 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinite Time Horizon Safety of Bayesian Neural Networks
Nov 04, 2021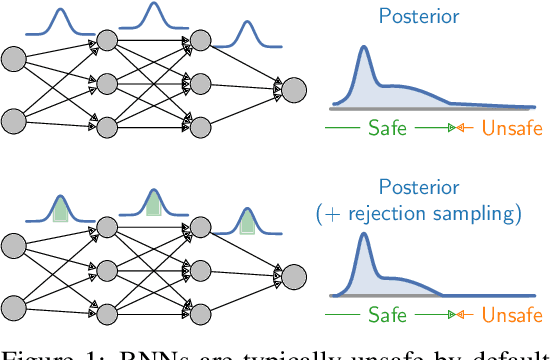

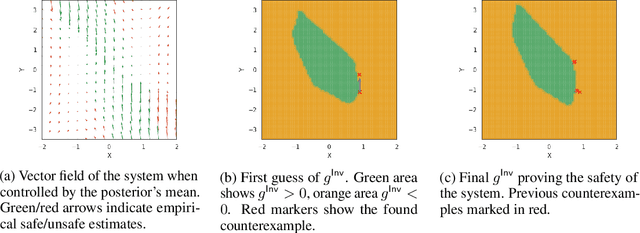

Bayesian neural networks (BNNs) place distributions over the weights of a neural network to model uncertainty in the data and the network's prediction. We consider the problem of verifying safety when running a Bayesian neural network policy in a feedback loop with infinite time horizon systems. Compared to the existing sampling-based approaches, which are inapplicable to the infinite time horizon setting, we train a separate deterministic neural network that serves as an infinite time horizon safety certificate. In particular, we show that the certificate network guarantees the safety of the system over a subset of the BNN weight posterior's support. Our method first computes a safe weight set and then alters the BNN's weight posterior to reject samples outside this set. Moreover, we show how to extend our approach to a safe-exploration reinforcement learning setting, in order to avoid unsafe trajectories during the training of the policy. We evaluate our approach on a series of reinforcement learning benchmarks, including non-Lyapunovian safety specifications.
Interactive Analysis of CNN Robustness
Oct 14, 2021
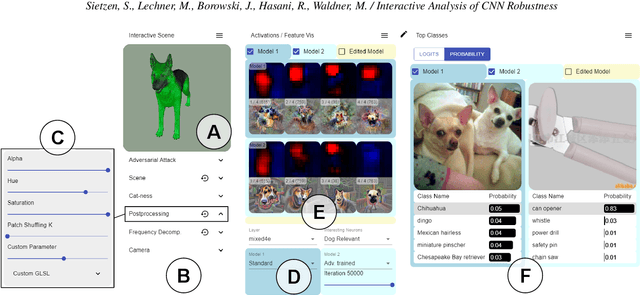

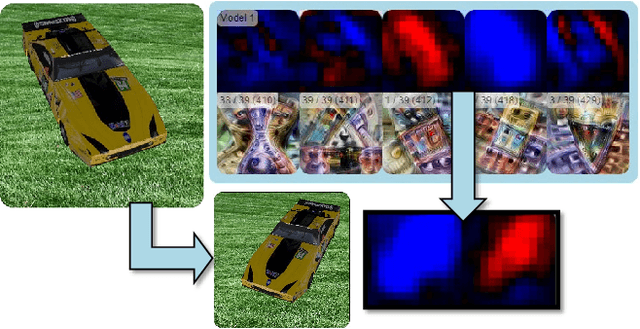
While convolutional neural networks (CNNs) have found wide adoption as state-of-the-art models for image-related tasks, their predictions are often highly sensitive to small input perturbations, which the human vision is robust against. This paper presents Perturber, a web-based application that allows users to instantaneously explore how CNN activations and predictions evolve when a 3D input scene is interactively perturbed. Perturber offers a large variety of scene modifications, such as camera controls, lighting and shading effects, background modifications, object morphing, as well as adversarial attacks, to facilitate the discovery of potential vulnerabilities. Fine-tuned model versions can be directly compared for qualitative evaluation of their robustness. Case studies with machine learning experts have shown that Perturber helps users to quickly generate hypotheses about model vulnerabilities and to qualitatively compare model behavior. Using quantitative analyses, we could replicate users' insights with other CNN architectures and input images, yielding new insights about the vulnerability of adversarially trained models.
