 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Visual Classification with Real-World Data Distribution
Mar 18, 2020
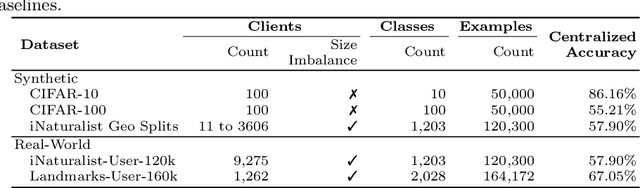
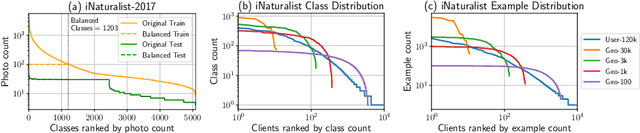
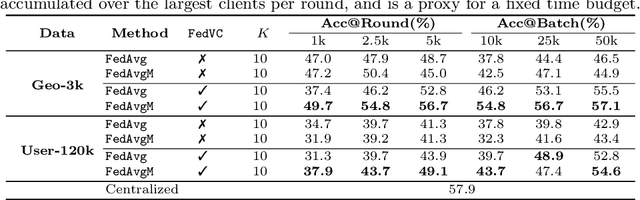
Federated Learning enables visual models to be trained on-device, bringing advantages for user privacy (data need never leave the device), but challenges in terms of data diversity and quality. Whilst typical models in the datacenter are trained using data that are independent and identically distributed (IID), data at source are typically far from IID. Furthermore, differing quantities of data are typically available at each device (imbalance). In this work, we characterize the effect these real-world data distributions have on distributed learning, using as a benchmark the standard Federated Averaging (FedAvg) algorithm. To do so, we introduce two new large-scale datasets for species and landmark classification, with realistic per-user data splits that simulate real-world edge learning scenarios. We also develop two new algorithms (FedVC, FedIR) that intelligently resample and reweight over the client pool, bringing large improvements in accuracy and stability in training.
AirSim Drone Racing Lab
Mar 12, 2020



Autonomous drone racing is a challenging research problem at the intersection of computer vision, planning, state estimation, and control. We introduce AirSim Drone Racing Lab, a simulation framework for enabling fast prototyping of algorithms for autonomy and enabling machine learning research in this domain, with the goal of reducing the time, money, and risks associated with field robotics. Our framework enables generation of racing tracks in multiple photo-realistic environments, orchestration of drone races, comes with a suite of gate assets, allows for multiple sensor modalities (monocular, depth, neuromorphic events, optical flow), different camera models, and benchmarking of planning, control, computer vision, and learning-based algorithms. We used our framework to host a simulation based drone racing competition at NeurIPS 2019. The competition binaries are available at our github repository.
Measuring the Effects of Non-Identical Data Distribution for Federated Visual Classification
Sep 13, 2019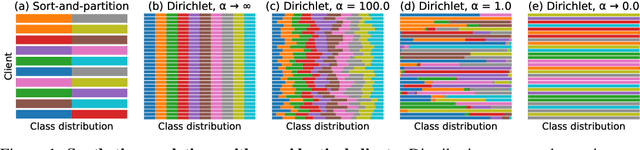
