 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolynomial-time Algorithms for Combinatorial Pure Exploration with Full-bandit Feedback
Feb 27, 2019
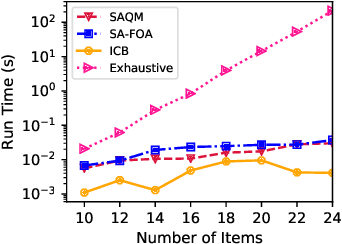
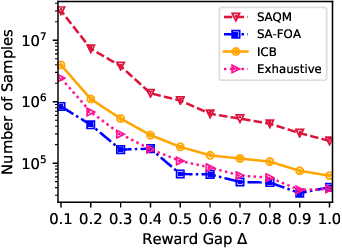
We study the problem of stochastic combinatorial pure exploration (CPE), where an agent sequentially pulls a set of single arms (a.k.a. a super arm) and tries to find the best super arm. Among a variety of problem settings of the CPE, we focus on the full-bandit setting, where we cannot observe the reward of each single arm, but only the sum of the rewards. Although we can regard the CPE with full-bandit feedback as a special case of pure exploration in linear bandits, an approach based on linear bandits is not computationally feasible since the number of super arms may be exponential. In this paper, we first propose a polynomial-time bandit algorithm for the CPE under general combinatorial constraints and provide an upper bound of the sample complexity. Second, we design an approximation algorithm for the 0-1 quadratic maximization problem, which arises in many bandit algorithms with confidence ellipsoids. Based on our approximation algorithm, we propose novel bandit algorithms for the top-k selection problem, and prove that our algorithms run in polynomial time. Finally, we conduct experiments on synthetic and real-world datasets, and confirm the validity of our theoretical analysis in terms of both the computation time and the sample complexity.
An analytic formulation for positive-unlabeled learning via weighted integral probability metric
Feb 08, 2019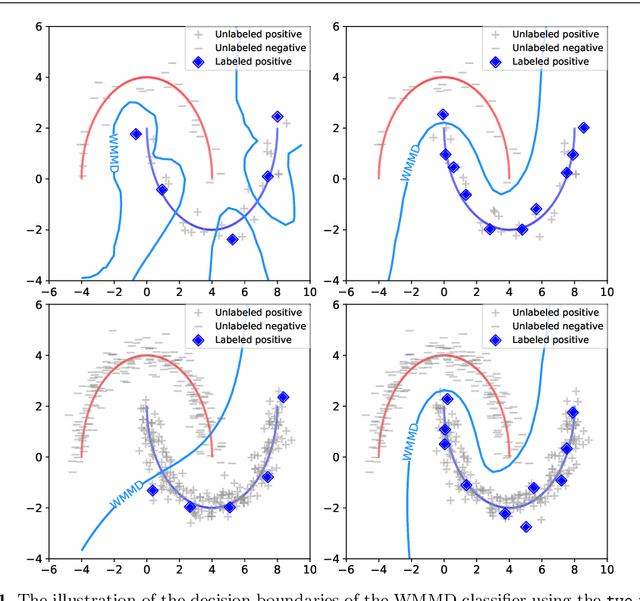

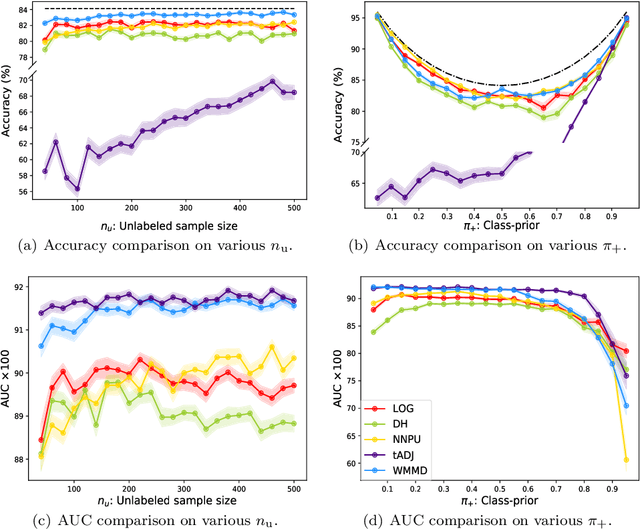
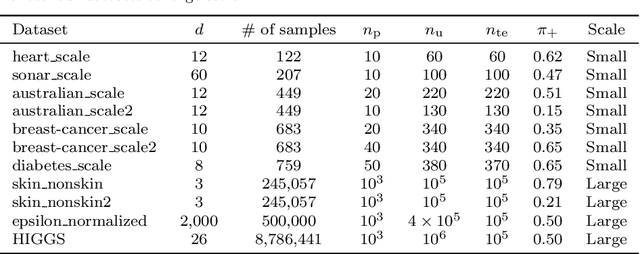
We consider the problem of learning a binary classifier from only positive and unlabeled observations (PU learning). Although recent research in PU learning has succeeded in showing theoretical and empirical performance, most existing algorithms need to solve either a convex or a non-convex optimization problem and thus are