GoTube: Scalable Stochastic Verification of Continuous-Depth Models
Jul 18, 2021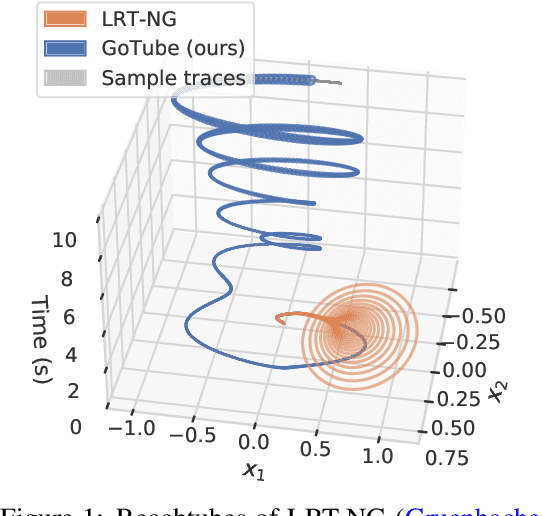
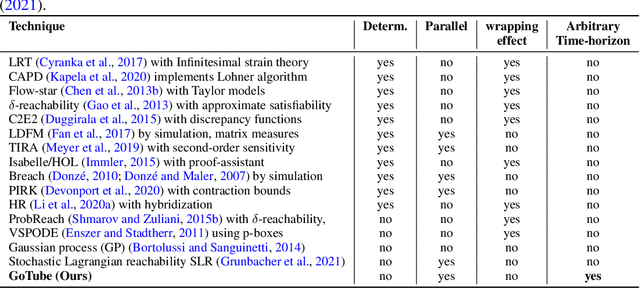
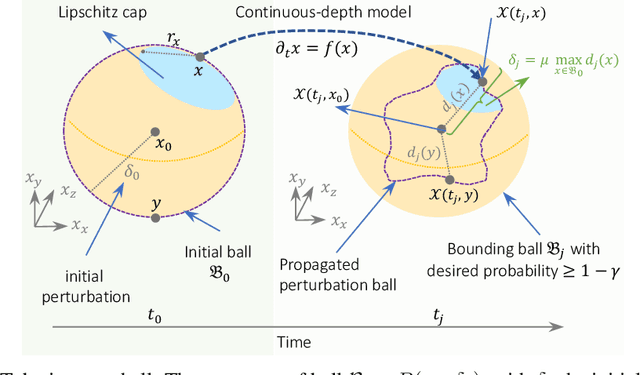
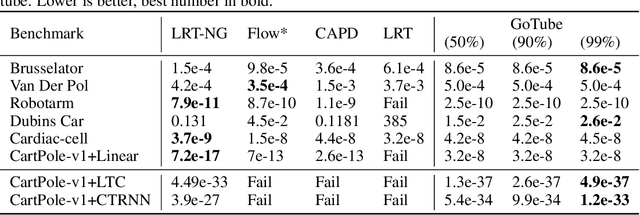
We introduce a new stochastic verification algorithm that formally quantifies the behavioral robustness of any time-continuous process formulated as a continuous-depth model. The algorithm solves a set of global optimization (Go) problems over a given time horizon to construct a tight enclosure (Tube) of the set of all process executions starting from a ball of initial states. We call our algorithm GoTube. Through its construction, GoTube ensures that the bounding tube is conservative up to a desired probability. GoTube is implemented in JAX and optimized to scale to complex continuous-depth models. Compared to advanced reachability analysis tools for time-continuous neural networks, GoTube provably does not accumulate over-approximation errors between time steps and avoids the infamous wrapping effect inherent in symbolic techniques. We show that GoTube substantially outperforms state-of-the-art verification tools in terms of the size of the initial ball, speed, time-horizon, task completion, and scalability, on a large set of experiments. GoTube is stable and sets the state-of-the-art for its ability to scale up to time horizons well beyond what has been possible before.
