 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closed-Form Solution to Local Non-Rigid Structure-from-Motion
Nov 23, 2020

A recent trend in Non-Rigid Structure-from-Motion (NRSfM) is to express local, differential constraints between pairs of images, from which the surface normal at any point can be obtained by solving a system of polynomial equations. The systems of equations derived in previous work, however, are of high degree, having up to five real solutions, thus requiring a computationally expensive strategy to select a unique solution. Furthermore, they suffer from degeneracies that make the resulting estimates unreliable, without any mechanism to identify this situation. In this paper, we show that, under widely applicable assumptions, we can derive a new system of equation in terms of the surface normals whose two solutions can be obtained in closed-form and can easily be disambiguated locally. Our formalism further allows us to assess how reliable the estimated local normals are and, hence, to discard them if they are not. Our experiments show that our reconstructions, obtained from two or more views, are significantly more accurate than those of state-of-the-art methods, while also being faster.
3D Registration for Self-Occluded Objects in Context
Nov 23, 2020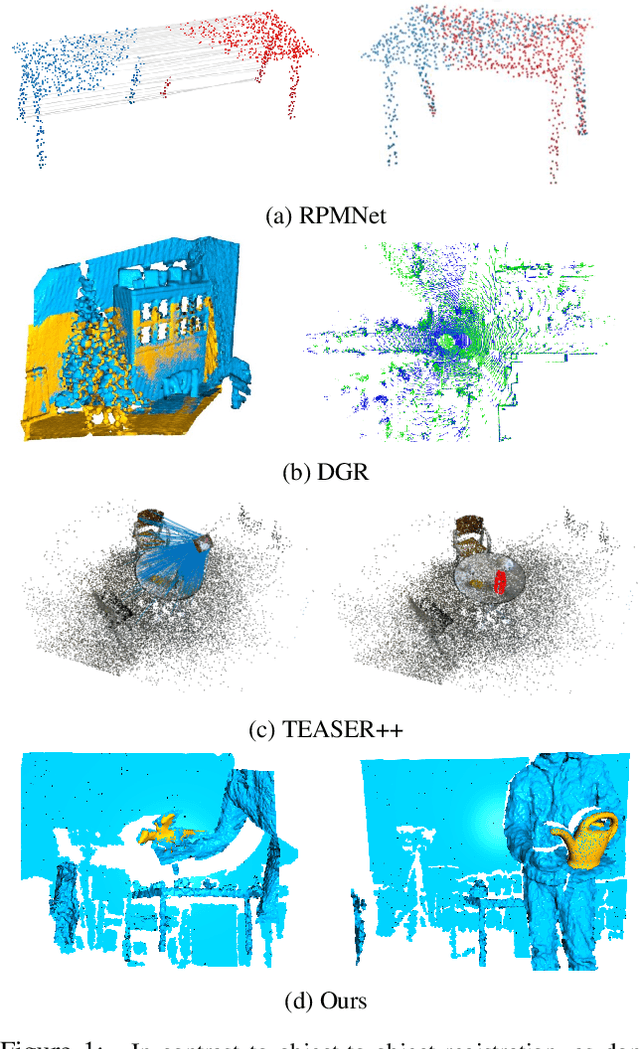
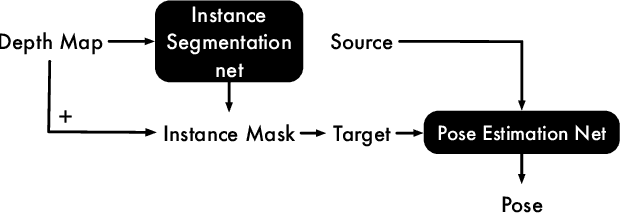
While much progress has been made on the task of 3D point cloud registration, there still exists no learning-based method able to estimate the 6D pose of an object observed by a 2.5D sensor in a scene. The challenges of this scenario include the fact that most measurements are outliers depicting the object's surrounding context, and the mismatch between the complete 3D object model and its self-occluded observations. We introduce the first deep learning framework capable of effectively handling this scenario. Our method consists of an instance segmentation module followed by a pose estimation one. It allows us to perform 3D registration in a one-shot manner, without requiring an expensive iterative procedure. We further develop an on-the-fly rendering-based training strategy that is both time- and memory-efficient. Our experiments evidence the superiority of our approach over the state-of-the-art traditional and learning-based 3D registration methods.
