 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo GPTs Produce Less Literal Translations?
Jun 06, 2023



Large Language Models (LLMs) such as GPT-3 have emerged as general-purpose language models capable of addressing many natural language generation or understanding tasks. On the task of Machine Translation (MT), multiple works have investigated few-shot prompting mechanisms to elicit better translations from LLMs. However, there has been relatively little investigation on how such translations differ qualitatively from the translations generated by standard Neural Machine Translation (NMT) models. In this work, we investigate these differences in terms of the literalness of translations produced by the two systems. Using literalness measures involving word alignment and monotonicity, we find that translations out of English (E-X) from GPTs tend to be less literal, while exhibiting similar or better scores on MT quality metrics. We demonstrate that this finding is borne out in human evaluations as well. We then show that these differences are especially pronounced when translating sentences that contain idiomatic expressions.
Pixel Representations for Multilingual Translation and Data-efficient Cross-lingual Transfer
May 23, 2023We introduce and demonstrate how to effectively train multilingual machine translation models with pixel representations. We experiment with two different data settings with a variety of language and script coverage, and show performance competitive with subword embeddings. We analyze various properties of pixel representations to better understand where they provide potential benefits and the impact of different scripts and data representations. We observe that these properties not only enable seamless cross-lingual transfer to unseen scripts, but make pixel representations more data-efficient than alternatives such as vocabulary expansion. We hope this work contributes to more extensible multilingual models for all languages and scripts.
Escaping the sentence-level paradigm in machine translation
Apr 25, 2023It is well-known that document context is vital for resolving a range of translation ambiguities, and in fact the document setting is the most natural setting for nearly all translation. It is therefore unfortunate that machine translation -- both research and production -- largely remains stuck in a decades-old sentence-level translation paradigm. It is also an increasingly glaring problem in light of competitive pressure from large language models, which are natively document-based. Much work in document-context machine translation exists, but for various reasons has been unable to catch hold. This paper suggests a path out of this rut by addressing three impediments at once: what architectures should we use? where do we get document-level information for training them? and how do we know whether they are any good? In contrast to work on specialized architectures, we show that the standard Transformer architecture is sufficient, provided it has enough capacity. Next, we address the training data issue by taking document samples from back-translated data only, where the data is not only more readily available, but is also of higher quality compared to parallel document data, which may contain machine translation output. Finally, we propose generative variants of existing contrastive metrics that are better able to discriminate among document systems. Results in four large-data language pairs (DE$\rightarrow$EN, EN$\rightarrow$DE, EN$\rightarrow$FR, and EN$\rightarrow$RU) establish the success of these three pieces together in improving document-level performance.
Operationalizing Specifications, In Addition to Test Sets for Evaluating Constrained Generative Models
Nov 19, 2022

In this work, we present some recommendations on the evaluation of state-of-the-art generative models for constrained generation tasks. The progress on generative models has been rapid in recent years. These large-scale models have had three impacts: firstly, the fluency of generation in both language and vision modalities has rendered common average-case evaluation metrics much less useful in diagnosing system errors. Secondly, the same substrate models now form the basis of a number of applications, driven both by the utility of their representations as well as phenomena such as in-context learning, which raise the abstraction level of interacting with such models. Thirdly, the user expectations around these models and their feted public releases have made the technical challenge of out of domain generalization much less excusable in practice. Subsequently, our evaluation methodologies haven't adapted to these changes. More concretely, while the associated utility and methods of interacting with generative models have expanded, a similar expansion has not been observed in their evaluation practices. In this paper, we argue that the scale of generative models could be exploited to raise the abstraction level at which evaluation itself is conducted and provide recommendations for the same. Our recommendations are based on leveraging specifications as a powerful instrument to evaluate generation quality and are readily applicable to a variety of tasks.
