 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Conceptual Framework for Externally-influenced Agents: An Assisted Reinforcement Learning Review
Jul 03, 2020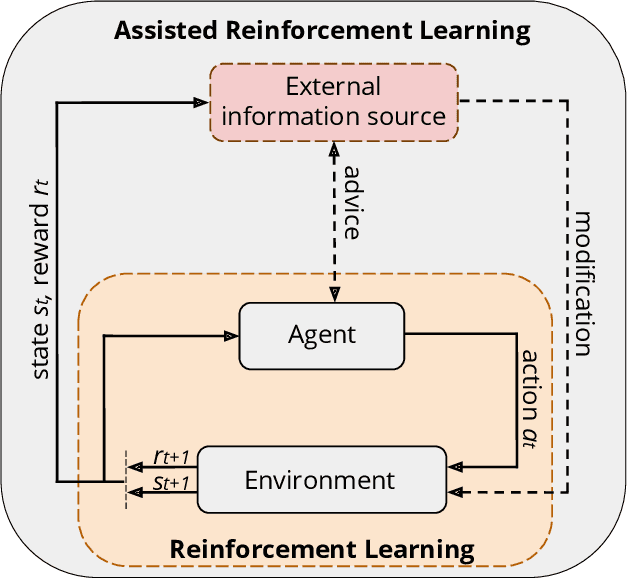
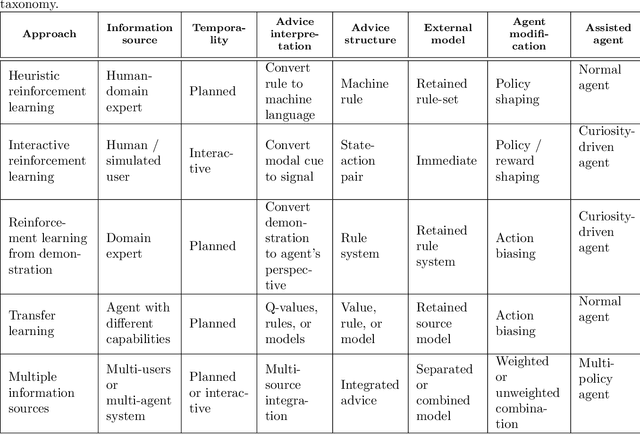
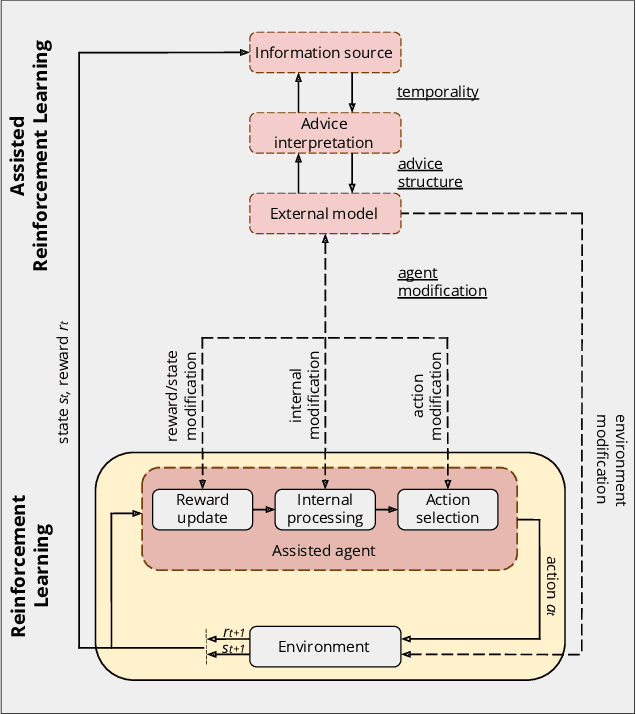
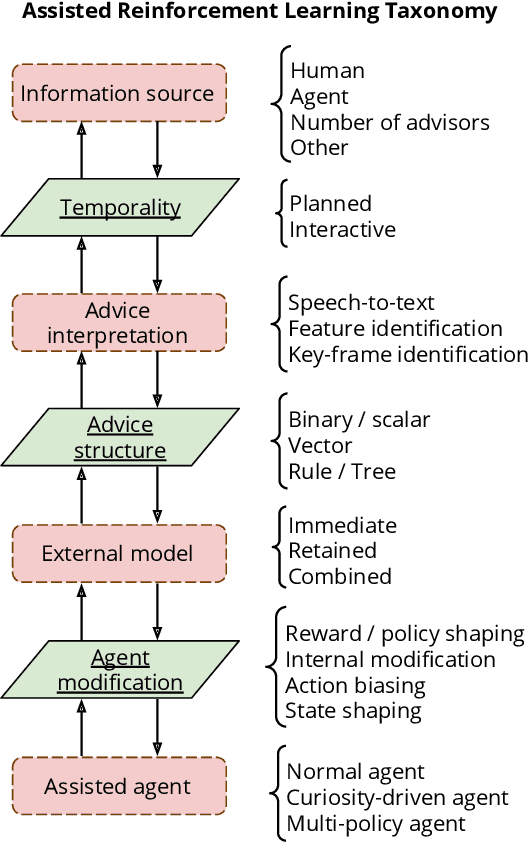
A long-term goal of reinforcement learning agents is to be able to perform tasks in complex real-world scenarios. The use of external information is one way of scaling agents to more complex problems. However, there is a general lack of collaboration or interoperability between different approaches using external information. In this work, we propose a conceptual framework and taxonomy for assisted reinforcement learning, aimed at fostering such collaboration by classifying and comparing various methods that use external information in the learning process. The proposed taxonomy details the relationship between the external information source and the learner agent, highlighting the process of information decomposition, structure, retention, and how it can be used to influence agent learning. As well as reviewing state-of-the-art methods, we identify current streams of reinforcement learning that use external information in order to improve the agent's performance and its decision-making process. These include heuristic reinforcement learning, interactive reinforcement learning, learning from demonstration, transfer learning, and learning from multiple sources, among others. These streams of reinforcement learning operate with the shared objective of scaffolding the learner agent. Lastly, we discuss further possibilities for future work in the field of assisted reinforcement learning systems.