Self-supervised Segmentation via Background Inpainting
Nov 11, 2020
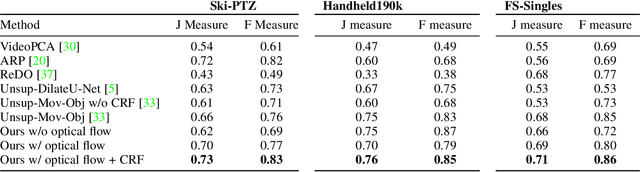
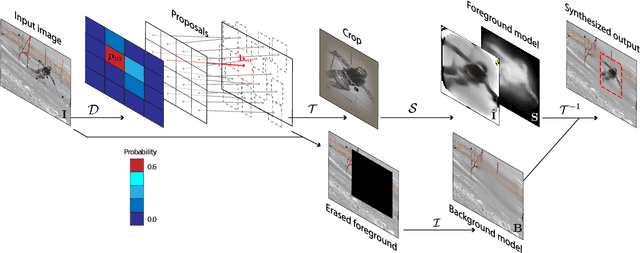

While supervised object detection and segmentation methods achieve impressive accuracy, they generalize poorly to images whose appearance significantly differs from the data they have been trained on. To address this when annotating data is prohibitively expensive, we introduce a self-supervised detection and segmentation approach that can work with single images captured by a potentially moving camera. At the heart of our approach lies the observation that object segmentation and background reconstruction are linked tasks, and that, for structured scenes, background regions can be re-synthesized from their surroundings, whereas regions depicting the moving object cannot. We encode this intuition into a self-supervised loss function that we exploit to train a proposal-based segmentation network. To account for the discrete nature of the proposals, we develop a Monte Carlo-based training strategy that allows the algorithm to explore the large space of object proposals. We apply our method to human detection and segmentation in images that visually depart from those of standard benchmarks and outperform existing self-supervised methods.
Better Patch Stitching for Parametric Surface Reconstruction