not suitable for large-scale datasets. In this paper, we propose a simple yet theoretically grounded PU learning algorithm by extending the previous work proposed for supervised binary classification (Sriperumbudur et al., 2012). The proposed PU learning algorithm produces a closed-form classifier when the hypothesis space is a closed ball in reproducing kernel Hilbert space. In addition, we establish upper bounds of the estimation error and the excess risk. The obtained estimation error bound is sharper than existing results and the excess risk bound does not rely on an approximation error term. To the best of our knowledge, we are the first to explicitly derive the excess risk bound in the field of PU learning. Finally, we conduct extensive numerical experiments using both synthetic and real datasets, demonstrating improved accuracy, scalability, and robustness of the proposed algorithm.
Online Multiclass Classification Based on Prediction Margin for Partial Feedback
Feb 04, 2019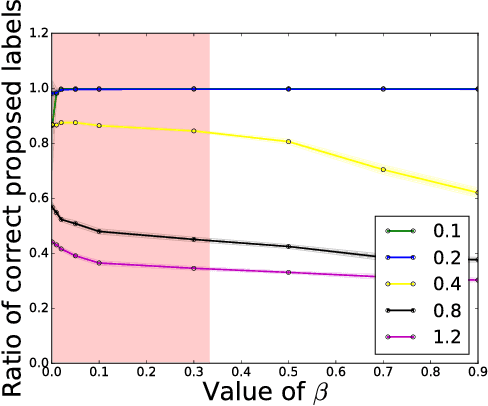
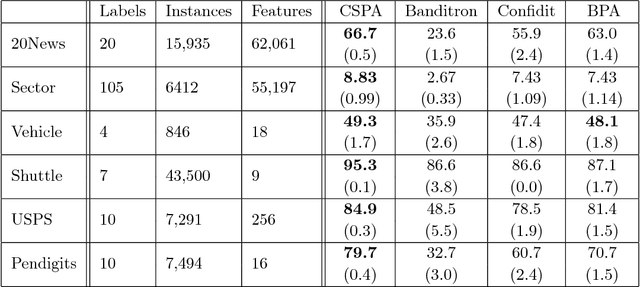
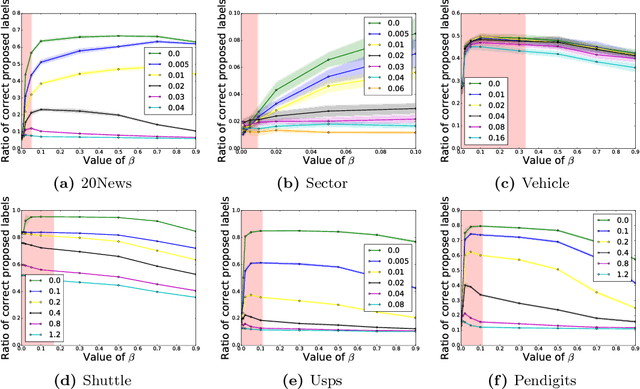
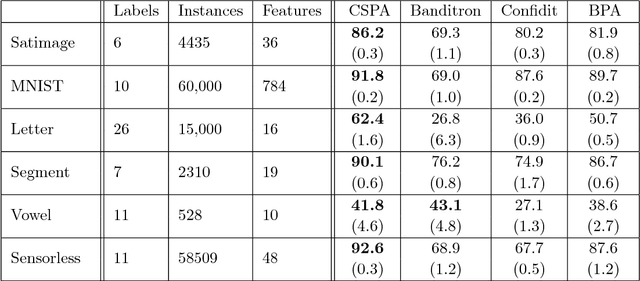
We consider the problem of online multiclass classification with partial feedback, where an algorithm predicts a class for a new instance in each round and only receives its correctness. Although several methods have been developed for this problem, recent challenging real-world applications require further performance improvement. In this paper, we propose a novel online learning algorithm inspired by recent work on learning from complementary labels, where a complementary label indicates a class to which an instance does not belong. This allows us to handle partial feedback deterministically in a margin-based way, where the prediction margin has been recognized as a key to superior empirical performance. We provide a theoretical guarantee based on a cumulative loss bound and experimentally demonstrate that our method outperforms existing methods which are non-margin-based and stochastic.
