 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Modulo Theories
Jan 26, 2023



Recent techniques that integrate \emph{solver layers} into Deep Neural Networks (DNNs) have shown promise in bridging a long-standing gap between inductive learning and symbolic reasoning techniques. In this paper we present a set of techniques for integrating \emph{Satisfiability Modulo Theories} (SMT) solvers into the forward and backward passes of a deep network layer, called SMTLayer. Using this approach, one can encode rich domain knowledge into the network in the form of mathematical formulas. In the forward pass, the solver uses symbols produced by prior layers, along with these formulas, to construct inferences; in the backward pass, the solver informs updates to the network, driving it towards representations that are compatible with the solver's theory. Notably, the solver need not be differentiable. We implement \layername as a Pytorch module, and our empirical results show that it leads to models that \emph{1)} require fewer training samples than conventional models, \emph{2)} that are robust to certain types of covariate shift, and \emph{3)} that ultimately learn representations that are consistent with symbolic knowledge, and thus naturally interpretable.
Black-Box Audits for Group Distribution Shifts
Sep 08, 2022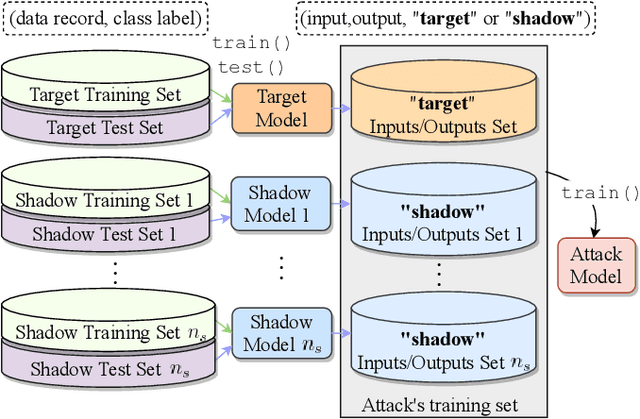
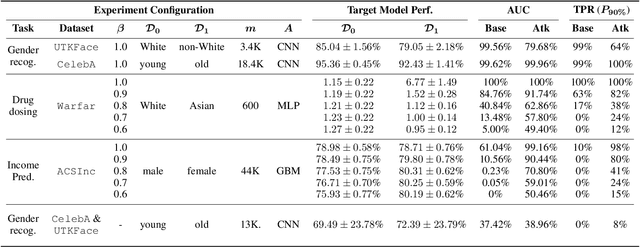
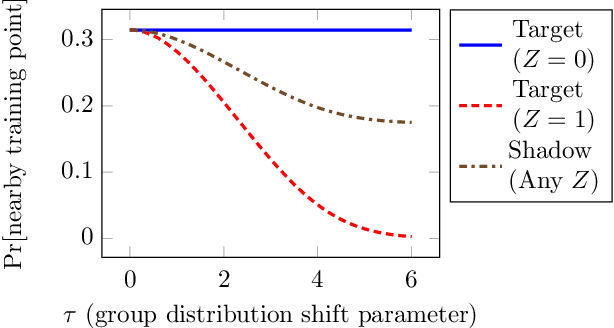
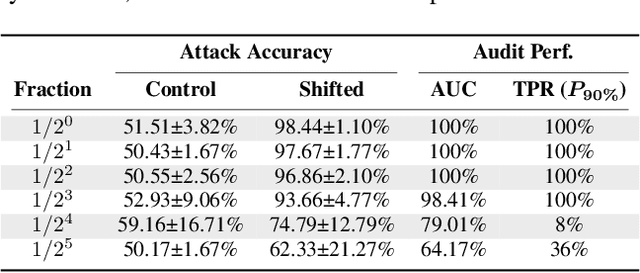
When a model informs decisions about people, distribution shifts can create undue disparities. However, it is hard for external entities to check for distribution shift, as the model and its training set are often proprietary. In this paper, we introduce and study a black-box auditing method to detect cases of distribution shift that lead to a performance disparity of the model across demographic groups. By extending techniques used in membership and property inference attacks -- which are designed to expose private information from learned models -- we demonstrate that an external auditor can gain the information needed to identify these distribution shifts solely by querying the model. Our experimental results on real-world datasets show that this approach is effective, achieving 80--100% AUC-ROC in detecting shifts involving the underrepresentation of a demographic group in the training set. Researchers and investigative journalists can use our tools to perform non-collaborative audits of proprietary models and expose cases of underrepresentation in the training datasets.