Closed-form Continuous-Depth Models
Jun 25, 2021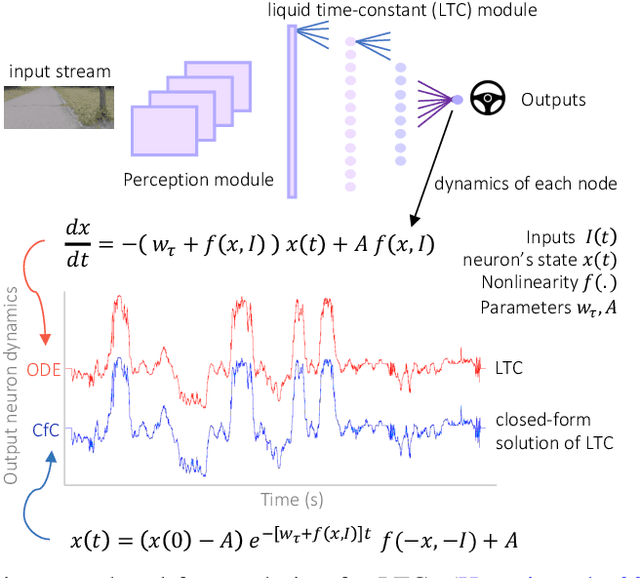
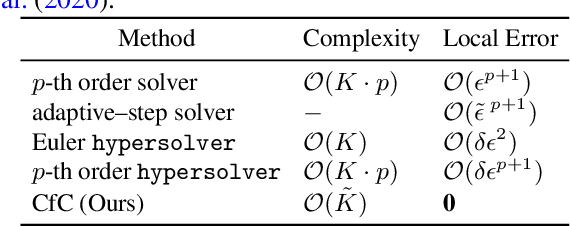
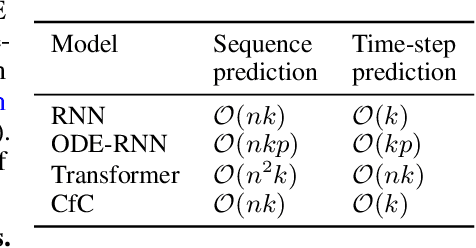
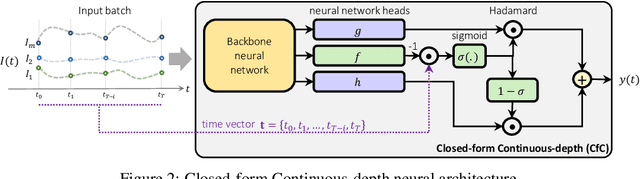
Continuous-depth neural models, where the derivative of the model's hidden state is defined by a neural network, have enabled strong sequential data processing capabilities. However, these models rely on advanced numerical differential equation (DE) solvers resulting in a significant overhead both in terms of computational cost and model complexity. In this paper, we present a new family of models, termed Closed-form Continuous-depth (CfC) networks, that are simple to describe and at least one order of magnitude faster while exhibiting equally strong modeling abilities compared to their ODE-based counterparts. The models are hereby derived from the analytical closed-form solution of an expressive subset of time-continuous models, thus alleviating the need for complex DE solvers all together. In our experimental evaluations, we demonstrate that CfC networks outperform advanced, recurrent models over a diverse set of time-series prediction tasks, including those with long-term dependencies and irregularly sampled data. We believe our findings open new opportunities to train and deploy rich, continuous neural models in resource-constrained settings, which demand both performance and efficiency.