Work in Progress: Temporally Extended Auxiliary Tasks
Apr 16, 2020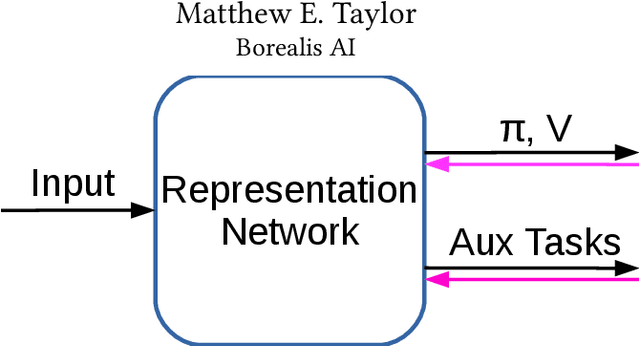

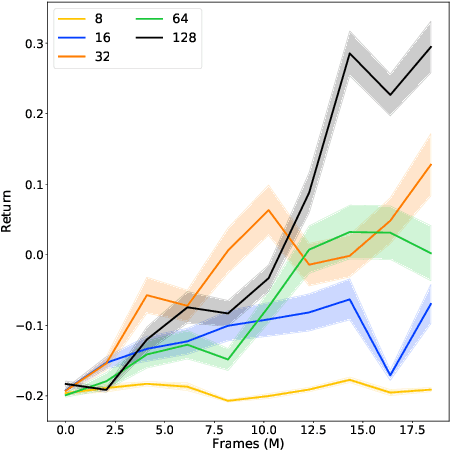
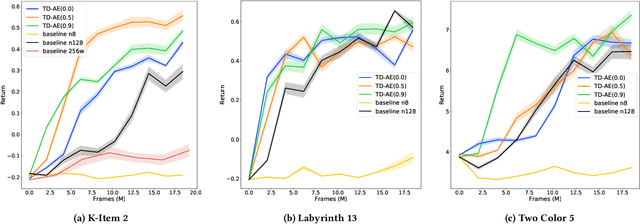
Predictive auxiliary tasks have been shown to improve performance in numerous reinforcement learning works, however, this effect is still not well understood. The primary purpose of the work presented here is to investigate the impact that an auxiliary task's prediction timescale has on the agent's policy performance. We consider auxiliary tasks which learn to make on-policy predictions using temporal difference learning. We test the impact of prediction timescale using a specific form of auxiliary task in which the input image is used as the prediction target, which we refer to as temporal difference autoencoders (TD-AE). We empirically evaluate the effect of TD-AE on the A2C algorithm in the VizDoom environment using different prediction timescales. While we do not observe a clear relationship between the prediction timescale on performance, we make the following observations: 1) using auxiliary tasks allows us to reduce the trajectory length of the A2C algorithm, 2) in some cases temporally extended TD-AE performs better than a straight autoencoder, 3) performance with auxiliary tasks is sensitive to the weight placed on the auxiliary loss, 4) despite this sensitivity, auxiliary tasks improved performance without extensive hyper-parameter tuning. Our overall conclusions are that TD-AE increases the robustness of the A2C algorithm to the trajectory length and while promising, further study is required to fully understand the relationship between auxiliary task prediction timescale and the agent's performance.