Semi-Supervised Ordinal Regression Based on Empirical Risk Minimization
Jan 31, 2019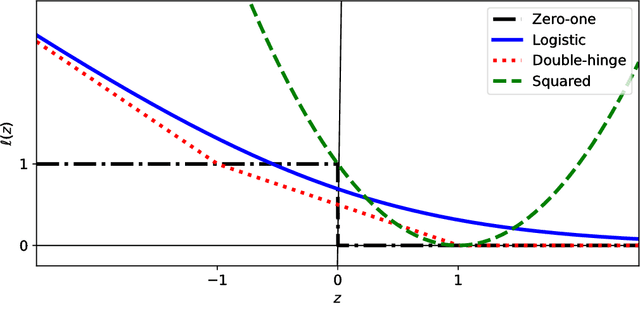
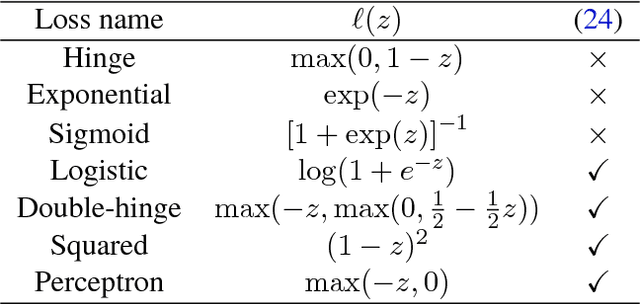
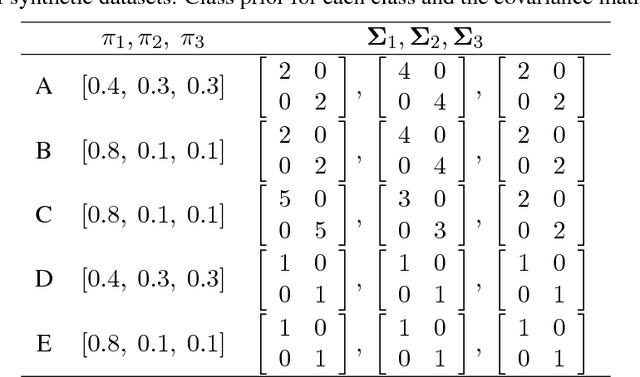
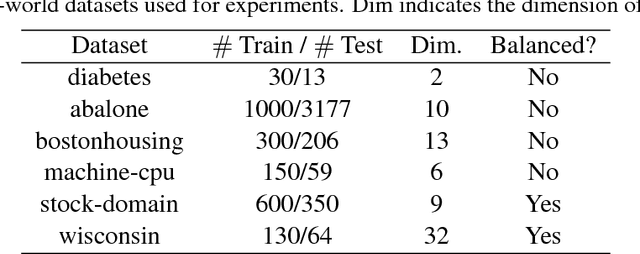
We consider the semi-supervised ordinal regression problem, where unlabeled data are given in addition to ordinal labeled data. There are many evaluation metrics in ordinal regression such as the mean absolute error, mean squared error, and mean classification error. Existing work does not take the evaluation metric into account, has a restriction on the model choice, and has no theoretical guarantee. To mitigate these problems, we propose a method based on the empirical risk minimization (ERM) framework that is applicable to optimizing all of the metrics mentioned above. Also, our method has flexible choices of models, surrogate losses, and optimization algorithms. Moreover, our method does not require a restrictive assumption on unlabeled data such as the cluster assumption and manifold assumption. We provide an estimation error bound to show that our learning method is consistent. Finally, we conduct experiments to show the usefulness of our framework.