Causal Navigation by Continuous-time Neural Networks
Jun 15, 2021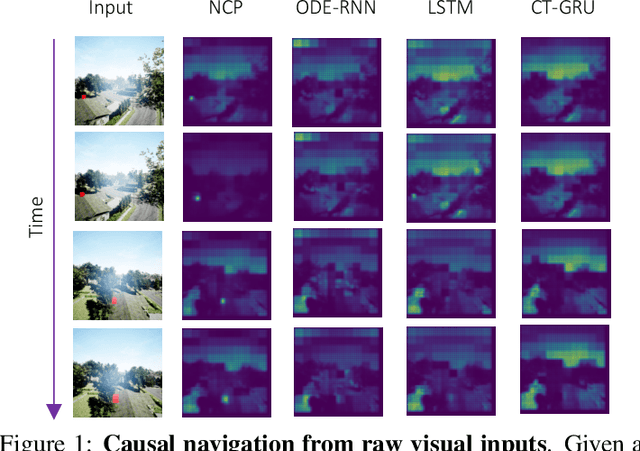
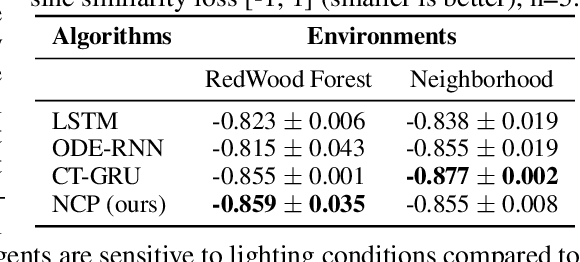

Imitation learning enables high-fidelity, vision-based learning of policies within rich, photorealistic environments. However, such techniques often rely on traditional discrete-time neural models and face difficulties in generalizing to domain shifts by failing to account for the causal relationships between the agent and the environment. In this paper, we propose a theoretical and experimental framework for learning causal representations using continuous-time neural networks, specifically over their discrete-time counterparts. We evaluate our method in the context of visual-control learning of drones over a series of complex tasks, ranging from short- and long-term navigation, to chasing static and dynamic objects through photorealistic environments. Our results demonstrate that causal continuous-time deep models can perform robust navigation tasks, where advanced recurrent models fail. These models learn complex causal control representations directly from raw visual inputs and scale to solve a variety of tasks using imitation learning.
On-Off Center-Surround Receptive Fields for Accurate and Robust Image Classification
Jun 13, 2021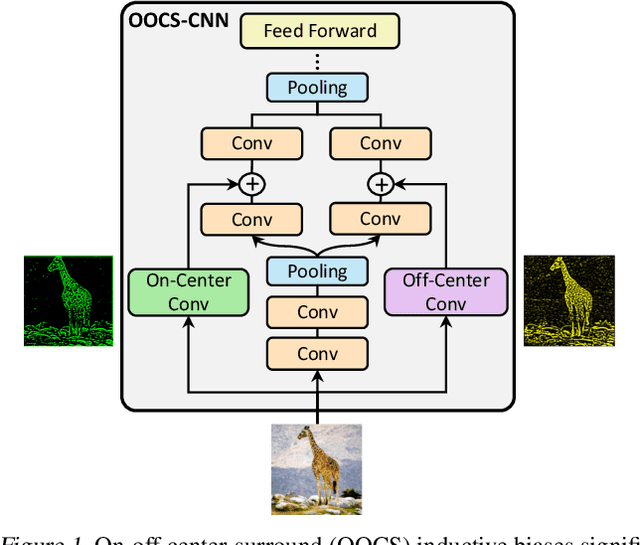
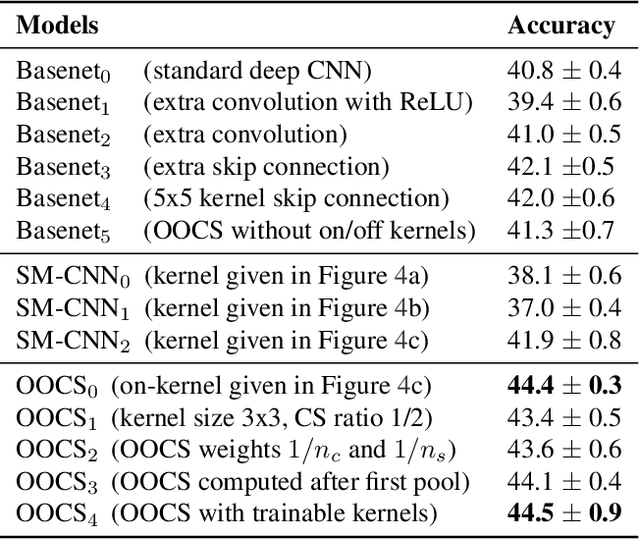
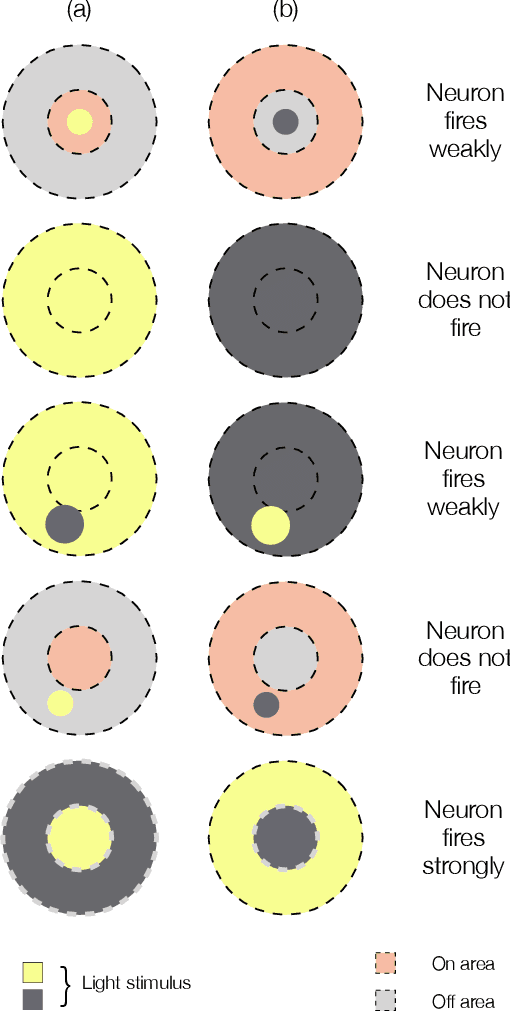

Robustness to variations in lighting conditions is a key objective for any deep vision system. To this end, our paper extends the receptive field of convolutional neural networks with two residual components, ubiquitous in the visual processing system of vertebrates: On-center and off-center pathways, with excitatory center and inhibitory surround; OOCS for short. The