Curriculum Learning for Reinforcement Learning Domains: A Framework and Survey
Mar 10, 2020

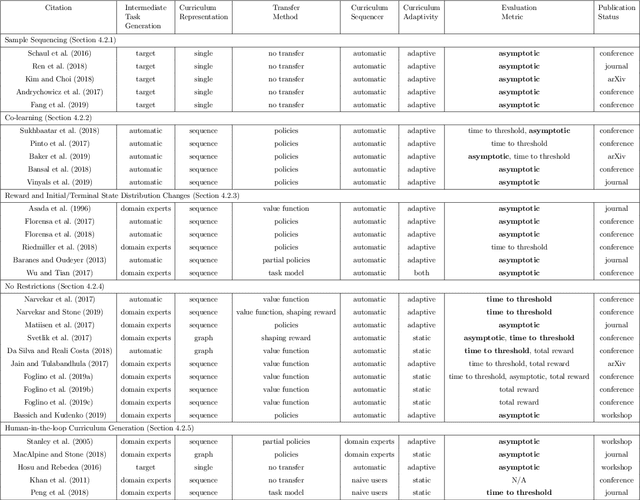
Reinforcement learning (RL) is a popular paradigm for addressing sequential decision tasks in which the agent has only limited environmental feedback. Despite many advances over the past three decades, learning in many domains still requires a large amount of interaction with the environment, which can be prohibitively expensive in realistic scenarios. To address this problem, transfer learning has been applied to reinforcement learning such that experience gained in one task can be leveraged when starting to learn the next, harder task. More recently, several lines of research have explored how tasks, or data samples themselves, can be sequenced into a curriculum for the purpose of learning a problem that may otherwise be too difficult to learn from scratch. In this article, we present a framework for curriculum learning (CL) in reinforcement learning, and use it to survey and classify existing CL methods in terms of their assumptions, capabilities, and goals. Finally, we use our framework to find open problems and suggest directions for future RL curriculum learning research.
Multi Type Mean Field Reinforcement Learning
Mar 09, 2020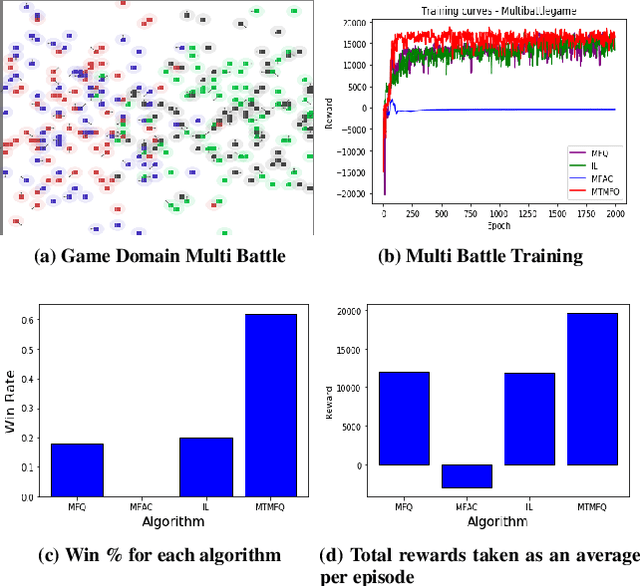
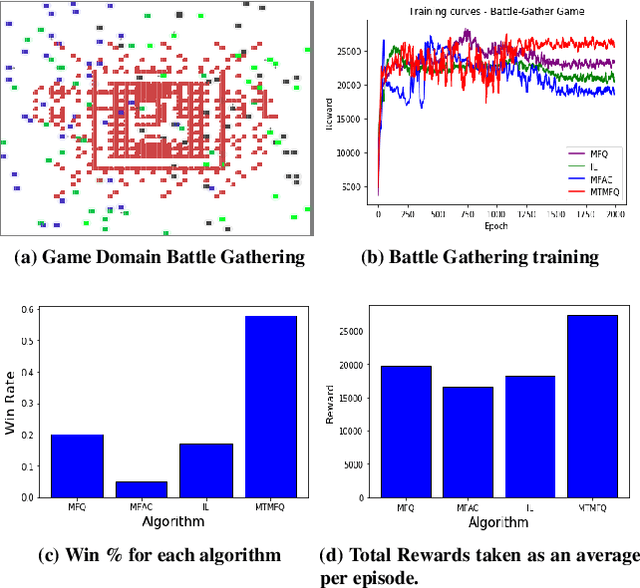
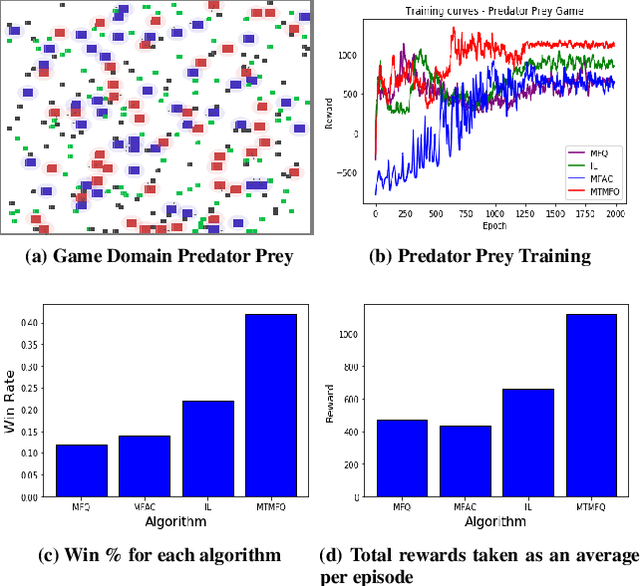
Mean field theory provides an effective way of scaling multiagent reinforcement learning algorithms to environments with many agents that can be abstracted by a virtual mean agent. In this paper, we extend mean field multiagent algorithms to multiple types. The types enable the relaxation of a core assumption in mean field games, which is that all agents in the environment