Oct 14, 2020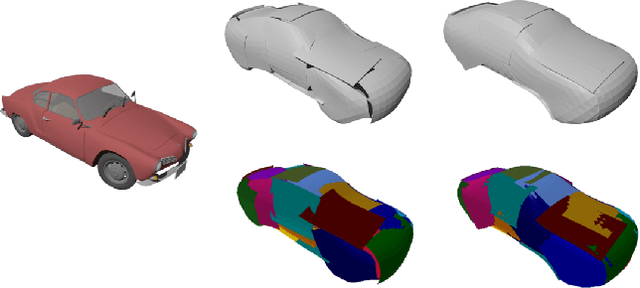
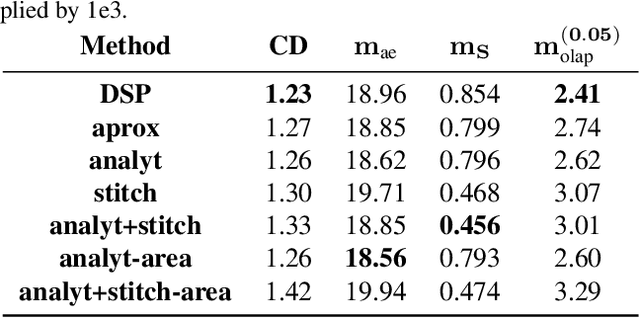
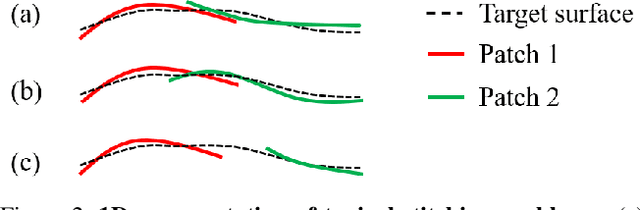
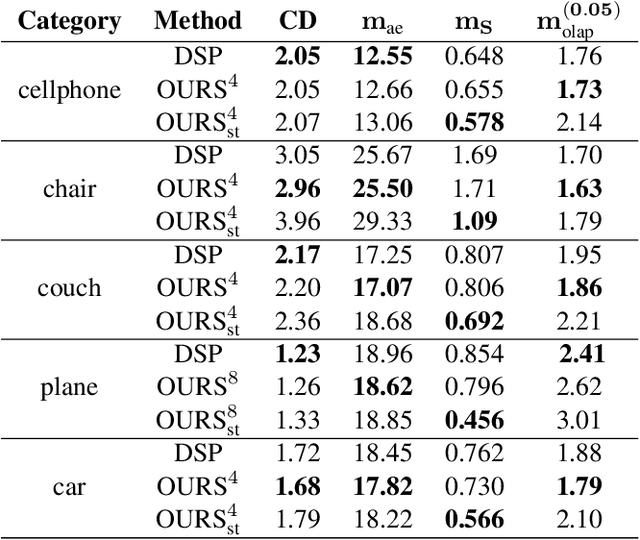
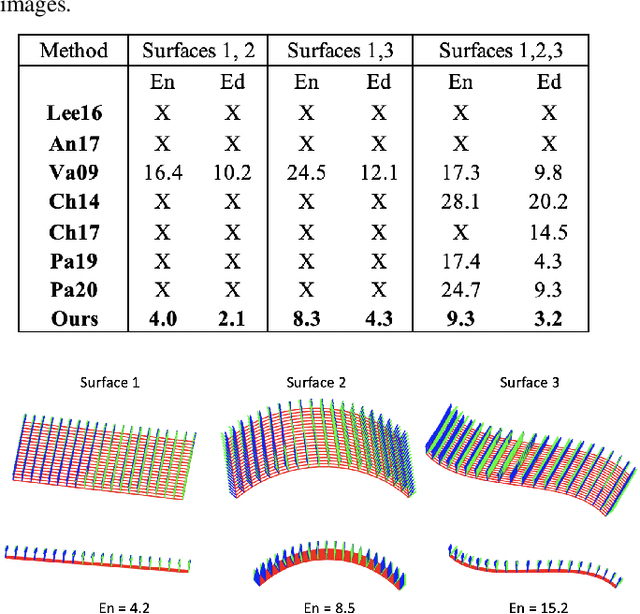
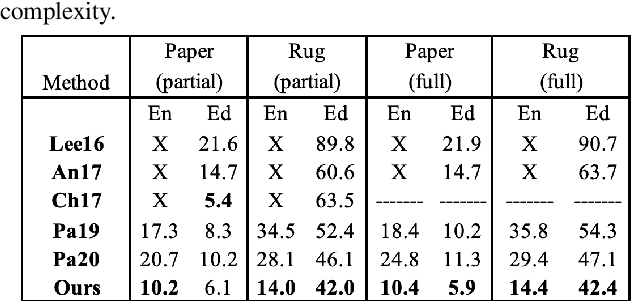
Recently, parametric mappings have emerged as highly effective surface representations, yielding low reconstruction error. In particular, the latest works represent the target shape as an atlas of multiple mappings, which can closely encode object parts. Atlas representations, however, suffer from one major drawback: The individual mappings are not guaranteed to be consistent, which results in holes in the reconstructed shape or in jagged surface areas. We introduce an approach that explicitly encourages global consistency of the local mappings. To this end, we introduce two novel loss terms. The first term exploits the surface normals and requires that they remain locally consistent when estimated within and across the individual mappings. The second term further encourages better spatial configuration of the mappings by minimizing novel stitching error. We show on standard benchmarks that the use of normal consistency requirement outperforms the baselines quantitatively while enforcing better stitching leads to much better visual quality of the reconstructed objects as compared to the state-of-the-art.