on-center pathway is excited by the presence of a light stimulus in its center but not in its surround, whereas the off-center one is excited by the absence of a light stimulus in its center but not in its surround. We design OOCS pathways via a difference of Gaussians, with their variance computed analytically from the size of the receptive fields. OOCS pathways complement each other in their response to light stimuli, ensuring this way a strong edge-detection capability, and as a result, an accurate and robust inference under challenging lighting conditions. We provide extensive empirical evidence showing that networks supplied with the OOCS edge representation gain accuracy and illumination-robustness compared to standard deep models.
Adversarial Training is Not Ready for Robot Learning
Mar 15, 2021



Adversarial training is an effective method to train deep learning models that are resilient to norm-bounded perturbations, with the cost of nominal performance drop. While adversarial training appears to enhance the robustness and safety of a deep model deployed in open-world decision-critical applications, counterintuitively, it induces undesired behaviors in robot learning settings. In this paper, we show theoretically and experimentally that neural controllers obtained via adversarial training are subjected to three types of defects, namely transient, systematic, and conditional errors. We first generalize adversarial training to a safety-domain optimization scheme allowing for more generic specifications. We then prove that such a learning process tends to cause certain error profiles. We support our theoretical results by a thorough experimental safety analysis in a robot-learning task. Our results suggest that adversarial training is not yet ready for robot learning.