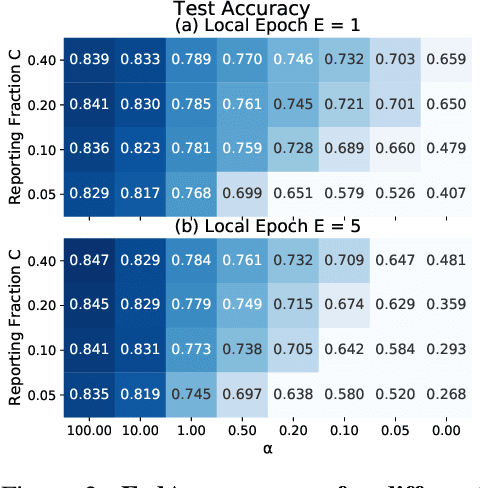
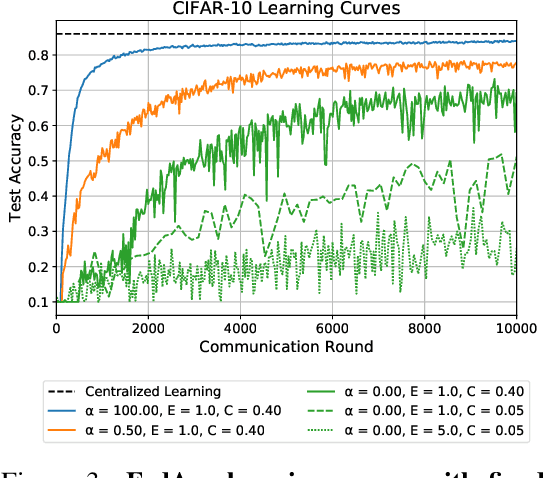
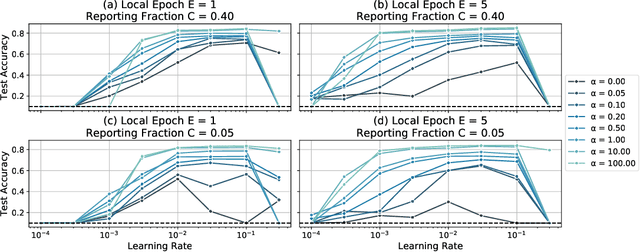
Federated Learning enables visual models to be trained in a privacy-preserving way using real-world data from mobile devices. Given their distributed nature, the statistics of the data across these devices is likely to differ significantly. In this work, we look at the effect such non-identical data distributions has on visual classification via Federated Learning. We propose a way to synthesize datasets with a continuous range of identicalness and provide performance measures for the Federated Averaging algorithm. We show that performance degrades as distributions differ more, and propose a mitigation strategy via server momentum. Experiments on CIFAR-10 demonstrate improved classification performance over a range of non-identicalness, with classification accuracy improved from 30.1% to 76.9% in the most skewed settings.
Contingency Model Predictive Control for Automated Vehicles
Mar 21, 2019
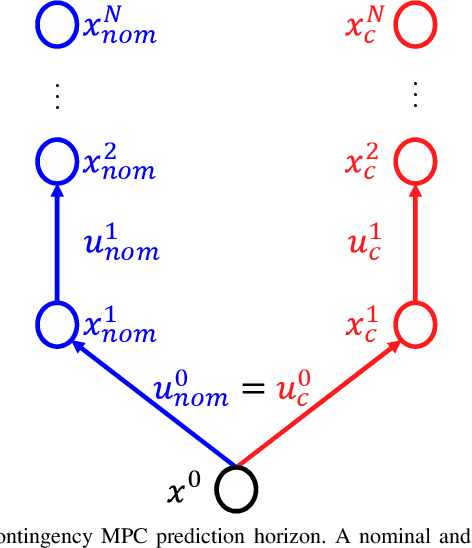
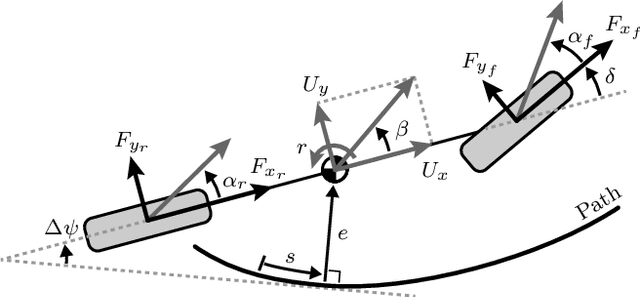
We present Contingency Model Predictive Control (CMPC), a novel and implementable control framework which tracks a desired path while simultaneously maintaining a contingency plan -- an alternate trajectory to avert an identified potential emergency. In this way, CMPC anticipates events that might take place, instead of reacting when emergencies occur. We accomplish this by adding an additional prediction horizon in parallel to the classical receding MPC horizon. The contingency horizon is constrained to maintain a feasible avoidance solution; as such, CMPC is selectively robust to this emergency while tracking the desired path as closely as possible. After defining the framework mathematically, we demonstrate its effectiveness experimentally by comparing its performance to a state-of-the-art deterministic MPC. The controllers drive an automated research platform through a left-hand turn which may be covered by ice. Contingency MPC prepares for the potential loss of friction by purposefully and intuitively deviating from the prescribed path to approach the turn more conservatively; this deviation significantly mitigates the consequence of encountering ice.