Motion Prediction Using Temporal Inception Module
Oct 06, 2020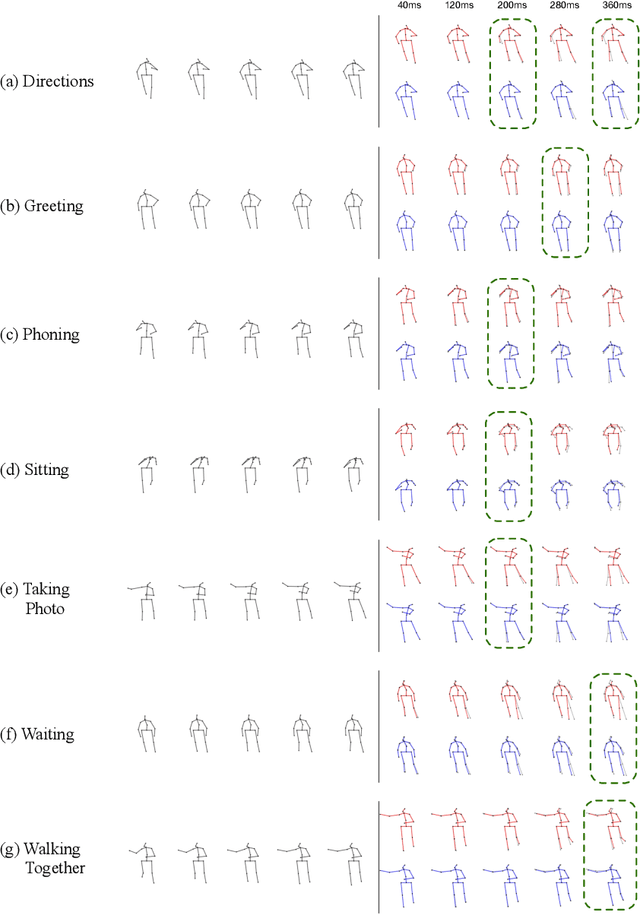
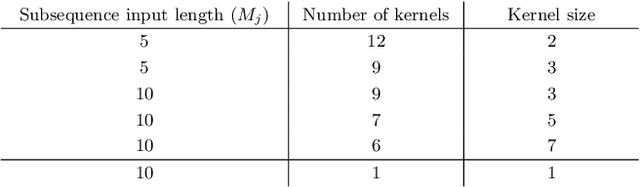
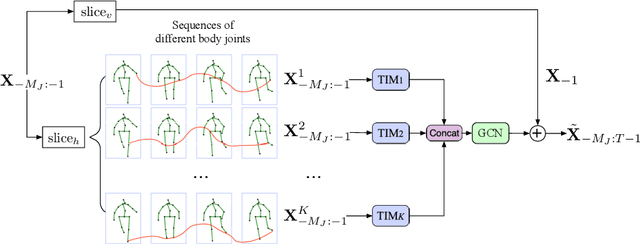
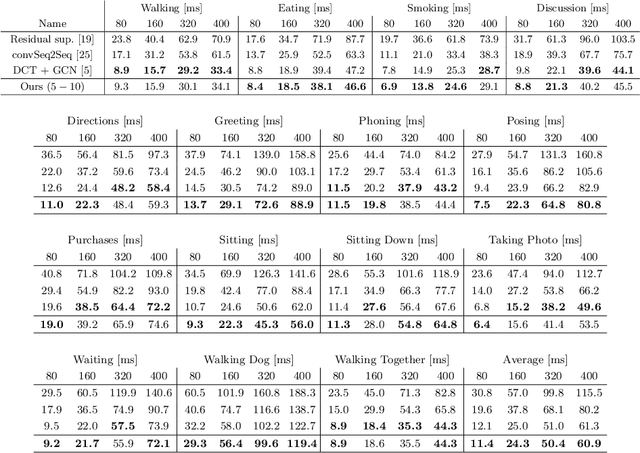
Human motion prediction is a necessary component for many applications in robotics and autonomous driving. Recent methods propose using sequence-to-sequence deep learning models to tackle this problem. However, they do not focus on exploiting different temporal scales for different length inputs. We argue that the diverse temporal scales are important as they allow us to look at the past frames with different receptive fields, which can lead to better predictions. In this paper, we propose a Temporal Inception Module (TIM) to encode human motion. Making use of TIM, our framework produces input embeddings using convolutional layers, by using different kernel sizes for different input lengths. The experimental results on standard motion prediction benchmark datasets Human3.6M and CMU motion capture dataset show that our approach consistently outperforms the state of the art methods.
