 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Control Policies for Region Stabilization in Stochastic Systems
Oct 11, 2022
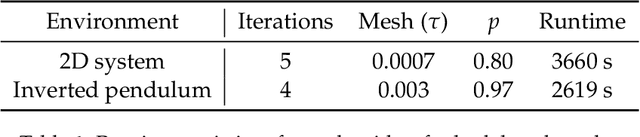
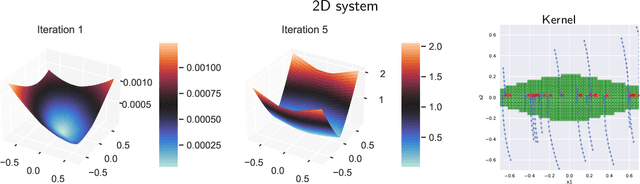
We consider the problem of learning control policies in stochastic systems which guarantee that the system stabilizes within some specified stabilization region with probability $1$. Our approach is based on the novel notion of stabilizing ranking supermartingales (sRSMs) that we introduce in this work. Our sRSMs overcome the limitation of methods proposed in previous works whose applicability is restricted to systems in which the stabilizing region cannot be left once entered under any control policy. We present a learning procedure that learns a control policy together with an sRSM that formally certifies probability-$1$ stability, both learned as neural networks. Our experimental evaluation shows that our learning procedure can successfully learn provably stabilizing policies in practice.
Learning Control Policies for Stochastic Systems with Reach-avoid Guarantees
Oct 11, 2022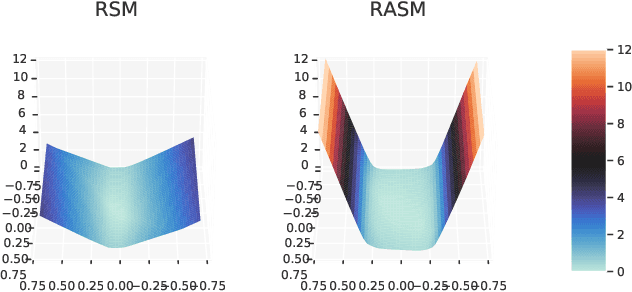


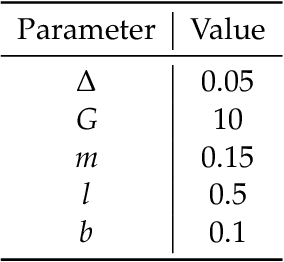
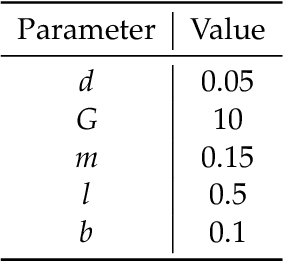
We study the problem of learning controllers for discrete-time non-linear stochastic dynamical systems with formal reach-avoid guarantees. This work presents the first method for providing formal reach-avoid guarantees, which combine and generalize stability and safety guarantees, with a tolerable probability threshold $p\in[0,1]$ over the infinite time horizon. Our method leverages advances in machine learning literature and it represents formal certificates as neural networks. In particular, we learn a certificate in the form of a reach-avoid supermartingale (RASM), a novel notion that we introduce in this work. Our RASMs provide reachability and avoidance guarantees by imposing constraints on what can be viewed as a stochastic extension of level sets of Lyapunov functions for deterministic systems. Our approach solves several important problems -- it can be used to learn a control policy from scratch, to verify a reach-avoid specification for a fixed control policy, or to fine-tune a pre-trained policy if it does not satisfy the reach-avoid specification. We validate our approach on $3$ stochastic non-linear reinforcement learning tasks.