New Tricks for Estimating Gradients of Expectations
Jan 31, 2019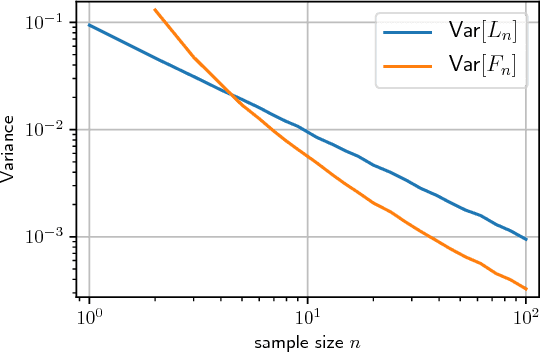

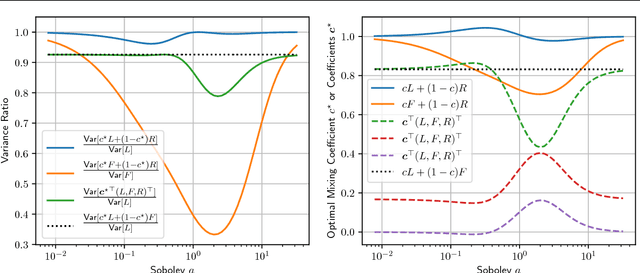
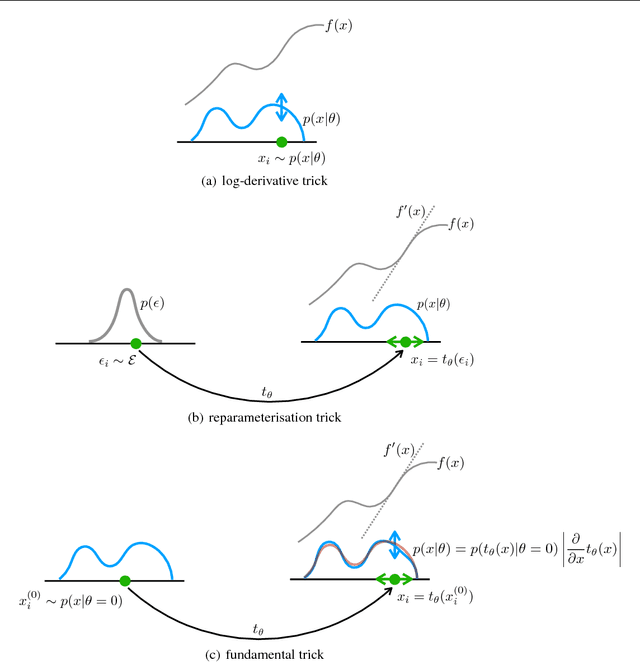
We derive a family of Monte Carlo estimators for gradients of expectations of univariate distributions, which is related to the log-derivative trick, but involves pairwise interactions between samples. The first of these comes from either a) introducing and approximating an integral representation based on the fundamental theorem of calculus, or b) applying the reparameterisation trick to an implicit parameterisation under infinitesimal perturbation of the parameters. From the former perspective we generalise to a reproducing kernel Hilbert space representation, giving rise to locality parameter in the pairwise interactions mentioned above. The resulting estimators are unbiased and shown to offer an independent component of useful information in comparison with the log-derivative estimator. Promising analytical and numerical examples confirm the intuitions behind the new estimators.