Additive Interventions Yield Robust Multi-Domain Machine Translation Models
Oct 23, 2022
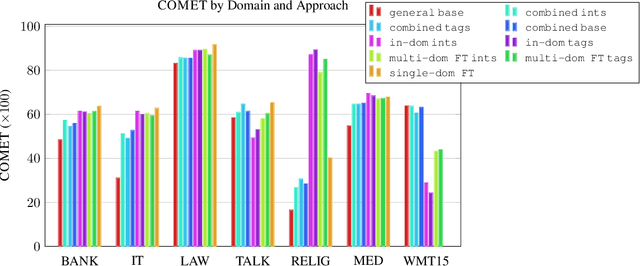
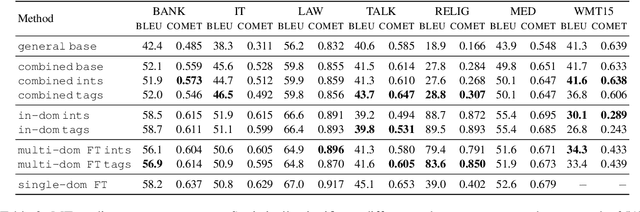
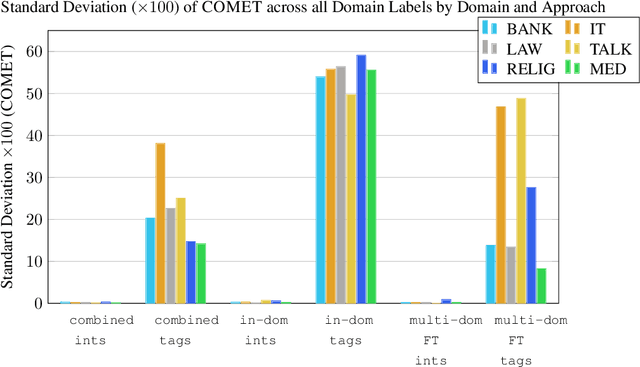
Additive interventions are a recently-proposed mechanism for controlling target-side attributes in neural machine translation. In contrast to tag-based approaches which manipulate the raw source sequence, interventions work by directly modulating the encoder representation of all tokens in the sequence. We examine the role of additive interventions in a large-scale multi-domain machine translation setting and compare its performance in various inference scenarios. We find that while the performance difference is small between intervention-based systems and tag-based systems when the domain label matches the test domain, intervention-based systems are robust to label error, making them an attractive choice under label uncertainty. Further, we find that the superiority of single-domain fine-tuning comes under question when training data size is scaled, contradicting previous findings.
SALTED: A Framework for SAlient Long-Tail Translation Error Detection
May 20, 2022



Traditional machine translation (MT) metrics provide an average measure of translation quality that is insensitive to the long tail of behavioral problems in MT. Examples include translation of numbers, physical units, dropped content and hallucinations. These errors, which occur rarely and unpredictably in Neural Machine Translation (NMT), greatly undermine the reliability of state-of-the-art MT systems. Consequently, it is important to have visibility into these problems during model development. Towards this direction, we introduce SALTED, a specifications-based framework for behavioral testing of MT models that provides fine-grained views of salient long-tail errors, permitting trustworthy visibility into previously invisible problems. At the core of our approach is the development of high-precision detectors that flag errors (or alternatively, verify output correctness) between a source sentence and a system output. We demonstrate that such detectors could be used not just to identify salient long-tail errors in MT systems, but also for higher-recall filtering of the training data, fixing targeted errors with model fine-tuning in NMT and generating novel data for metamorphic testing to elicit further bugs in models.