PyHopper -- Hyperparameter optimization
Oct 10, 2022
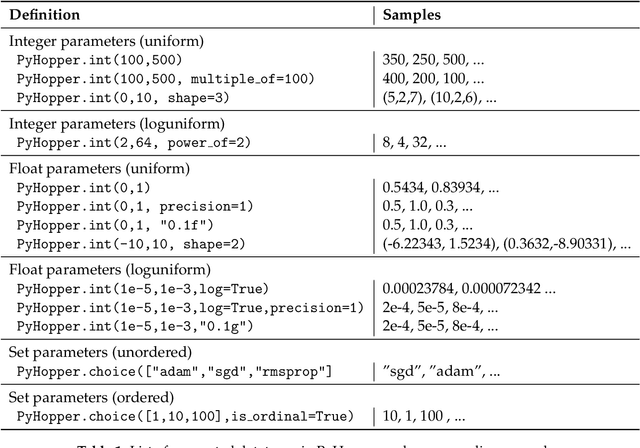
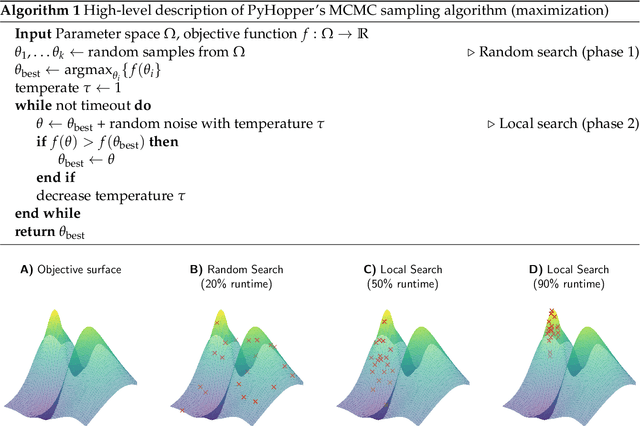
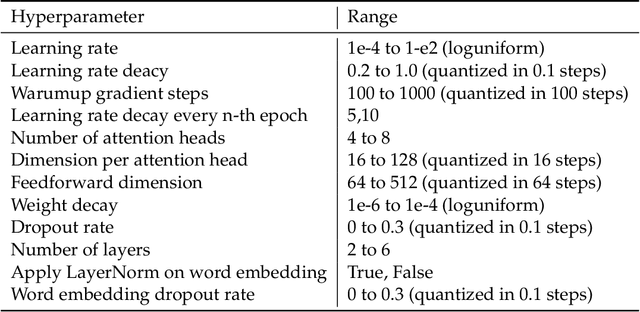
Hyperparameter tuning is a fundamental aspect of machine learning research. Setting up the infrastructure for systematic optimization of hyperparameters can take a significant amount of time. Here, we present PyHopper, a black-box optimization platform designed to streamline the hyperparameter tuning workflow of machine learning researchers. PyHopper's goal is to integrate with existing code with minimal effort and run the optimization process with minimal necessary manual oversight. With simplicity as the primary theme, PyHopper is powered by a single robust Markov-chain Monte-Carlo optimization algorithm that scales to millions of dimensions. Compared to existing tuning packages, focusing on a single algorithm frees the user from having to decide between several algorithms and makes PyHopper easily customizable. PyHopper is publicly available under the Apache-2.0 license at https://github.com/PyHopper/PyHopper.
On the Forward Invariance of Neural ODEs
Oct 10, 2022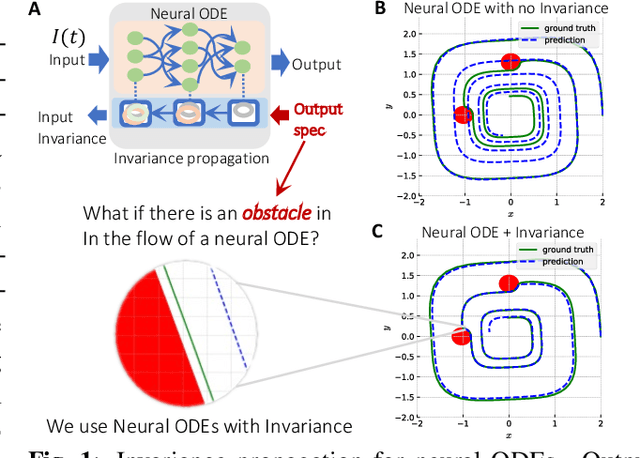

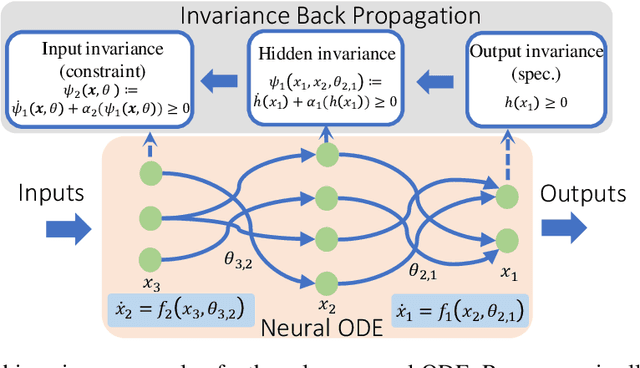
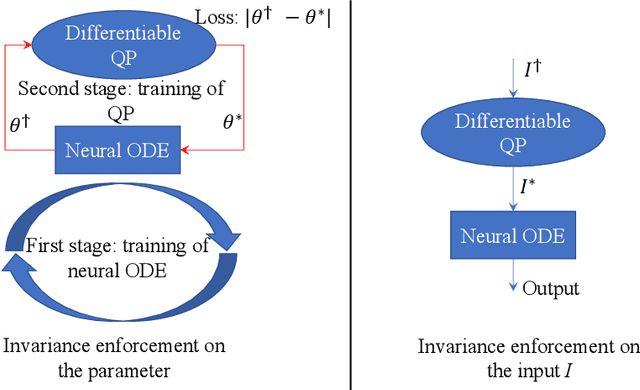