Robust RGB-based 6-DoF Pose Estimation without Real Pose Annotations
Aug 19, 2020
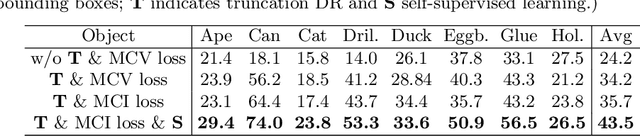
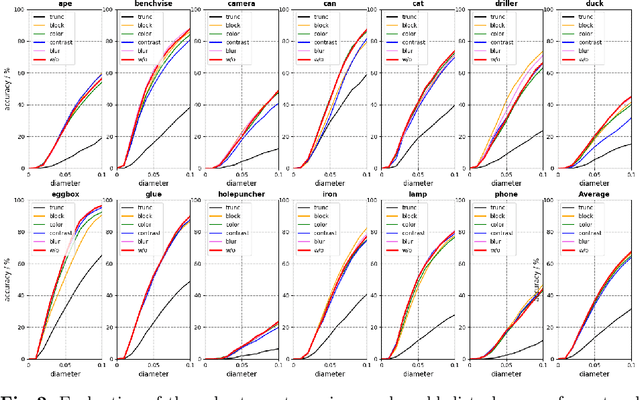

While much progress has been made in 6-DoF object pose estimation from a single RGB image, the current leading approaches heavily rely on real-annotation data. As such, they remain sensitive to severe occlusions, because covering all possible occlusions with annotated data is intractable. In this paper, we introduce an approach to robustly and accurately estimate the 6-DoF pose in challenging conditions and without using any real pose annotations. To this end, we leverage the intuition that the poses predicted by a network from an image and from its counterpart synthetically altered to mimic occlusion should be consistent, and translate this to a self-supervised loss function. Our experiments on LINEMOD, Occluded-LINEMOD, YCB and new Randomization LINEMOD dataset evidence the robustness of our approach. We achieve state of the art performance on LINEMOD, and OccludedLINEMOD in without real-pose setting, even outperforming methods that rely on real annotations during training on Occluded-LINEMOD.
History Repeats Itself: Human Motion Prediction via Motion Attention
Jul 23, 2020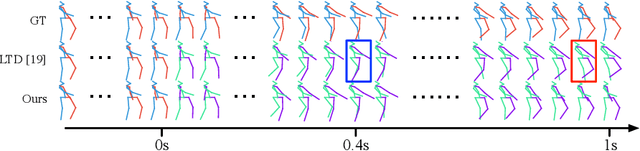
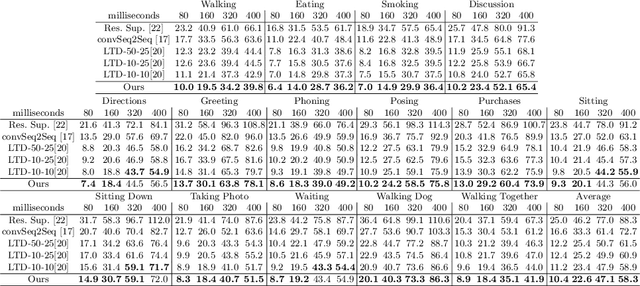
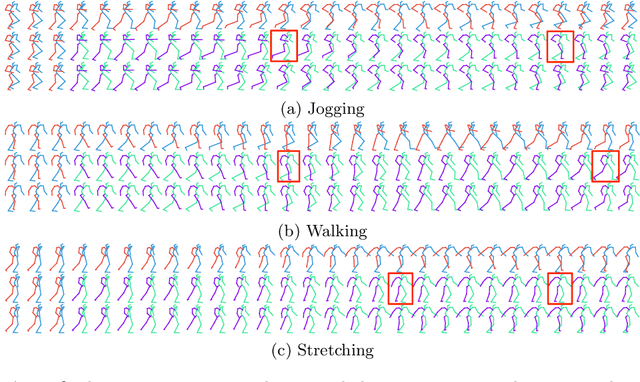
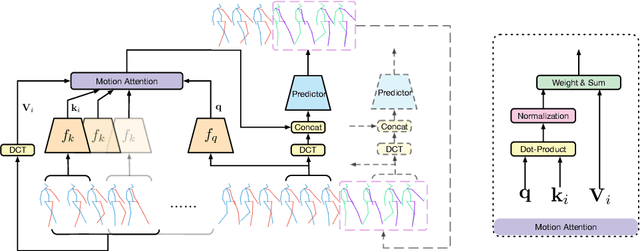
Human motion prediction aims to forecast future human poses given a past motion. Whether based on recurrent or feed-forward neural networks, existing methods fail to model the observation that human motion tends to repeat itself, even for complex sports actions and cooking activities. Here, we introduce an attention-based feed-forward network that explicitly leverages this observation. In particular, instead of modeling frame-wise attention via pose similarity, we propose to extract motion attention to capture the similarity between the current motion context and the historical