are playing almost similar strategies and have the same goal. We conduct experiments on three different testbeds for the field of many agent reinforcement learning, based on the standard MAgents framework. We consider two different kinds of mean field games: a) Games where agents belong to predefined types that are known a priori and b) Games where the type of each agent is unknown and therefore must be learned based on observations. We introduce new algorithms for each type of game and demonstrate their superior performance over state of the art algorithms that assume that all agents belong to the same type and other baseline algorithms in the MAgent framework.
On Hard Exploration for Reinforcement Learning: a Case Study in Pommerman
Jul 26, 2019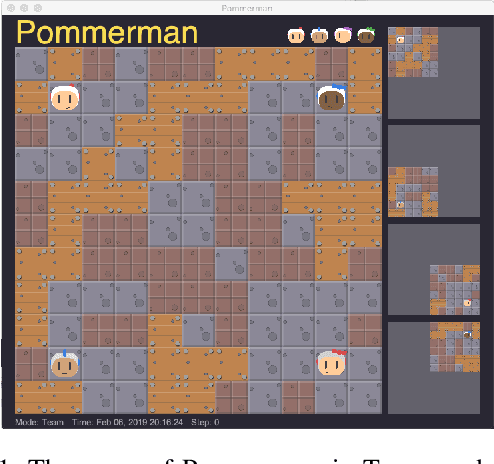
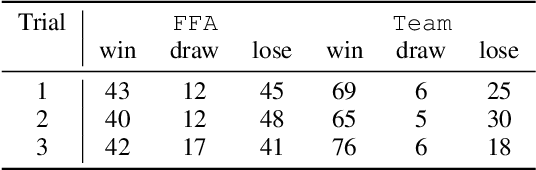
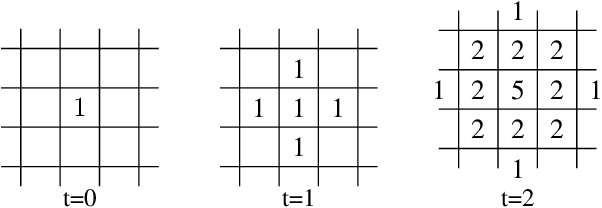
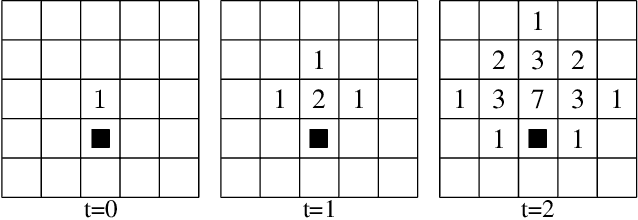
How to best explore in domains with sparse, delayed, and deceptive rewards is an important open problem for reinforcement learning (RL). This paper considers one such domain, the recently-proposed multi-agent benchmark of Pommerman. This domain is very challenging for RL --- past work has shown that model-free RL algorithms fail to achieve significant learning without artificially reducing the environment's complexity. In this paper, we illuminate reasons behind this failure by providing a thorough analysis on the hardness of random exploration in Pommerman. While model-free random exploration is typically futile, we develop a model-based automatic reasoning module that can be used for safer exploration by pruning actions that will surely lead the agent to death. We empirically demonstrate that this module can significantly improve learning.