To ensure robust and trustworthy decision-making, it is highly desirable to enforce constraints over a neural network's parameters and its inputs automatically by back-propagating output specifications. This way, we can guarantee that the network makes reliable decisions under perturbations. Here, we propose a new method for achieving a class of specification guarantees for neural Ordinary Differentiable Equations (ODEs) by using invariance set propagation. An invariance of a neural ODE is defined as an output specification, such as to satisfy mathematical formulae, physical laws, and system safety. We use control barrier functions to specify the invariance of a neural ODE on the output layer and propagate it back to the input layer. Through the invariance backpropagation, we map output specifications onto constraints on the neural ODE parameters or its input. The satisfaction of the corresponding constraints implies the satisfaction of output specifications. This allows us to achieve output specification guarantees by changing the input or parameters while maximally preserving the model performance. We demonstrate the invariance propagation on a comprehensive series of representation learning tasks, including spiral curve regression, autoregressive modeling of joint physical dynamics, convexity portrait of a function, and safe neural control of collision avoidance for autonomous vehicles.
Are All Vision Models Created Equal? A Study of the Open-Loop to Closed-Loop Causality Gap
Oct 09, 2022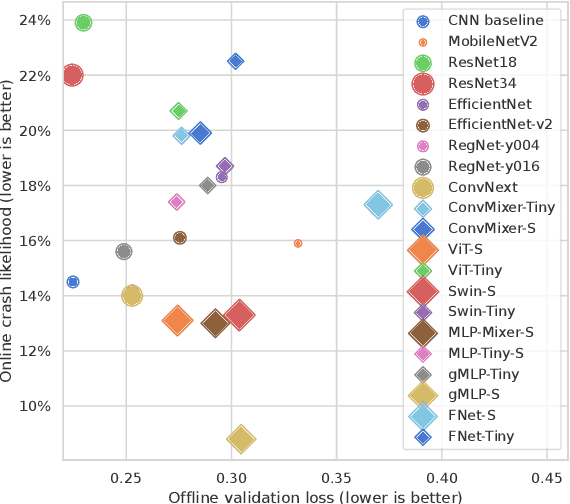
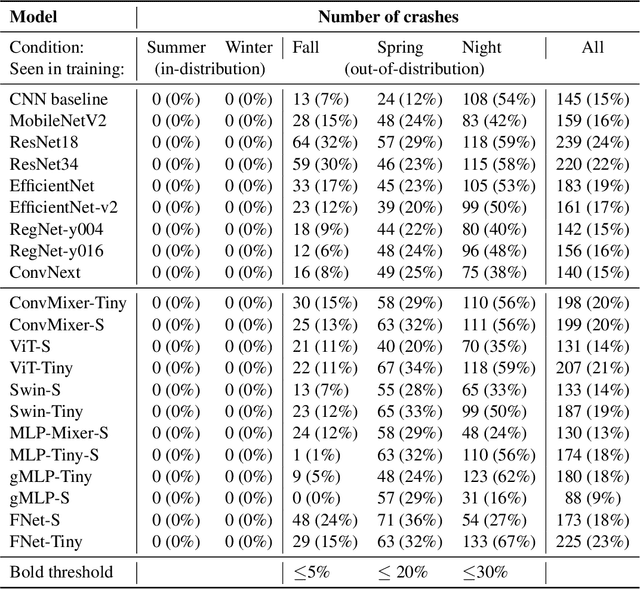

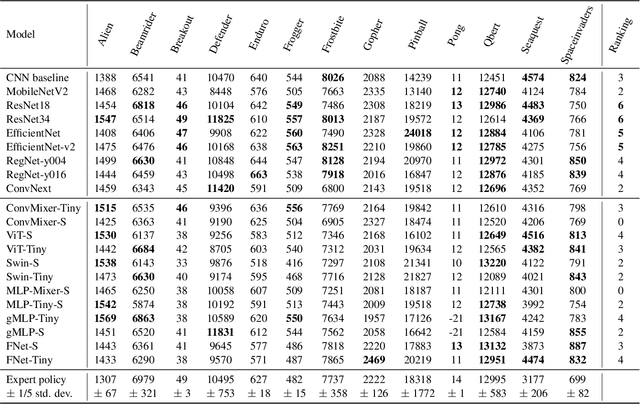