Extreme Augmentation : Can deep learning based medical image segmentation be trained using a single manually delineated scan?
Oct 03, 2018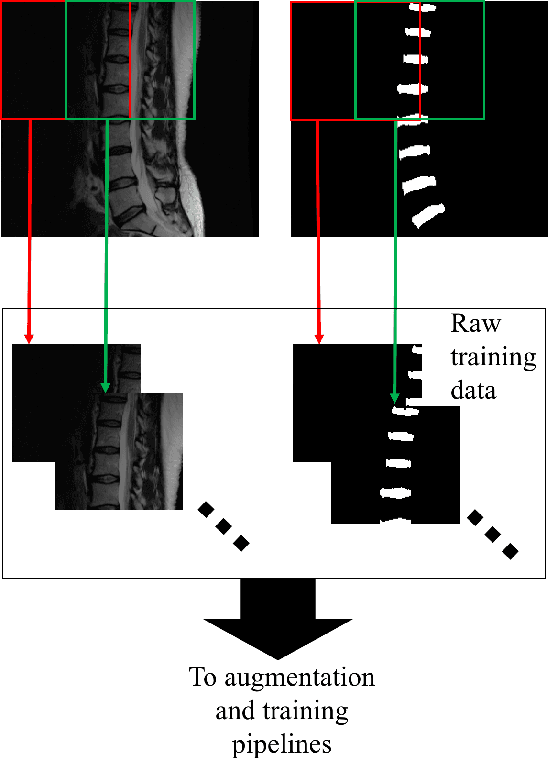
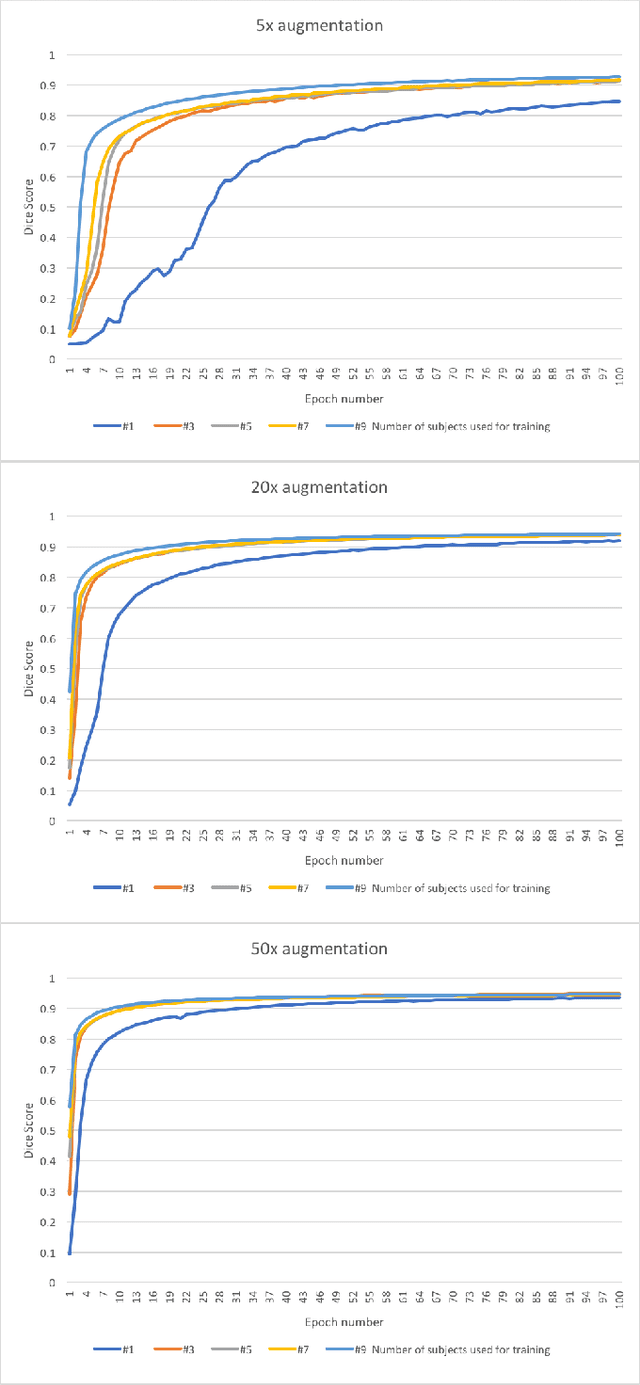
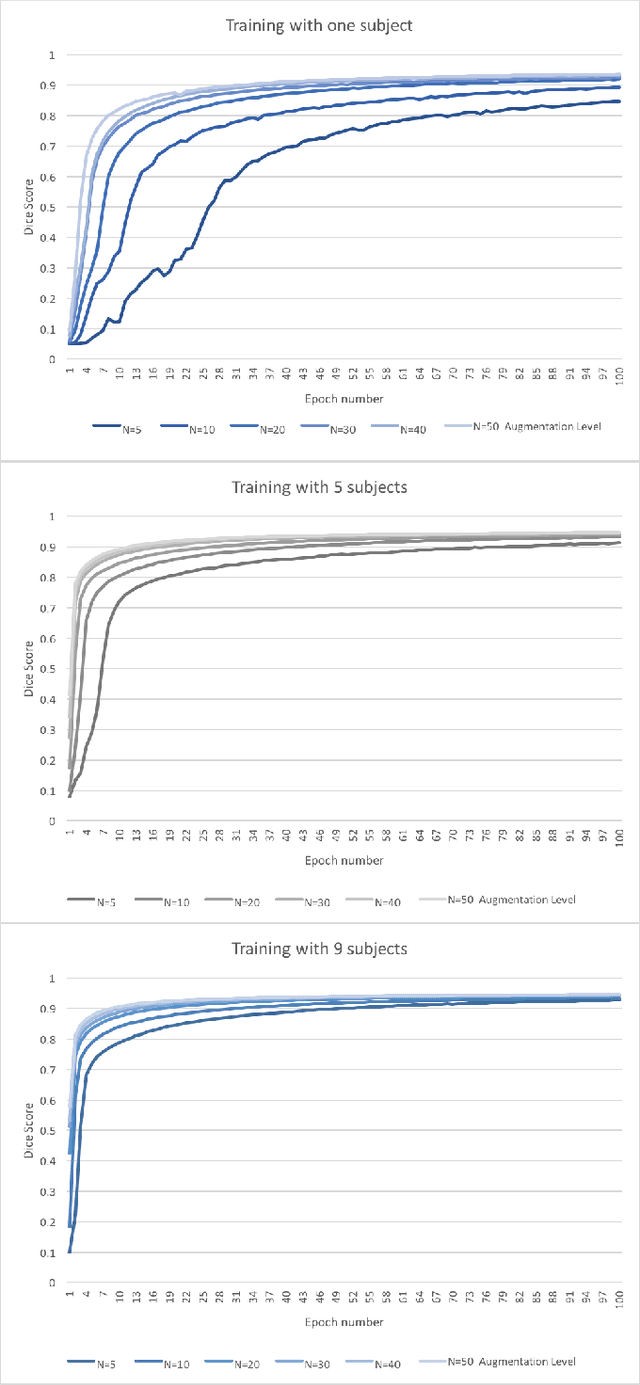
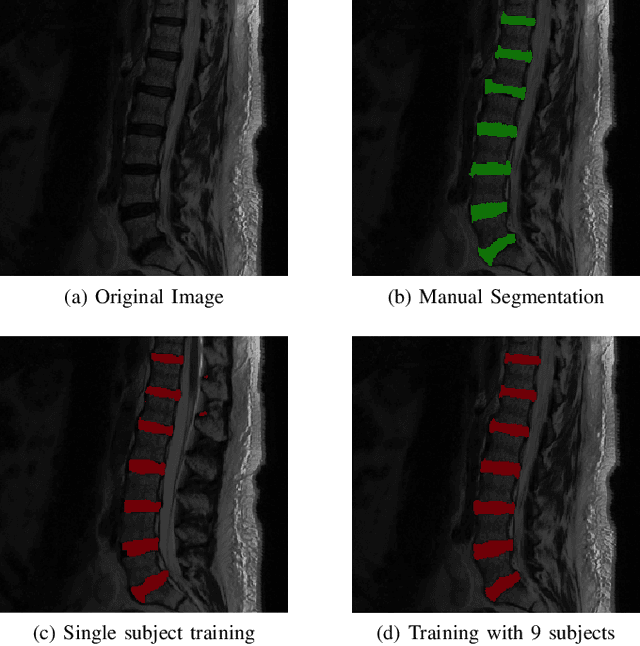
Yes, it can. Data augmentation is perhaps the oldest preprocessing step in computer vision literature. Almost every computer vision model trained on imaging data uses some form of augmentation. In this paper, we use the inter-vertebral disk segmentation task alongside a deep residual U-Net as the learning model, to explore the effectiveness of augmentation. In the extreme, we observed that a model trained on patches extracted from just one scan, with each patch augmented 50 times; achieved a Dice score of 0.73 in a validation set of 40 cases. Qualitative evaluation indicated a clinically usable segmentation algorithm, which appropriately segments regions of interest, alongside limited false positive specks. When the initial patches are extracted from nine scans the average Dice