Action Guidance with MCTS for Deep Reinforcement Learning
Jul 25, 2019
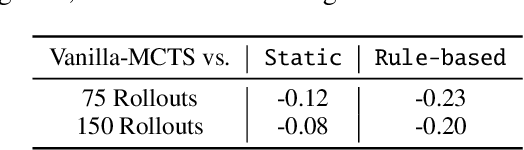
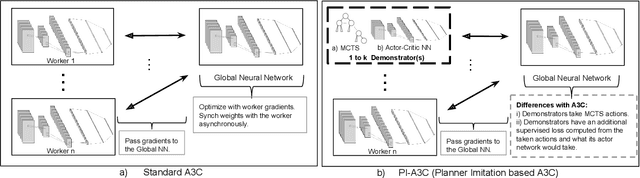
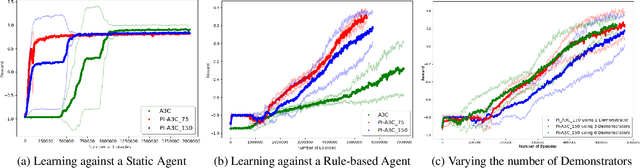
Deep reinforcement learning has achieved great successes in recent years, however, one main challenge is the sample inefficiency. In this paper, we focus on how to use action guidance by means of a non-expert demonstrator to improve sample efficiency in a domain with sparse, delayed, and possibly deceptive rewards: the recently-proposed multi-agent benchmark of Pommerman. We propose a new framework where even a non-expert simulated demonstrator, e.g., planning algorithms such as Monte Carlo tree search with a small number rollouts, can be integrated within asynchronous distributed deep reinforcement learning methods. Compared to a vanilla deep RL algorithm, our proposed methods both learn faster and converge to better policies on a two-player mini version of the Pommerman game.
Terminal Prediction as an Auxiliary Task for Deep Reinforcement Learning
Jul 24, 2019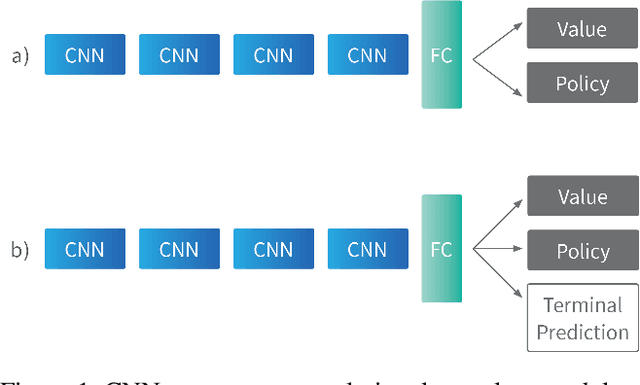

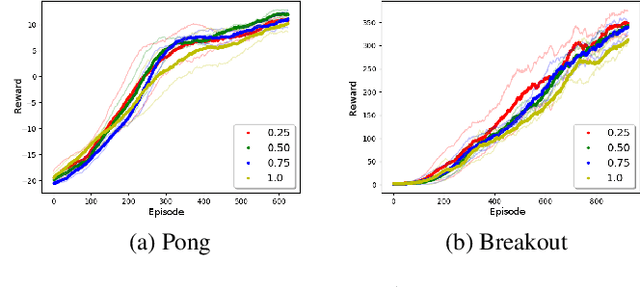

Deep reinforcement learning has achieved great successes in recent years, but there are still open challenges, such as convergence to locally optimal policies and sample inefficiency. In this paper, we contribute a novel self-supervised auxiliary task, i.e., Terminal Prediction (TP), estimating temporal closeness to terminal states for episodic tasks. The intuition is to help representation learning by letting the agent predict how close it is to a terminal state, while learning its control policy. Although TP could be integrated with multiple algorithms, this paper focuses on Asynchronous Advantage Actor-Critic (A3C) and demonstrating the advantages of A3C-TP. Our extensive evaluation includes: a set of Atari games, the BipedalWalker domain, and a mini version of the recently proposed multi-agent Pommerman game. Our results on Atari games and the BipedalWalker domain suggest that A3C-TP outperforms standard A3C in most of the tested domains and in others it has similar performance. In Pommerman, our proposed method provides significant improvement both in learning efficiency and converging to better policies against different opponents.
