options can be disentangled from the dynamics of the underlying options. In fact, learning can be sped up by focusing the policy over options on states where options are actually likely to terminate. We put our new algorithms to the test in application to sample efficient learning of Atari games, and demonstrate significantly improved stability and faster convergence when learning long options.
Hierarchical Average Reward Policy Gradient Algorithms
Nov 20, 2019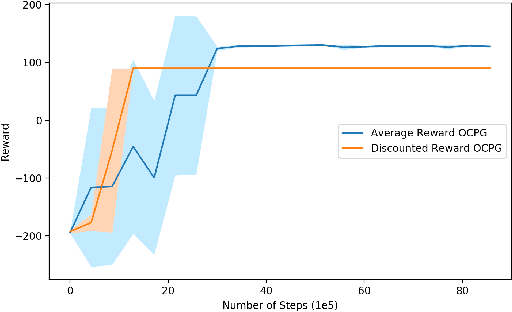
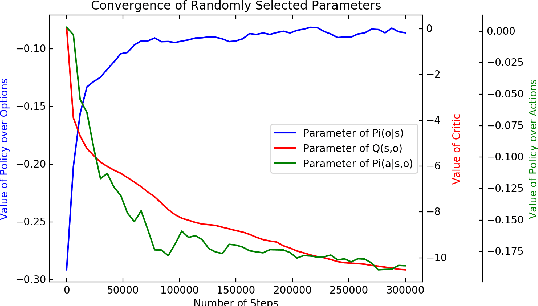
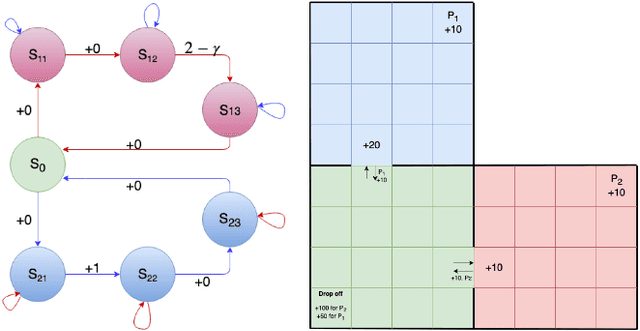
Option-critic learning is a general-purpose reinforcement learning (RL) framework that aims to address the issue of long term credit assignment by leveraging temporal abstractions. However, when dealing with extended timescales, discounting future rewards can lead to incorrect credit assignments. In this work, we address this issue by extending the hierarchical option-critic policy gradient theorem for the average reward criterion. Our proposed framework aims to maximize the long-term reward obtained in the steady-state of the Markov chain defined by the agent's policy. Furthermore, we use an ordinary differential equation based approach for our convergence analysis and prove that the parameters of the intra-option policies, termination functions, and value functions, converge to their corresponding optimal values, with probability one. Finally, we illustrate the competitive advantage of learning options, in the average reward setting, on a grid-world environment with sparse rewards.