On Possibility and Impossibility of Multiclass Classification with Rejection
Jan 30, 2019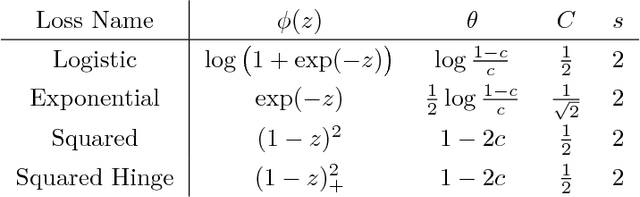
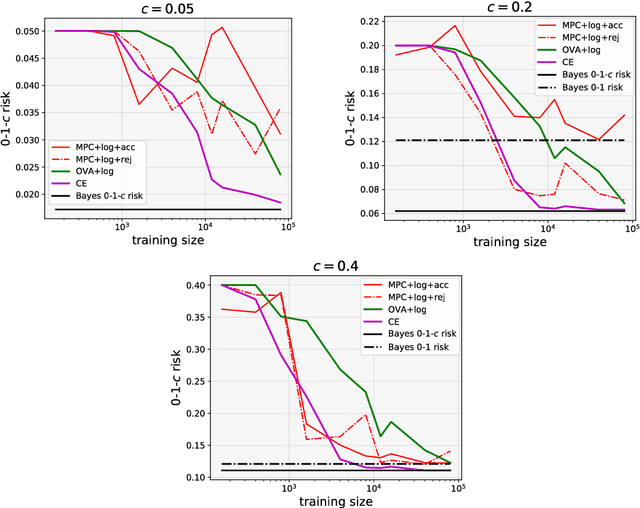

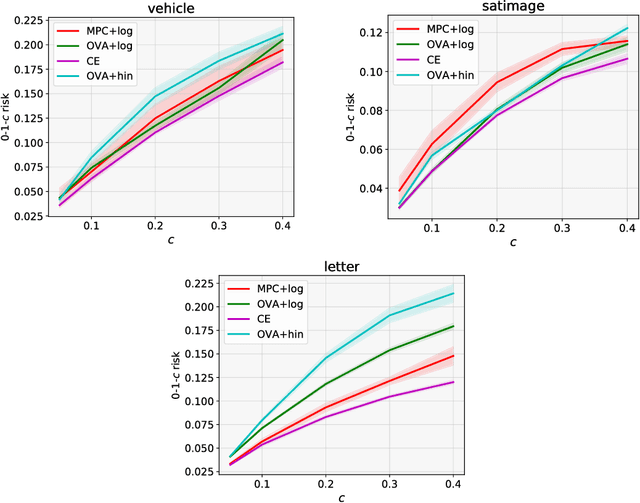
We investigate the problem of multiclass classification with rejection, where a classifier can choose not to make a prediction to avoid critical misclassification. We consider two approaches for this problem: a traditional one based on confidence scores and a more recent one based on simultaneous training of a classifier and a rejector. An existing method in the former approach focuses on a specific class of losses and its empirical performance is not very convincing. In this paper, we propose confidence-based rejection criteria for multiclass classification, which can handle more general losses and guarantee calibration to the Bayes-optimal solution. The latter approach is relatively new and has been available only for the binary case, to the best of our knowledge. Our second contribution is to prove that calibration to the Bayes-optimal solution is almost impossible by this approach in the multiclass case. Finally, we conduct experiments to validate the relevance of our theoretical findings.