coefficient jumps to 0.86 and most of the false positives disappear. While this still falls short of state-of-the-art deep learning based segmentation of discs reported in literature, qualitative examination reveals that it does yield segmentation, which can be amended by expert clinicians with minimal effort to generate additional data for training improved deep models. Extreme augmentation of training data, should thus be construed as a strategy for training deep learning based algorithms, when very little manually annotated data is available to work with. Models trained with extreme augmentation can then be used to accelerate the generation of manually labelled data. Hence, we show that extreme augmentation can be a valuable tool in addressing scaling up small imaging data sets to address medical image segmentation tasks.
Low-Shot Learning with Imprinted Weights
Apr 06, 2018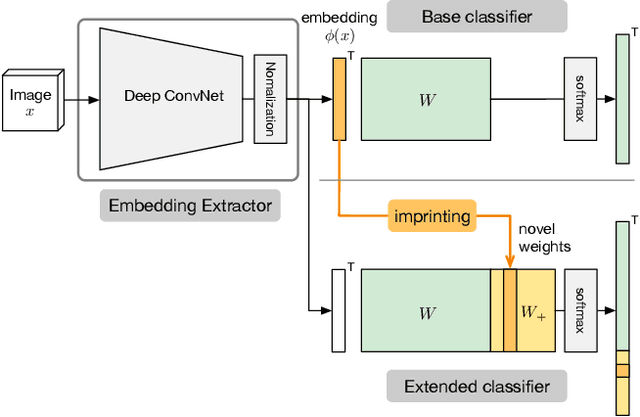
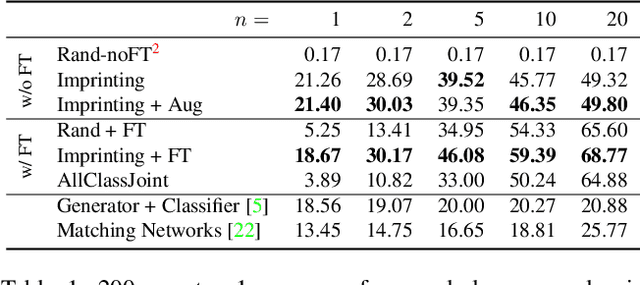
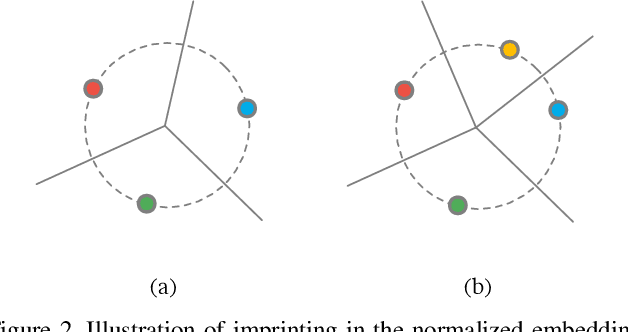
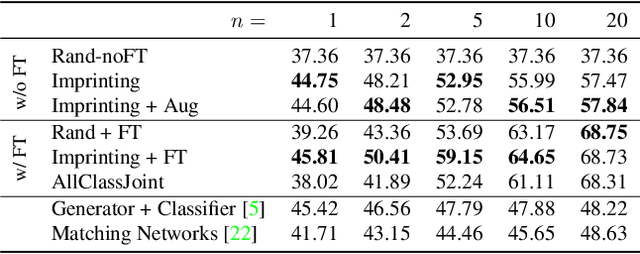
Human vision is able to immediately recognize novel visual categories after seeing just one or a few training examples. We describe how to add a similar capability to ConvNet classifiers by directly setting the final layer weights from novel training examples during low-shot learning. We call this process weight imprinting as it directly sets weights for a new category based on an appropriately scaled copy of the embedding layer activations for that training example. The imprinting process provides a valuable complement to training with stochastic gradient descent, as it provides immediate good classification performance and an initialization for any further fine-tuning in the future. We show how this imprinting process is related to proxy-based embeddings. However, it differs in that only a single imprinted weight vector is learned for each novel category, rather than relying on a nearest-neighbor distance to training instances as typically used with embedding methods. Our experiments show that using averaging of imprinted weights provides better generalization than using nearest-neighbor instance embeddings.