Model-based versus Model-free Deep Reinforcement Learning for Autonomous Racing Cars
Mar 08, 2021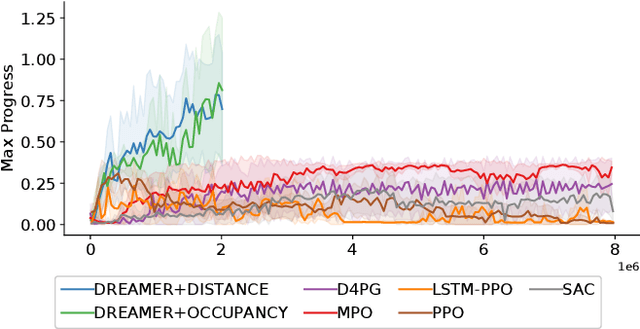
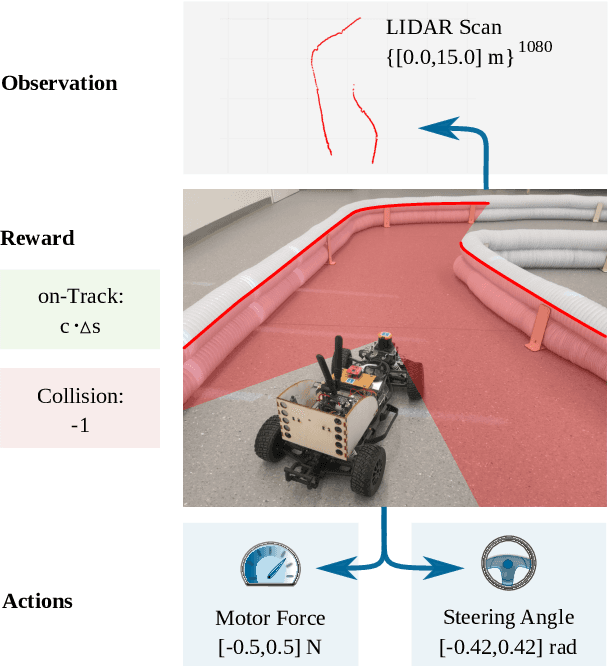

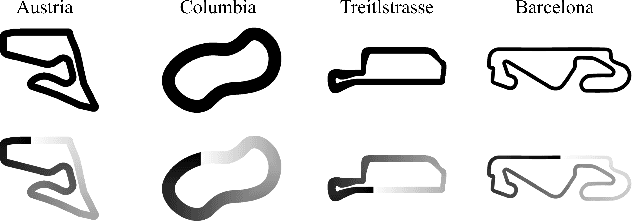
Despite the rich theoretical foundation of model-based deep reinforcement learning (RL) agents, their effectiveness in real-world robotics-applications is less studied and understood. In this paper, we, therefore, investigate how such agents generalize to real-world autonomous-vehicle control-tasks, where advanced model-free deep RL algorithms fail. In particular, we set up a series of time-lap tasks for an F1TENTH racing robot, equipped with high-dimensional LiDAR sensors, on a set of test tracks with a gradual increase in their complexity. In this continuous-control setting, we show that model-based agents capable of learning in imagination, substantially outperform model-free agents with respect to performance, sample efficiency, successful task completion, and generalization. Moreover, we show that the generalization ability of model-based agents strongly depends on the observation-model choice. Finally, we provide extensive empirical evidence for the effectiveness of model-based agents provided with long enough memory horizons in sim2real tasks.