motion sub-sequences. Aggregating the relevant past motions and processing the result with a graph convolutional network allows us to effectively exploit motion patterns from the long-term history to predict the future poses. Our experiments on Human3.6M, AMASS and 3DPW evidence the benefits of our approach for both periodical and non-periodical actions. Thanks to our attention model, it yields state-of-the-art results on all three datasets. Our code is available at https://github.com/wei-mao-2019/HisRepItself.
GarNet++: Improving Fast and Accurate Static3D Cloth Draping by Curvature Loss
Jul 20, 2020
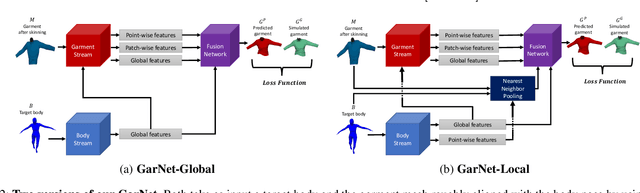
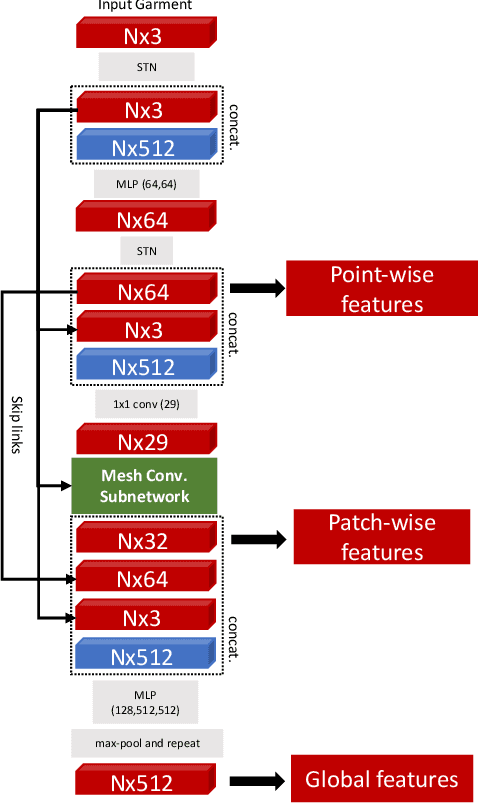
In this paper, we tackle the problem of static 3D cloth draping on virtual human bodies. We introduce a two-stream deep network model that produces a visually plausible draping of a template cloth on virtual 3D bodies by extracting features from both the body and garment shapes. Our network learns to mimic a Physics-Based Simulation (PBS) method while requiring two orders of magnitude less computation time. To train the network, we introduce loss terms inspired by PBS to produce plausible results and make the model collision-aware. To increase the details of the draped garment, we introduce two loss functions that penalize the difference between the curvature of the predicted cloth and PBS. Particularly, we study the impact of mean curvature normal and a novel detail-preserving loss both qualitatively and quantitatively. Our new curvature loss computes the local covariance matrices of the 3D points, and compares the Rayleigh quotients of the prediction and PBS. This leads to more details while performing favorably or comparably against the loss that considers mean curvature normal vectors in the 3D triangulated meshes. We validate our framework on four garment types for various body shapes and poses. Finally, we achieve superior performance against a recently proposed data-driven method.