Frame-Recurrent Video Super-Resolution
Mar 25, 2018
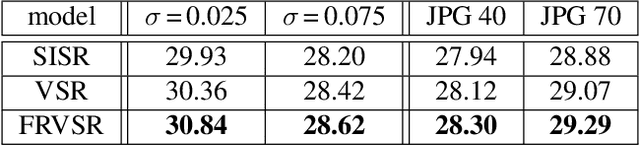
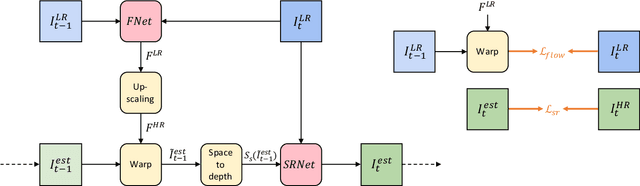

Recent advances in video super-resolution have shown that convolutional neural networks combined with motion compensation are able to merge information from multiple low-resolution (LR) frames to generate high-quality images. Current state-of-the-art methods process a batch of LR frames to generate a single high-resolution (HR) frame and run this scheme in a sliding window fashion over the entire video, effectively treating the problem as a large number of separate multi-frame super-resolution tasks. This approach has two main weaknesses: 1) Each input frame is processed and warped multiple times, increasing the computational cost, and 2) each output frame is estimated independently conditioned on the input frames, limiting the system's ability to produce temporally consistent results. In this work, we propose an end-to-end trainable frame-recurrent video super-resolution framework that uses the previously inferred HR estimate to super-resolve the subsequent frame. This naturally encourages temporally consistent results and reduces the computational cost by warping only one image in each step. Furthermore, due to its recurrent nature, the proposed method has the ability to assimilate a large number of previous frames without increased computational demands. Extensive evaluations and comparisons with previous methods validate the strengths of our approach and demonstrate that the proposed framework is able to significantly outperform the current state of the art.
Learning to Segment via Cut-and-Paste
Mar 16, 2018
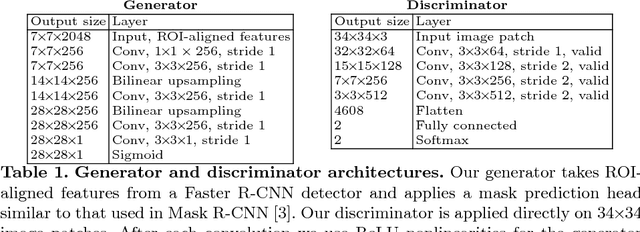
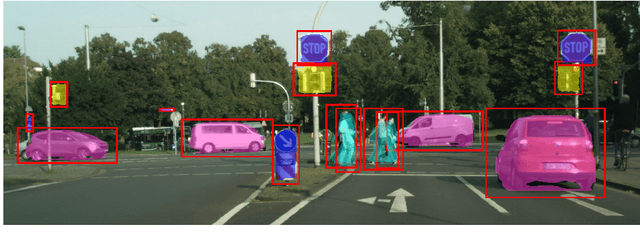
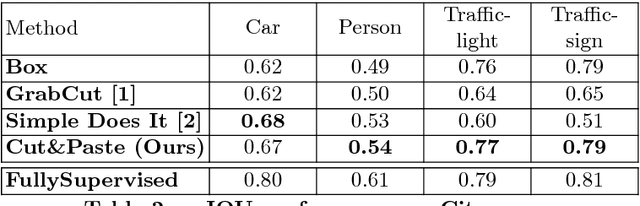
This paper presents a weakly-supervised approach to object instance segmentation. Starting with known or predicted object bounding boxes, we learn object masks by playing a game of cut-and-paste in an adversarial learning setup. A mask generator takes a detection box and Faster R-CNN features, and constructs a segmentation mask that is used to cut-and-paste the object into a new image location. The discriminator tries to distinguish between real objects, and those cut and pasted via the generator, giving a learning signal that leads to improved object masks. We verify our method experimentally using Cityscapes, COCO, and aerial image datasets, learning to segment objects without ever having seen a mask in training. Our method exceeds the performance of existing weakly supervised methods, without requiring hand-tuned segment proposals, and reaches 90% of supervised performance.