Large-Scale Streaming End-to-End Speech Translation with Neural Transducers
Apr 11, 2022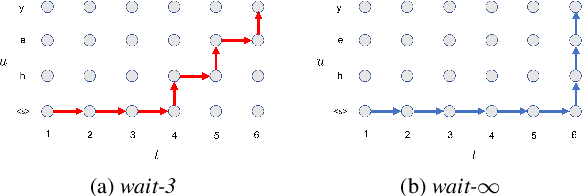
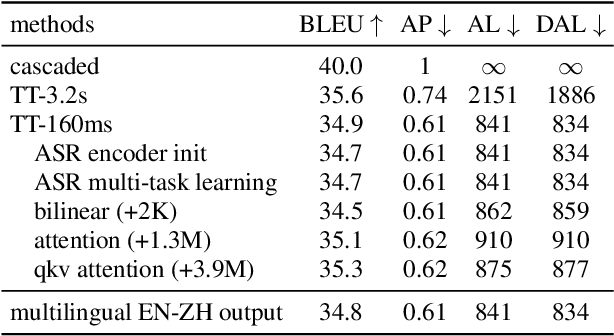
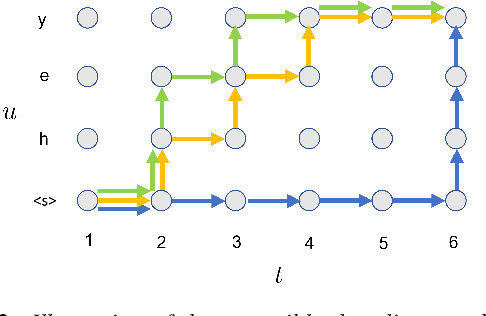
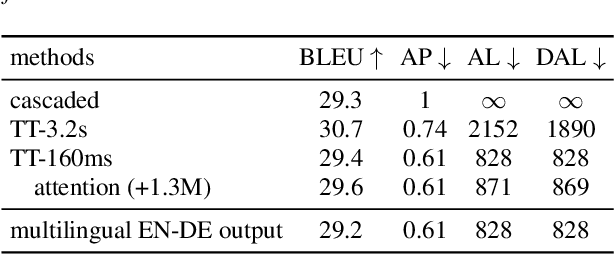
Neural transducers have been widely used in automatic speech recognition (ASR). In this paper, we introduce it to streaming end-to-end speech translation (ST), which aims to convert audio signals to texts in other languages directly. Compared with cascaded ST that performs ASR followed by text-based machine translation (MT), the proposed Transformer transducer (TT)-based ST model drastically reduces inference latency, exploits speech information, and avoids error propagation from ASR to MT. To improve the modeling capacity, we propose attention pooling for the joint network in TT. In addition, we extend TT-based ST to multilingual ST, which generates texts of multiple languages at the same time. Experimental results on a large-scale 50 thousand (K) hours pseudo-labeled training set show that TT-based ST not only significantly reduces inference time but also outperforms non-streaming cascaded ST for English-German translation.
The JHU-Microsoft Submission for WMT21 Quality Estimation Shared Task
Sep 17, 2021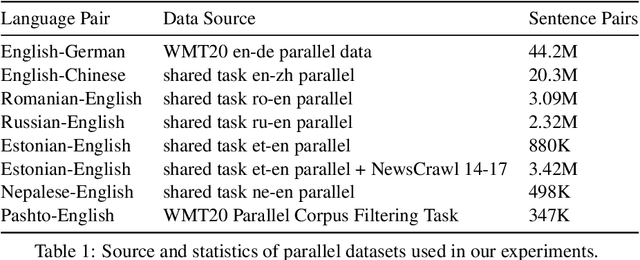
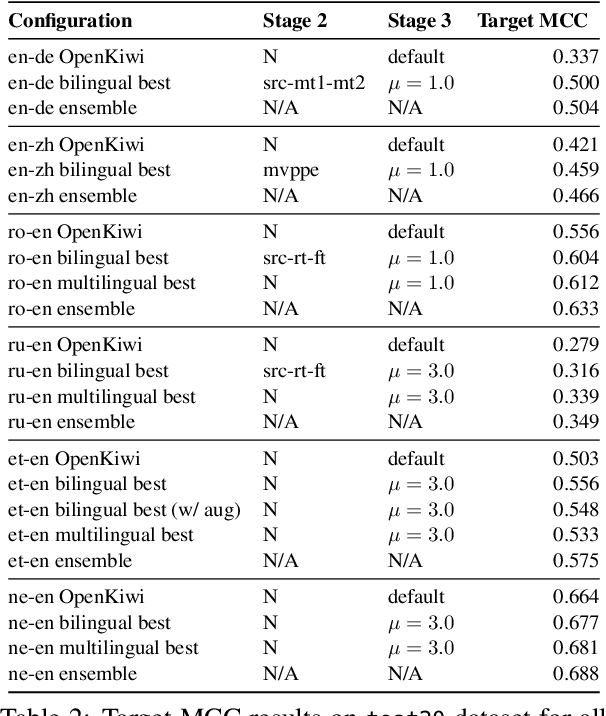
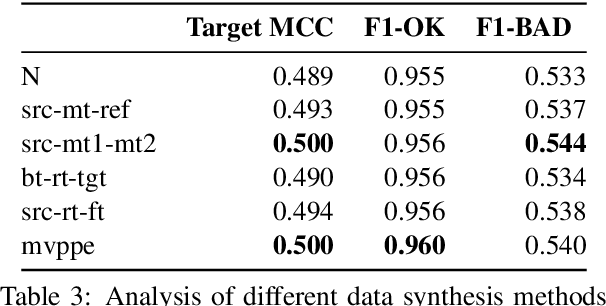
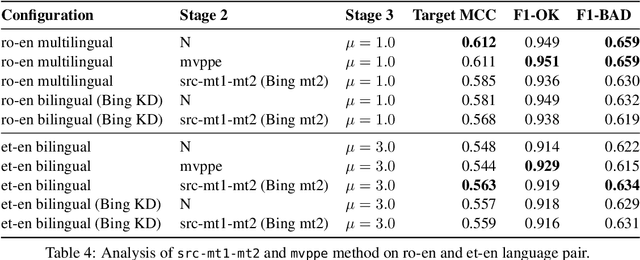