There is an ever-growing zoo of modern neural network models that can efficiently learn end-to-end control from visual observations. These advanced deep models, ranging from convolutional to patch-based networks, have been extensively tested on offline image classification and regression tasks. In this paper, we study these vision architectures with respect to the open-loop to closed-loop causality gap, i.e., offline training followed by an online closed-loop deployment. This causality gap typically emerges in robotics applications such as autonomous driving, where a network is trained to imitate the control commands of a human. In this setting, two situations arise: 1) Closed-loop testing in-distribution, where the test environment shares properties with those of offline training data. 2) Closed-loop testing under distribution shifts and out-of-distribution. Contrary to recently reported results, we show that under proper training guidelines, all vision models perform indistinguishably well on in-distribution deployment, resolving the causality gap. In situation 2, We observe that the causality gap disrupts performance regardless of the choice of the model architecture. Our results imply that the causality gap can be solved in situation one with our proposed training guideline with any modern network architecture, whereas achieving out-of-distribution generalization (situation two) requires further investigations, for instance, on data diversity rather than the model architecture.
Liquid Structural State-Space Models
Sep 26, 2022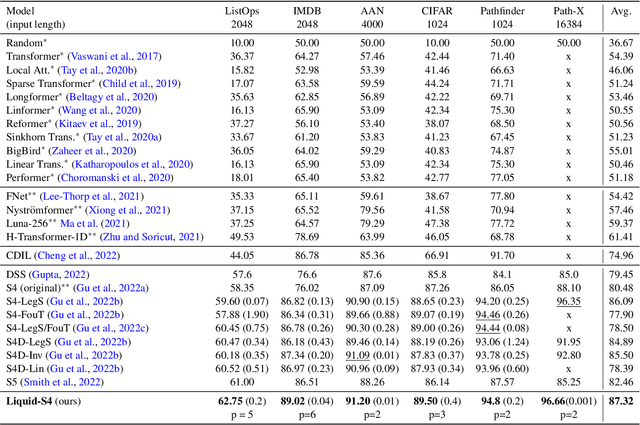