Deep Reinforcement Learning for Dexterous Manipulation with Concept Networks
Sep 20, 2017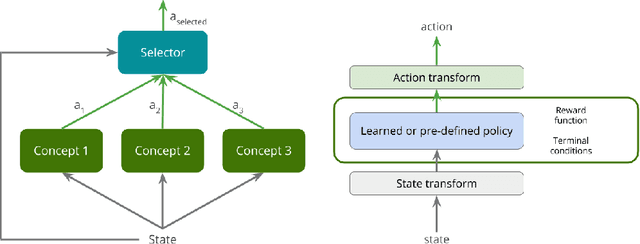
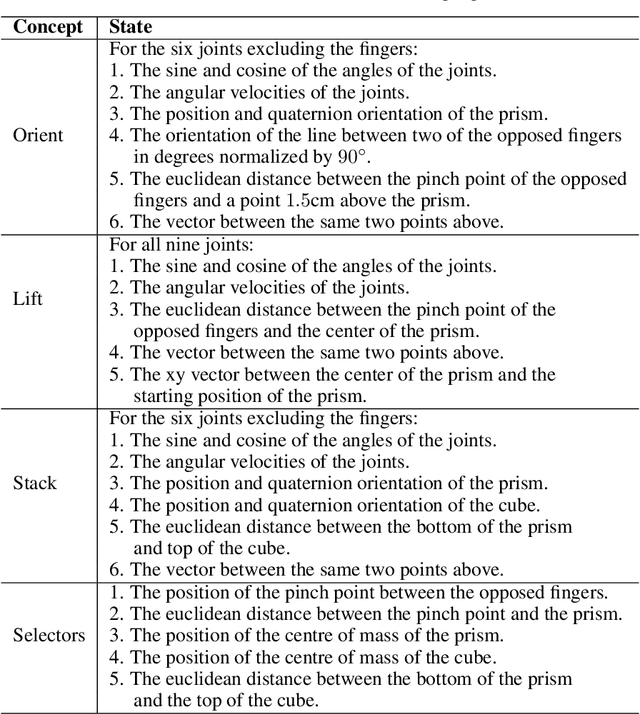
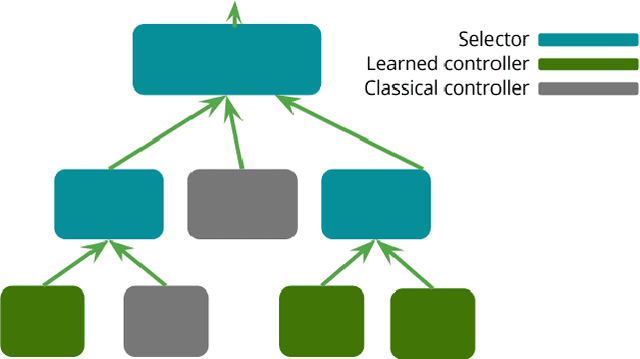

Deep reinforcement learning yields great results for a large array of problems, but models are generally retrained anew for each new problem to be solved. Prior learning and knowledge are difficult to incorporate when training new models, requiring increasingly longer training as problems become more complex. This is especially problematic for problems with sparse rewards. We provide a solution to these problems by introducing Concept Network Reinforcement Learning (CNRL), a framework which allows us to decompose problems using a multi-level hierarchy. Concepts in a concept network are reusable, and flexible enough to encapsulate feature extractors, skills, or other concept networks. With this hierarchical learning approach, deep reinforcement learning can be used to solve complex tasks in a modular way, through problem decomposition. We demonstrate the strength of CNRL by training a model to grasp a rectangular prism and precisely stack it on top of a cube using a gripper on a Kinova JACO arm, simulated in MuJoCo. Our experiments show that our use of hierarchy results in a 45x reduction in environment interactions compared to the state-of-the-art on this task.