Volumetric Transformer Networks
Jul 18, 2020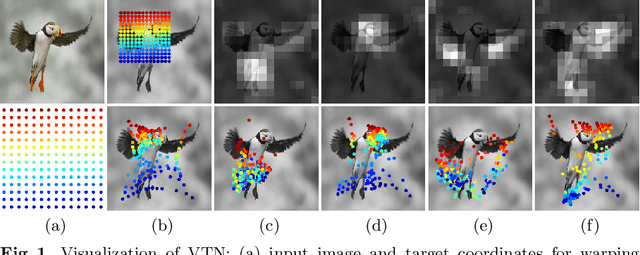
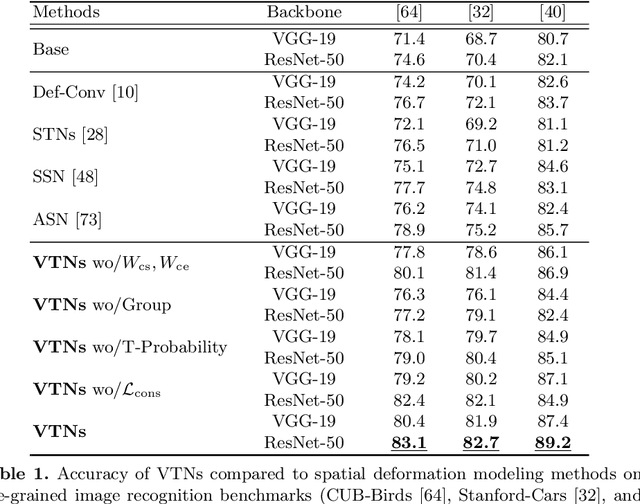
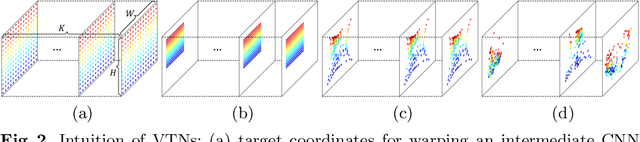
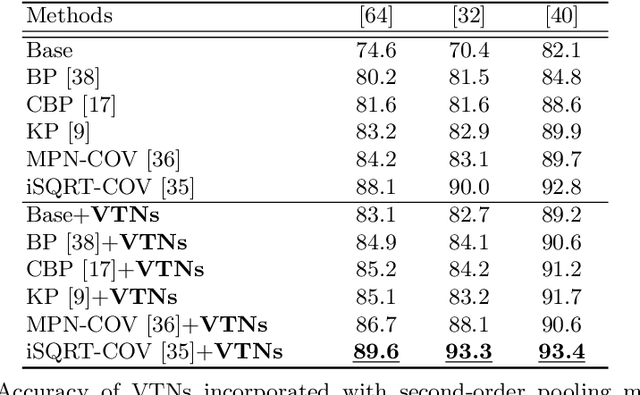
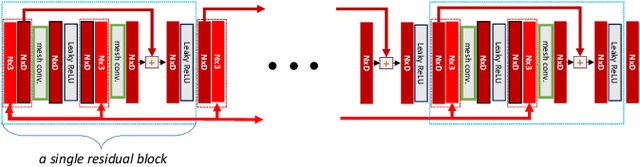
Existing techniques to encode spatial invariance within deep convolutional neural networks (CNNs) apply the same warping field to all the feature channels. This does not account for the fact that the individual feature channels can represent different semantic parts, which can undergo different spatial transformations w.r.t. a canonical configuration. To overcome this limitation, we introduce a learnable module, the volumetric transformer network (VTN), that predicts channel-wise warping fields so as to reconfigure intermediate CNN features spatially and channel-wisely. We design our VTN as an encoder-decoder network, with modules dedicated to letting the information flow across the feature channels, to account for the dependencies between the semantic parts. We further propose a loss function defined between the warped features of pairs of instances, which improves the localization ability of VTN. Our experiments show that VTN consistently boosts the features' representation power and consequently the networks' accuracy on fine-grained image recognition and instance-level image retrieval.