Agent Modeling as Auxiliary Task for Deep Reinforcement Learning
Jul 22, 2019
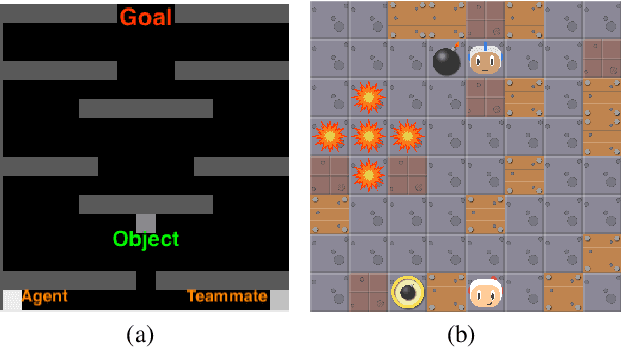
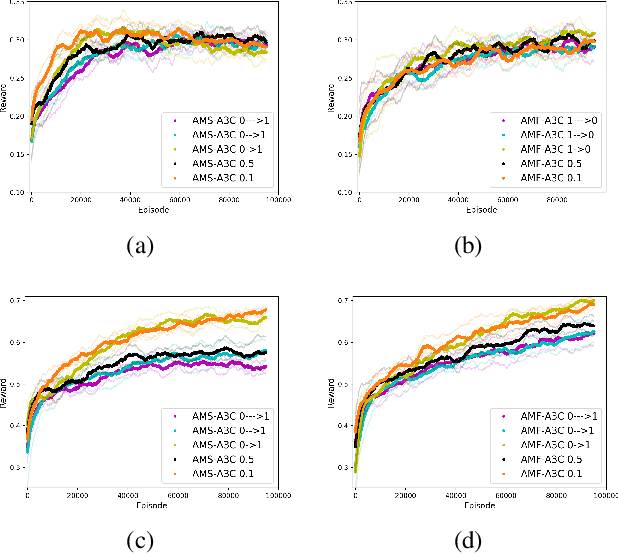
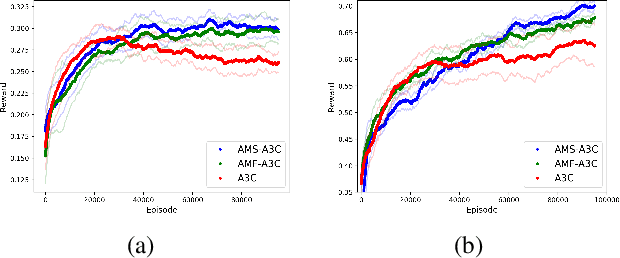
In this paper we explore how actor-critic methods in deep reinforcement learning, in particular Asynchronous Advantage Actor-Critic (A3C), can be extended with agent modeling. Inspired by recent works on representation learning and multiagent deep reinforcement learning, we propose two architectures to perform agent modeling: the first one based on parameter sharing, and the second one based on agent policy features. Both architectures aim to learn other agents' policies as auxiliary tasks, besides the standard actor (policy) and critic (values). We performed experiments in both cooperative and competitive domains. The former is a problem of coordinated multiagent object transportation and the latter is a two-player mini version of the Pommerman game. Our results show that the proposed architectures stabilize learning and outperform the standard A3C architecture when learning a best response in terms of expected rewards.