This paper presents the JHU-Microsoft joint submission for WMT 2021 quality estimation shared task. We only participate in Task 2 (post-editing effort estimation) of the shared task, focusing on the target-side word-level quality estimation. The techniques we experimented with include Levenshtein Transformer training and data augmentation with a combination of forward, backward, round-trip translation, and pseudo post-editing of the MT output. We demonstrate the competitiveness of our system compared to the widely adopted OpenKiwi-XLM baseline. Our system is also the top-ranking system on the MT MCC metric for the English-German language pair.
Levenshtein Training for Word-level Quality Estimation
Sep 15, 2021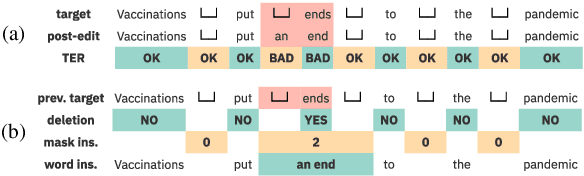
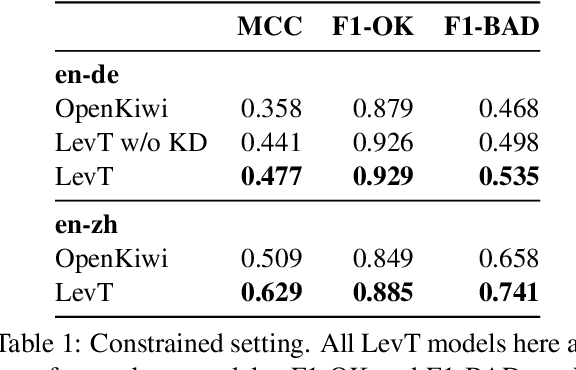
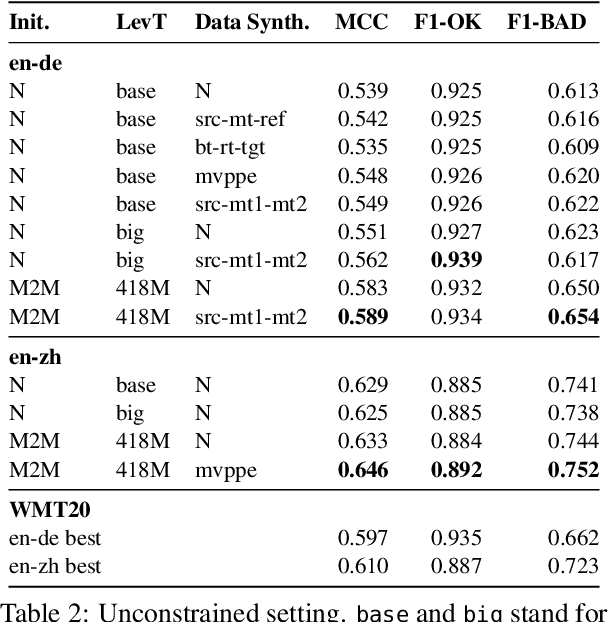
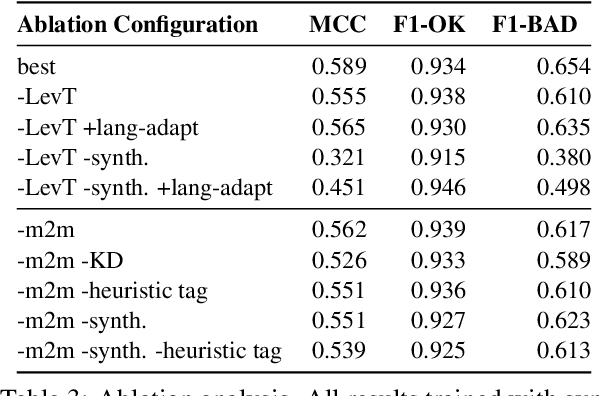
We propose a novel scheme to use the Levenshtein Transformer to perform the task of word-level quality estimation. A Levenshtein Transformer is a natural fit for this task: trained to perform decoding in an iterative manner, a Levenshtein Transformer can learn to post-edit without explicit supervision. To further minimize the mismatch between the translation task and the word-level QE task, we propose a two-stage transfer learning procedure on both augmented data and human post-editing data. We also propose heuristics to construct reference labels that are compatible with subword-level finetuning and inference. Results on WMT 2020 QE shared task dataset show that our proposed method has superior data efficiency under the data-constrained setting and competitive performance under the unconstrained setting.