Unsupervised Learning of Depth and Ego-Motion from Video
Aug 01, 2017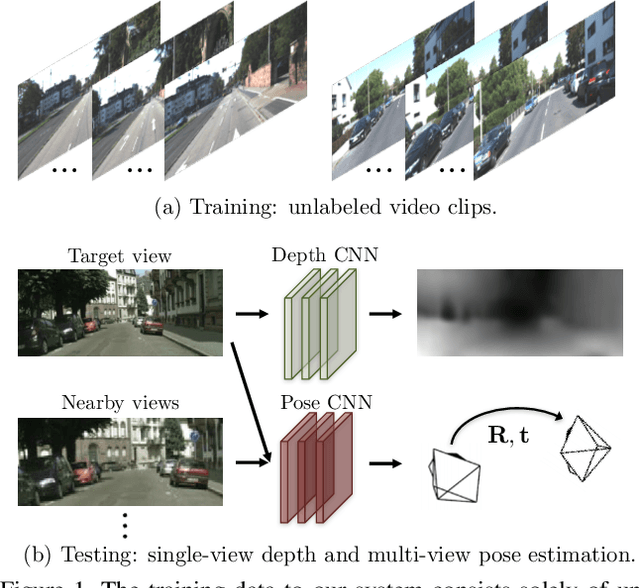
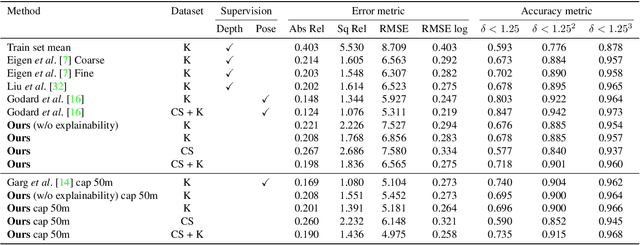
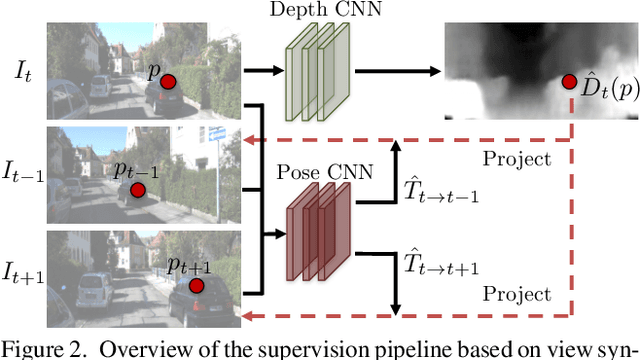
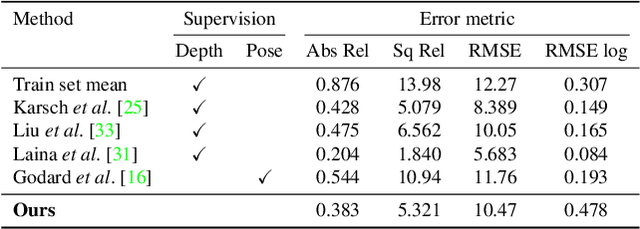
We present an unsupervised learning framework for the task of monocular depth and camera motion estimation from unstructured video sequences. We achieve this by simultaneously training depth and camera pose estimation networks using the task of view synthesis as the supervisory signal. The networks are thus coupled via the view synthesis objective during training, but can be applied independently at test time. Empirical evaluation on the KITTI dataset demonstrates the effectiveness of our approach: 1) monocular depth performing comparably with supervised methods that use either ground-truth pose or depth for training, and 2) pose estimation performing favorably with established SLAM systems under comparable input settings.