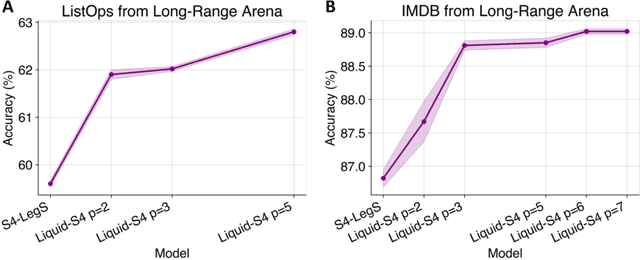
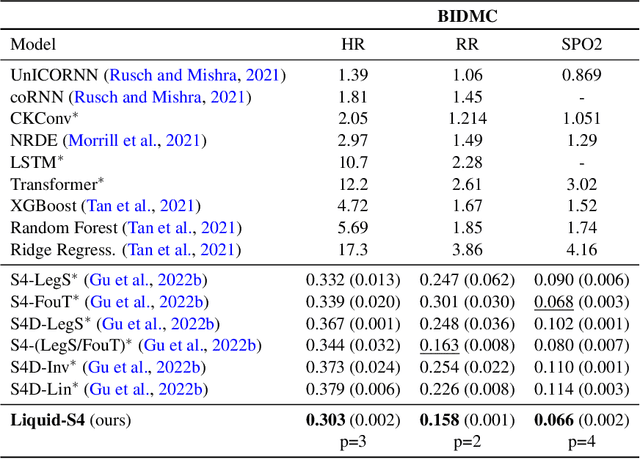
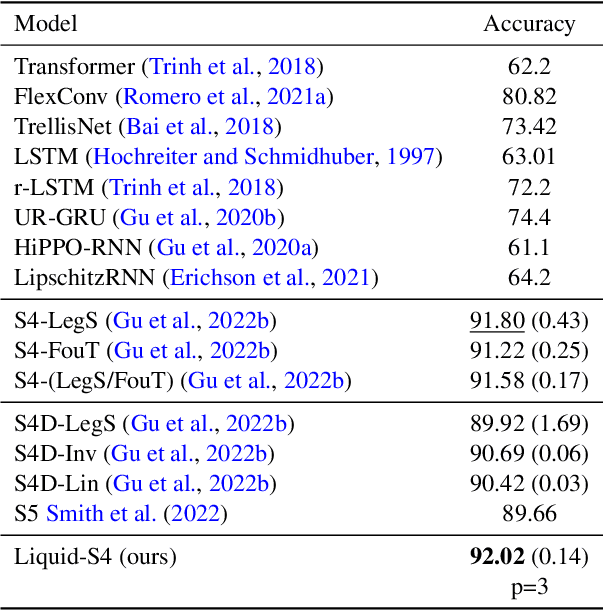
A proper parametrization of state transition matrices of linear state-space models (SSMs) followed by standard nonlinearities enables them to efficiently learn representations from sequential data, establishing the state-of-the-art on a large series of long-range sequence modeling benchmarks. In this paper, we show that we can improve further when the structural SSM such as S4 is given by a linear liquid time-constant (LTC) state-space model. LTC neural networks are causal continuous-time neural networks with an input-dependent state transition module, which makes them learn to adapt to incoming inputs at inference. We show that by using a diagonal plus low-rank decomposition of the state transition matrix introduced in S4, and a few simplifications, the LTC-based structural state-space model, dubbed Liquid-S4, achieves the new state-of-the-art generalization across sequence modeling tasks with long-term dependencies such as image, text, audio, and medical time-series, with an average performance of 87.32% on the Long-Range Arena benchmark. On the full raw Speech Command recognition, dataset Liquid-S4 achieves 96.78% accuracy with a 30% reduction in parameter counts compared to S4. The additional gain in performance is the direct result of the Liquid-S4's kernel structure that takes into account the similarities of the input sequence samples during training and inference.