On the Perils of Cascading Robust Classifiers
Jun 01, 2022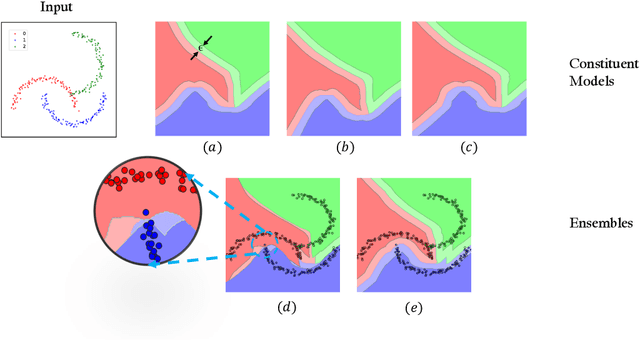
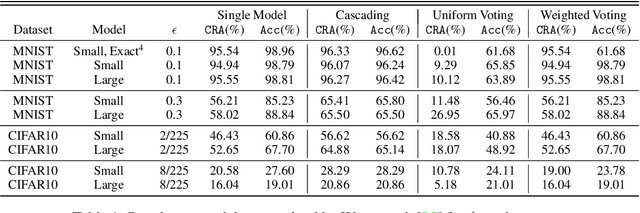
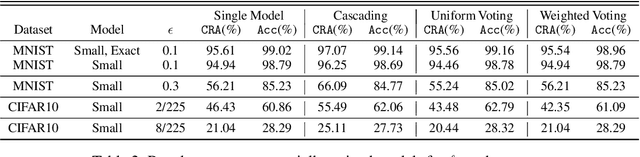
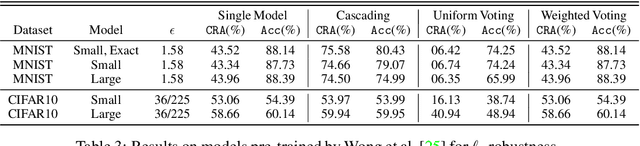
Ensembling certifiably robust neural networks has been shown to be a promising approach for improving the \emph{certified robust accuracy} of neural models. Black-box ensembles that assume only query-access to the constituent models (and their robustness certifiers) during prediction are particularly attractive due to their modular structure. Cascading ensembles are a popular instance of black-box ensembles that appear to improve certified robust accuracies in practice. However, we find that the robustness certifier used by a cascading ensemble is unsound. That is, when a cascading ensemble is certified as locally robust at an input $x$, there can, in fact, be inputs $x'$ in the $\epsilon$-ball centered at $x$, such that the cascade's prediction at $x'$ is different from $x$. We present an alternate black-box ensembling mechanism based on weighted voting which we prove to be sound for robustness certification. Via a thought experiment, we demonstrate that if the constituent classifiers are suitably diverse, voting ensembles can improve certified performance. Our code is available at \url{https://github.com/TristaChi/ensembleKW}.
Faithful Explanations for Deep Graph Models
May 24, 2022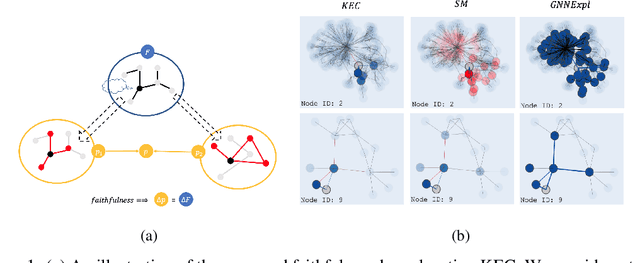
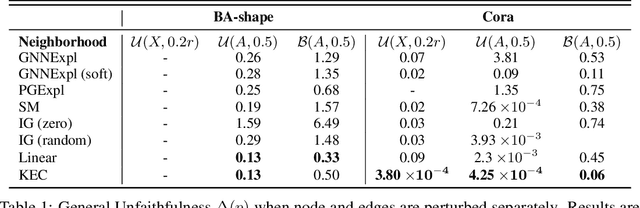


This paper studies faithful explanations for Graph Neural Networks (GNNs). First, we provide a new and general method for formally characterizing the faithfulness of explanations for GNNs. It applies to existing explanation methods, including feature attributions and subgraph explanations. Second, our analytical and empirical results demonstrate that feature attribution methods cannot capture the nonlinear effect of edge features, while existing subgraph explanation methods are not faithful. Third, we introduce \emph{k-hop Explanation with a Convolutional Core} (KEC), a new explanation method that provably maximizes faithfulness to the original GNN by leveraging information about the graph structure in its adjacency matrix and its \emph{k-th} power. Lastly, our empirical results over both synthetic and real-world datasets for classification and anomaly detection tasks with GNNs demonstrate the effectiveness of our approach.