Learning 3D-3D Correspondences for One-shot Partial-to-partial Registration
Jun 16, 2020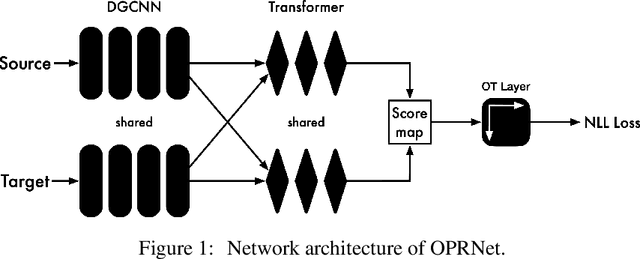
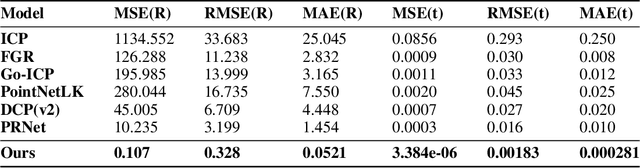
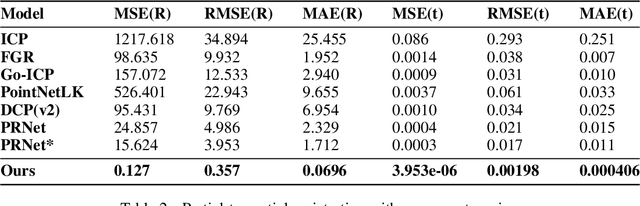

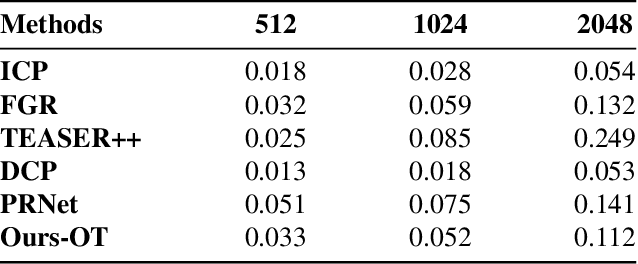
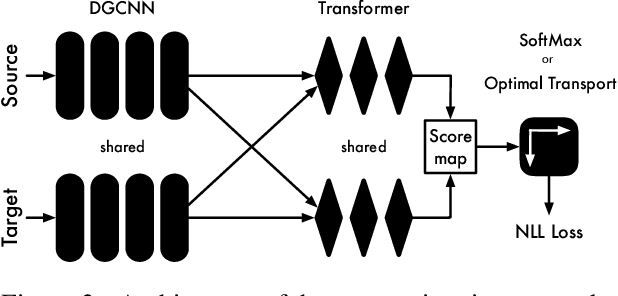
While 3D-3D registration is traditionally tacked by optimization-based methods, recent work has shown that learning-based techniques could achieve faster and more robust results. In this context, however, only PRNet can handle the partial-to-partial registration scenario. Unfortunately, this is achieved at the cost of relying on an iterative procedure, with a complex network architecture. Here, we show that learning-based partial-to-partial registration can be achieved in a one-shot manner, jointly reducing network complexity and increasing registration accuracy. To this end, we propose an Optimal Transport layer able to account for occluded points thanks to the use of outlier bins. The resulting OPRNet framework outperforms the state of the art on standard benchmarks, demonstrating better robustness and generalization ability than existing techniques.