Entangled Residual Mappings
Jun 02, 2022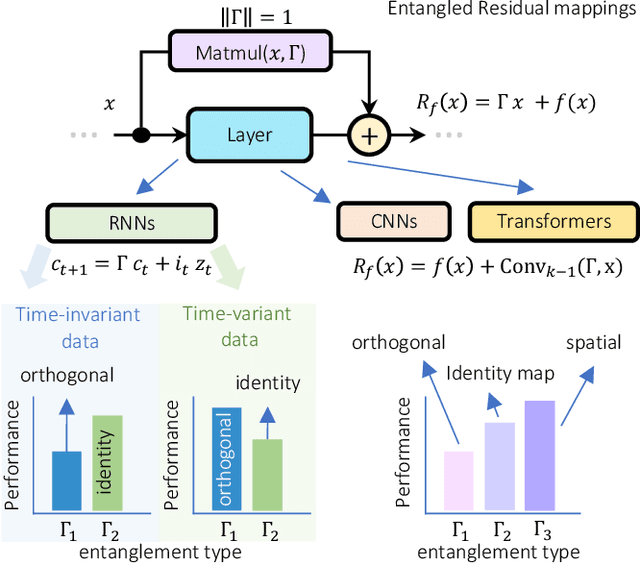
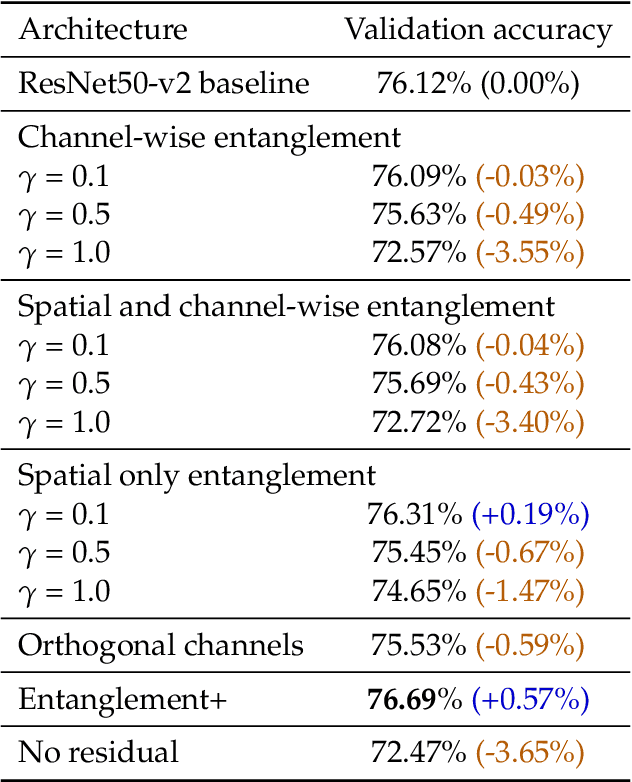
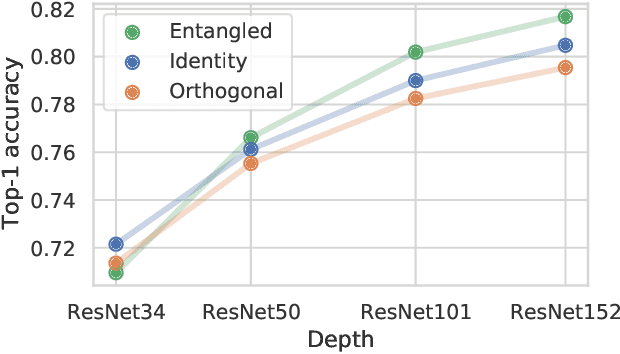
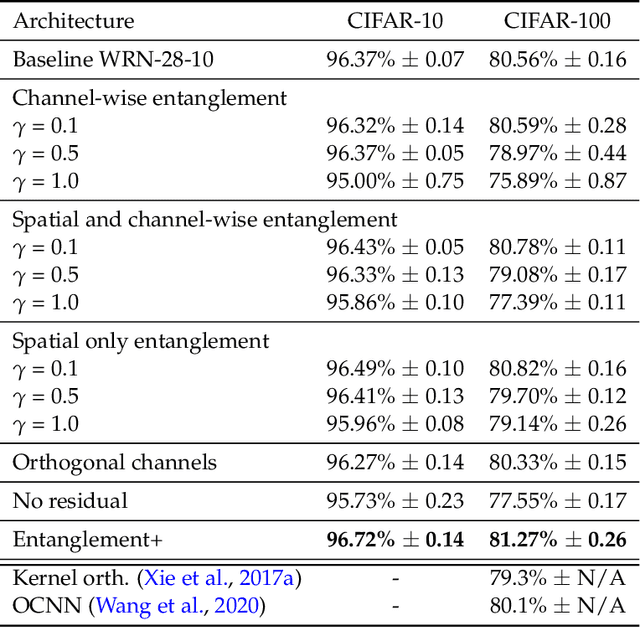
Residual mappings have been shown to perform representation learning in the first layers and iterative feature refinement in higher layers. This interplay, combined with their stabilizing effect on the gradient norms, enables them to train very deep networks. In this paper, we take a step further and introduce entangled residual mappings to generalize the structure of the residual connections and evaluate their role in iterative learning representations. An entangled residual mapping replaces the identity skip connections with specialized entangled mappings such as orthogonal, sparse, and structural correlation matrices that share key attributes (eigenvalues, structure, and Jacobian norm) with identity mappings. We show that while entangled mappings can preserve the iterative refinement of features across various deep models, they influence the representation learning process in convolutional networks differently than attention-based models and recurrent neural networks. In general, we find that for CNNs and Vision Transformers entangled sparse mapping can help generalization while orthogonal mappings hurt performance. For recurrent networks, orthogonal residual mappings form an inductive bias for time-variant sequences, which degrades accuracy on time-invariant tasks.