Selective Ensembles for Consistent Predictions
Nov 16, 2021



Recent work has shown that models trained to the same objective, and which achieve similar measures of accuracy on consistent test data, may nonetheless behave very differently on individual predictions. This inconsistency is undesirable in high-stakes contexts, such as medical diagnosis and finance. We show that this inconsistent behavior extends beyond predictions to feature attributions, which may likewise have negative implications for the intelligibility of a model, and one's ability to find recourse for subjects. We then introduce selective ensembles to mitigate such inconsistencies by applying hypothesis testing to the predictions of a set of models trained using randomly-selected starting conditions; importantly, selective ensembles can abstain in cases where a consistent outcome cannot be achieved up to a specified confidence level. We prove that that prediction disagreement between selective ensembles is bounded, and empirically demonstrate that selective ensembles achieve consistent predictions and feature attributions while maintaining low abstention rates. On several benchmark datasets, selective ensembles reach zero inconsistently predicted points, with abstention rates as low 1.5%.
Consistent Counterfactuals for Deep Models
Oct 06, 2021
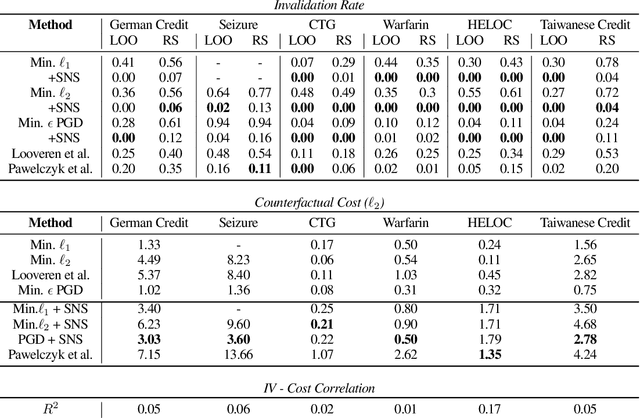
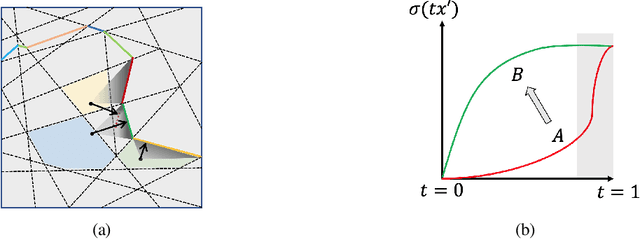
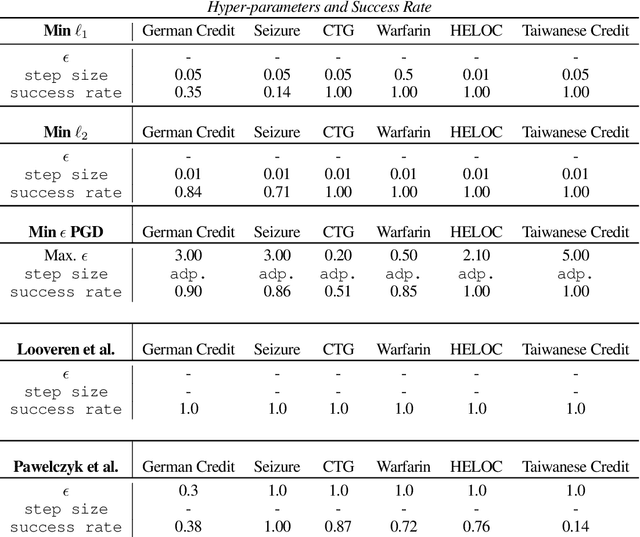
Counterfactual examples are one of the most commonly-cited methods for explaining the predictions of machine learning models in key areas such as finance and medical diagnosis. Counterfactuals are often discussed under the assumption that the model on which they will be used is static, but in deployment models may be periodically retrained or fine-tuned. This paper studies the consistency of model prediction on counterfactual examples in deep networks under small changes to initial training conditions, such as weight initialization and leave-one-out variations in data, as often occurs during model deployment. We demonstrate experimentally that counterfactual examples for deep models are often inconsistent across such small changes, and that increasing the cost of the counterfactual, a stability-enhancing mitigation suggested by prior work in the context of simpler models, is not a reliable heuristic in deep networks. Rather, our analysis shows that a model's local Lipschitz continuity around the counterfactual is key to its consistency across related models. To this end, we propose Stable Neighbor Search as a way to generate more consistent counterfactual explanations, and illustrate the effectiveness of this approach on several benchmark datasets.