Interactive Learning of Environment Dynamics for Sequential Tasks
Jul 19, 2019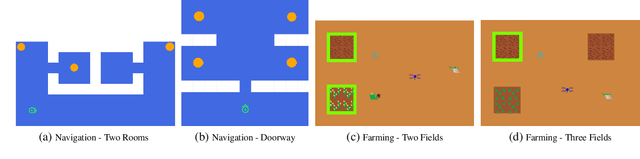
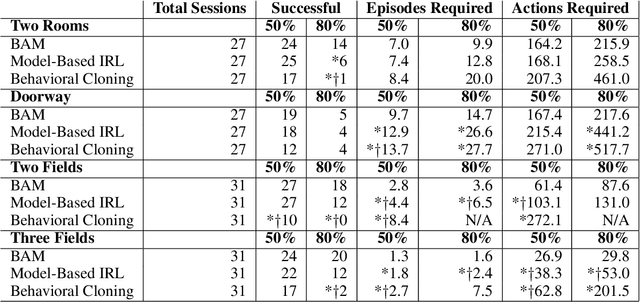
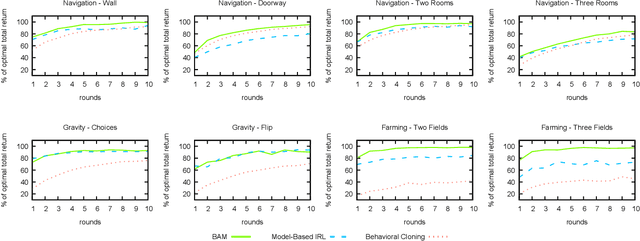
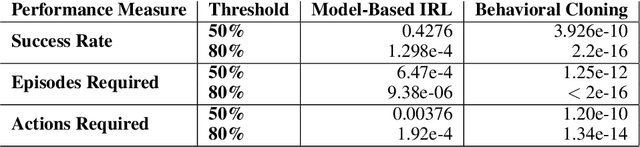
In order for robots and other artificial agents to efficiently learn to perform useful tasks defined by an end user, they must understand not only the goals of those tasks, but also the structure and dynamics of that user's environment. While existing work has looked at how the goals of a task can be inferred from a human teacher, the agent is often left to learn about the environment on its own. To address this limitation, we develop an algorithm, Behavior Aware Modeling (BAM), which incorporates a teacher's knowledge into a model of the transition dynamics of an agent's environment. We evaluate BAM both in simulation and with real human teachers, learning from a combination of task demonstrations and evaluative feedback, and show that it can outperform approaches which do not explicitly consider this source of dynamics knowledge.
Skynet: A Top Deep RL Agent in the Inaugural Pommerman Team Competition
Apr 20, 2019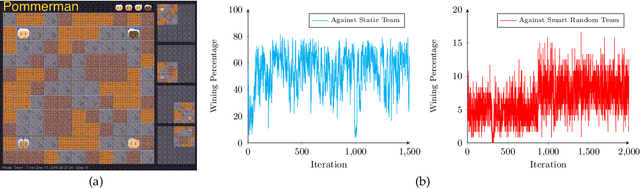

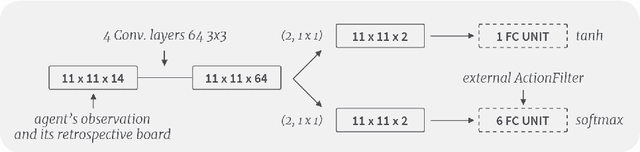

The Pommerman Team Environment is a recently proposed benchmark which involves a multi-agent domain with challenges such as partial observability, decentralized execution (without communication), and very sparse and delayed rewards. The inaugural Pommerman Team Competition held at NeurIPS 2018 hosted 25 participants who submitted a team of 2 agents. Our submission nn_team_skynet955_skynet955 won 2nd place of the "learning agents'' category. Our team is composed of 2 neural networks trained with state of the art deep reinforcement learning algorithms and makes use of concepts like reward shaping, curriculum learning, and an automatic reasoning module for action pruning. Here, we describe these elements and additionally we present a collection of open-sourced agents that can be used for training and testing in the Pommerman environment. Code available at: https://github.com/BorealisAI/pommerman-baseline