On The Verification of Neural ODEs with Stochastic Guarantees
Dec 16, 2020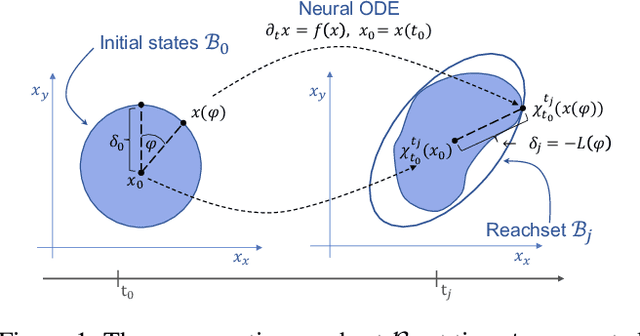
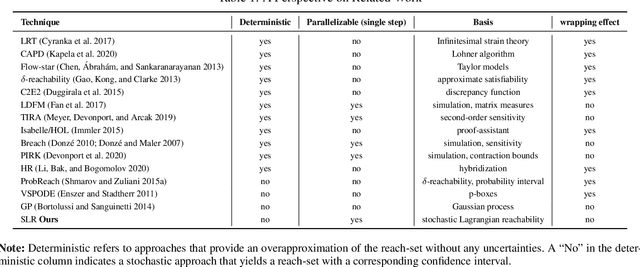
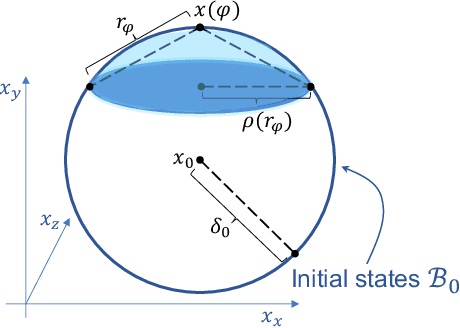
We show that Neural ODEs, an emerging class of time-continuous neural networks, can be verified by solving a set of global-optimization problems. For this purpose, we introduce Stochastic Lagrangian Reachability (SLR), an abstraction-based technique for constructing a tight Reachtube (an over-approximation of the set of reachable states over a given time-horizon), and provide stochastic guarantees in the form of confidence intervals for the Reachtube bounds. SLR inherently avoids the infamous wrapping effect (accumulation of over-approximation errors) by performing local optimization steps to expand safe regions instead of repeatedly forward-propagating them as is done by deterministic reachability methods. To enable fast local optimizations, we introduce a novel forward-mode adjoint sensitivity method to compute gradients without the need for backpropagation. Finally, we establish asymptotic and non-asymptotic convergence rates for SLR.
Scalable Verification of Quantized Neural Networks (Technical Report)
Dec 15, 2020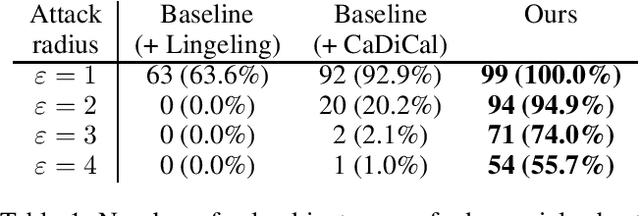
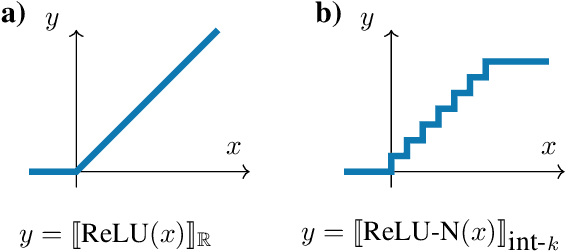


Formal verification of neural networks is an active topic of research, and recent advances have significantly increased the size of the networks that verification tools can handle. However, most methods are designed for verification of an idealized model of the actual network which works over real arithmetic and ignores rounding imprecisions. This idealization is in stark contrast to network quantization, which is a technique that trades numerical precision for computational efficiency and is, therefore, often applied in practice. Neglecting rounding errors of such low-bit quantized neural networks has been shown to lead to wrong conclusions about the network's correctness. Thus, the desired approach for verifying quantized neural networks would be one that takes these rounding errors into account. In this paper, we show that verifying the bit-exact implementation of quantized neural networks with bit-vector specifications is PSPACE-hard, even though verifying idealized real-valued networks and satisfiability of bit-vector specifications alone are each in NP. Furthermore, we explore several practical heuristics toward closing the complexity gap between idealized and bit-exact verification. In particular, we propose three techniques for making SMT-based verification of quantized neural networks more scalable. Our experiments demonstrate that our proposed methods allow a speedup of up to three orders of magnitude over existing approaches.