Self-Repairing Neural Networks: Provable Safety for Deep Networks via Dynamic Repair
Jul 23, 2021

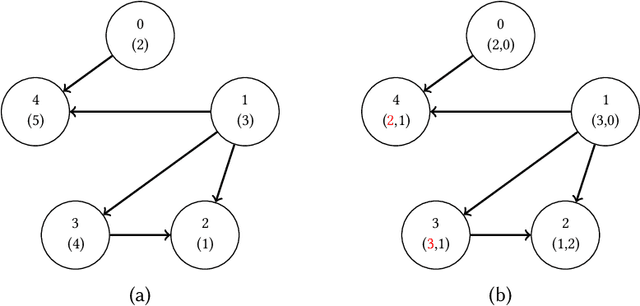

Neural networks are increasingly being deployed in contexts where safety is a critical concern. In this work, we propose a way to construct neural network classifiers that dynamically repair violations of non-relational safety constraints called safe ordering properties. Safe ordering properties relate requirements on the ordering of a network's output indices to conditions on their input, and are sufficient to express most useful notions of non-relational safety for classifiers. Our approach is based on a novel self-repairing layer, which provably yields safe outputs regardless of the characteristics of its input. We compose this layer with an existing network to construct a self-repairing network (SR-Net), and show that in addition to providing safe outputs, the SR-Net is guaranteed to preserve the accuracy of the original network. Notably, our approach is independent of the size and architecture of the network being repaired, depending only on the specified property and the dimension of the network's output; thus it is scalable to large state-of-the-art networks. We show that our approach can be implemented using vectorized computations that execute efficiently on a GPU, introducing run-time overhead of less than one millisecond on current hardware -- even on large, widely-used networks containing hundreds of thousands of neurons and millions of parameters.
Leave-one-out Unfairness
Jul 21, 2021


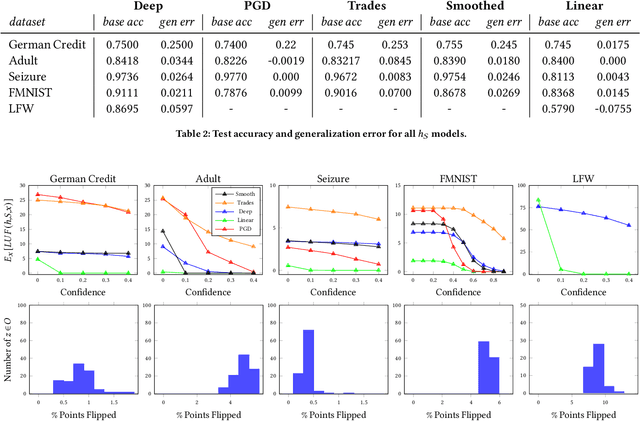
We introduce leave-one-out unfairness, which characterizes how likely a model's prediction for an individual will change due to the inclusion or removal of a single other person in the model's training data. Leave-one-out unfairness appeals to the idea that fair decisions are not arbitrary: they should not be based on the chance event of any one person's inclusion in the training data. Leave-one-out unfairness is closely related to algorithmic stability, but it focuses on the consistency of an individual point's prediction outcome over unit changes to the training data, rather than the error of the model in aggregate. Beyond formalizing leave-one-out unfairness, we characterize the extent to which deep models behave leave-one-out unfairly on real data, including in cases where the generalization error is small. Further, we demonstrate that adversarial training and randomized smoothing techniques have opposite effects on leave-one-out fairness, which sheds light on the relationships between robustness, memorization, individual fairness, and leave-one-out fairness in deep models. Finally, we discuss salient practical applications that may be negatively affected by leave-one-out unfairness.