Learning Stabilizing Policies in Stochastic Control Systems
May 24, 2022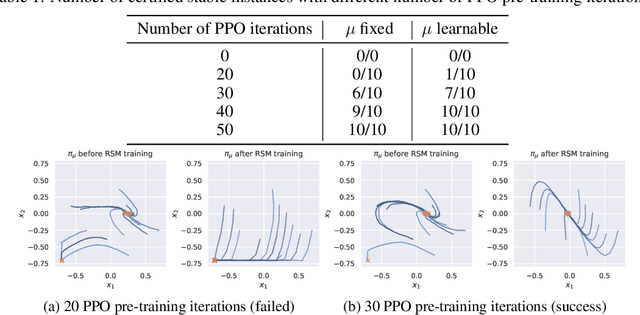

In this work, we address the problem of learning provably stable neural network policies for stochastic control systems. While recent work has demonstrated the feasibility of certifying given policies using martingale theory, the problem of how to learn such policies is little explored. Here, we study the effectiveness of jointly learning a policy together with a martingale certificate that proves its stability using a single learning algorithm. We observe that the joint optimization problem becomes easily stuck in local minima when starting from a randomly initialized policy. Our results suggest that some form of pre-training of the policy is required for the joint optimization to repair and verify the policy successfully.
Revisiting the Adversarial Robustness-Accuracy Tradeoff in Robot Learning
Apr 15, 2022


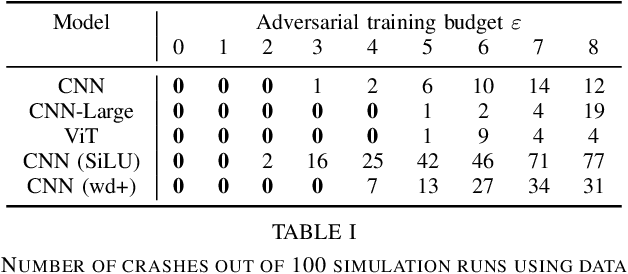
Adversarial training (i.e., training on adversarially perturbed input data) is a well-studied method for making neural networks robust to potential adversarial attacks during inference. However, the improved robustness does not come for free but rather is accompanied by a decrease in overall model accuracy and performance. Recent work has shown that, in practical robot learning applications, the effects of adversarial training do not pose a fair trade-off but inflict a net loss when measured in holistic robot performance. This work revisits the robustness-accuracy trade-off in robot learning by systematically analyzing if recent advances in robust training methods and theory in conjunction with adversarial robot learning can make adversarial training suitable for real-world robot applications. We evaluate a wide variety of robot learning tasks ranging from autonomous driving in a high-fidelity environment amenable to sim-to-real deployment, to mobile robot gesture recognition. Our results demonstrate that, while these techniques make incremental improvements on the trade-off on a relative scale, the negative side-effects caused by adversarial training still outweigh the improvements by an order of magnitude. We conclude that more substantial advances in robust learning methods are necessary before they can benefit robot learning tasks in practice.
Stability Verification in Stochastic Control Systems via Neural Network Supermartingales
Dec 17, 2021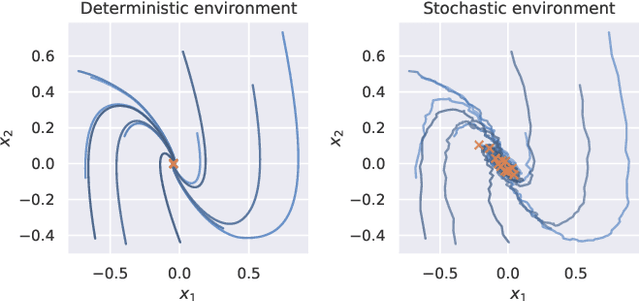

We consider the problem of formally verifying almost-sure (a.s.) asymptotic stability in discrete-time nonlinear stochastic control systems. While verifying stability in deterministic control systems is extensively studied in the literature, verifying stability in stochastic control systems is an open problem. The few existing works on this topic either consider only specialized forms of stochasticity or make restrictive assumptions on the system, rendering them inapplicable to learning algorithms with neural network policies. In this work, we present an approach for general nonlinear stochastic control problems with two novel aspects: (a) instead of classical stochastic extensions of Lyapunov functions, we use ranking supermartingales (RSMs) to certify a.s.~asymptotic stability, and (b) we present a method for learning neural network RSMs. We prove that our approach guarantees a.s.~asymptotic stability of the system and provides the first method to obtain bounds on the stabilization time, which stochastic Lyapunov functions do not. Finally, we validate our approach experimentally on a set of nonlinear stochastic reinforcement learning environments with neural network policies.