Robust Open-Vocabulary Translation from Visual Text Representations
Apr 16, 2021
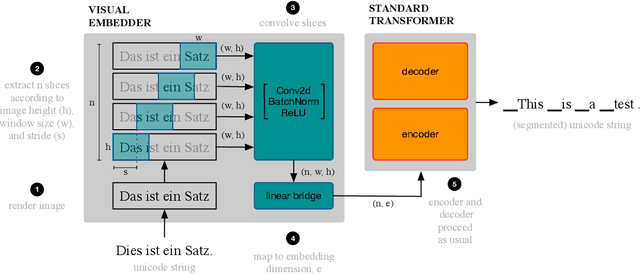
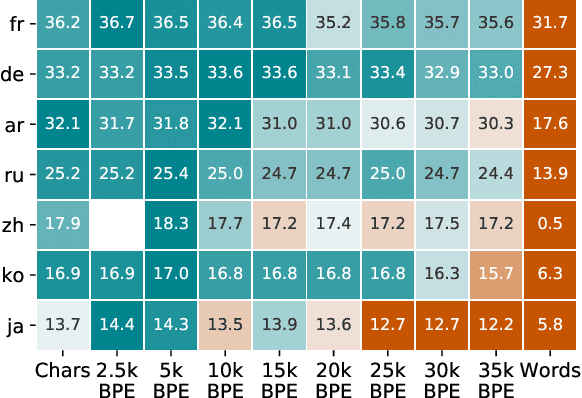
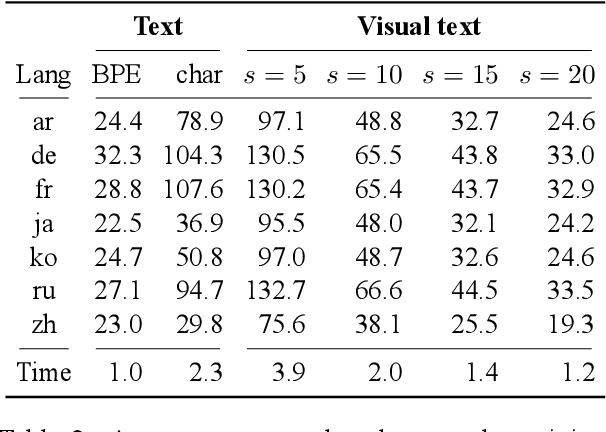
Machine translation models have discrete vocabularies and commonly use subword segmentation techniques to achieve an 'open-vocabulary.' This approach relies on consistent and correct underlying unicode sequences, and makes models susceptible to degradation from common types of noise and variation. Motivated by the robustness of human language processing, we propose the use of visual text representations, which dispense with a finite set of text embeddings in favor of continuous vocabularies created by processing visually rendered text. We show that models using visual text representations approach or match performance of text baselines on clean TED datasets. More importantly, models with visual embeddings demonstrate significant robustness to varied types of noise, achieving e.g., 25.9 BLEU on a character permuted German--English task where subword models degrade to 1.9.