* FAccT '21
Relaxing Local Robustness
Jun 11, 2021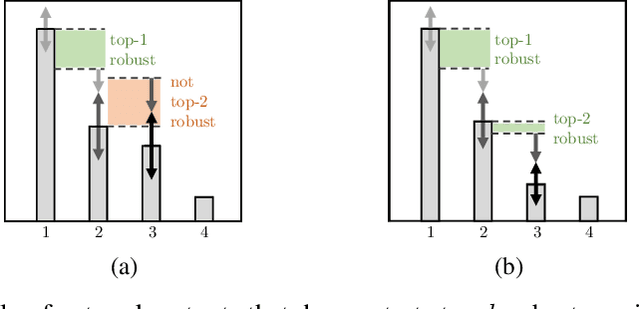
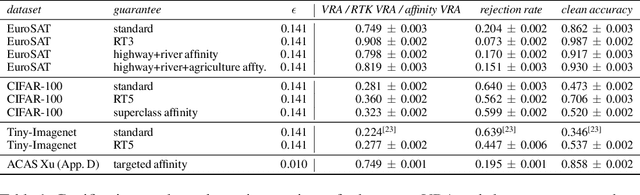


Certifiable local robustness, which rigorously precludes small-norm adversarial examples, has received significant attention as a means of addressing security concerns in deep learning. However, for some classification problems, local robustness is not a natural objective, even in the presence of adversaries; for example, if an image contains two classes of subjects, the correct label for the image may be considered arbitrary between the two, and thus enforcing strict separation between them is unnecessary. In this work, we introduce two relaxed safety properties for classifiers that address this observation: (1) relaxed top-k robustness, which serves as the analogue of top-k accuracy; and (2) affinity robustness, which specifies which sets of labels must be separated by a robustness margin, and which can be $\epsilon$-close in $\ell_p$ space. We show how to construct models that can be efficiently certified against each relaxed robustness property, and trained with very little overhead relative to standard gradient descent. Finally, we demonstrate experimentally that these relaxed variants of robustness are well-suited to several significant classification problems, leading to lower rejection rates and higher certified accuracies than can be obtained when certifying "standard" local robustness.
Boundary Attributions Provide Normal (Vector) Explanations
Mar 23, 2021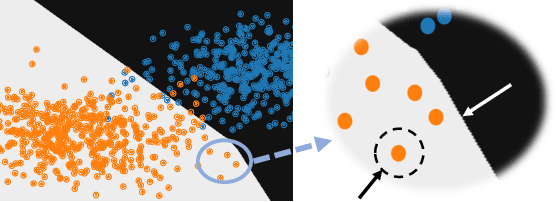
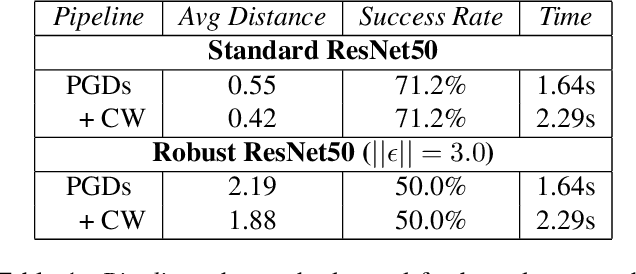

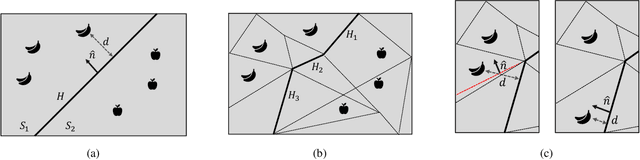
Recent work on explaining Deep Neural Networks (DNNs) focuses on attributing the model's output scores to input features. However, when it comes to classification problems, a more fundamental question is how much does each feature contributes to the model's decision to classify an input instance into a specific class. Our first contribution is Boundary Attribution, a new explanation method to address this question. BA leverages an understanding of the geometry of activation regions. Specifically, they involve computing (and aggregating) normal vectors of the local decision boundaries for the target input. Our second contribution is a set of analytical results connecting the adversarial robustness of the network and the quality of gradient-based explanations. Specifically, we prove two theorems for ReLU networks: BA of randomized smoothed networks or robustly trained networks is much closer to non-boundary attribution methods than that in standard networks. These analytics encourage users to improve model robustness for high-quality explanations. Finally, we evaluate the proposed methods on ImageNet and show BAs produce more concentrated and sharper visualizations compared with non-boundary ones. We further demonstrate that our method also helps to reduce the sensitivity of attributions to the baseline input if one is required.