Domain Discrepancy Measure Using Complex Models in Unsupervised Domain Adaptation
Jan 30, 2019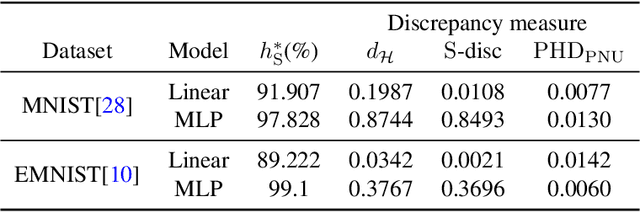
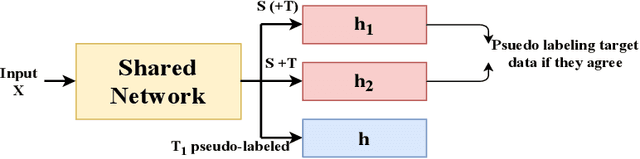
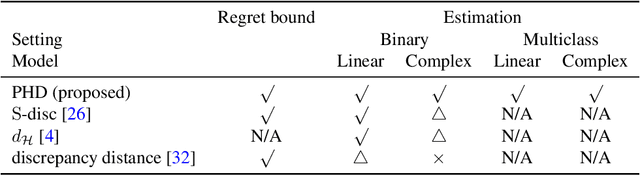
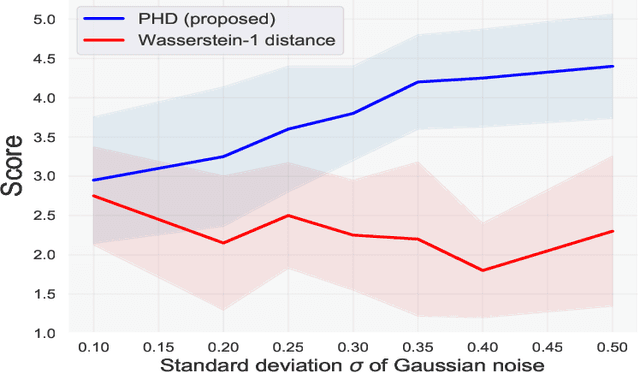
We address the problem of measuring the difference between two domains in unsupervised domain adaptation. We point out that the existing discrepancy measures are less informative when complex models such as deep neural networks are applied. Furthermore, estimation of the existing discrepancy measures can be computationally difficult and only limited to the binary classification task. To mitigate these shortcomings, we propose a novel discrepancy measure that is very simple to estimate for many tasks not limited to binary classification, theoretically-grounded, and can be applied effectively for complex models. We also provide easy-to-interpret generalization bounds that explain the effectiveness of a family of pseudo-labeling methods in unsupervised domain adaptation. Finally, we conduct experiments to validate the usefulness of our proposed discrepancy measure.
Imitation Learning from Imperfect Demonstration
Jan 30, 2019
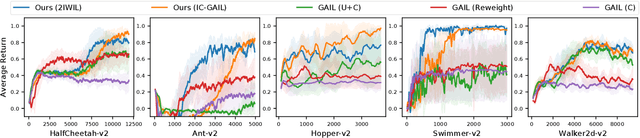
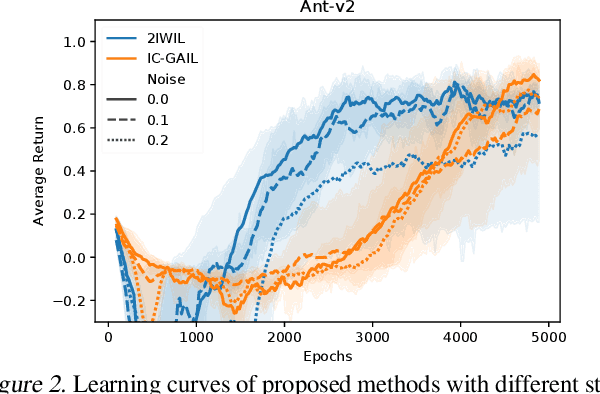
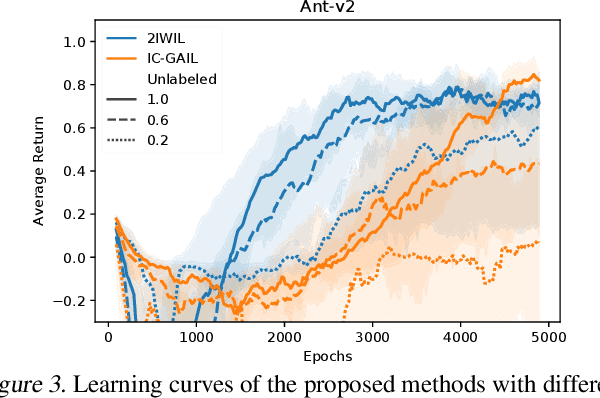
Imitation learning (IL) aims to learn an optimal policy from demonstrations. However, such demonstrations are often imperfect since collecting optimal ones is costly. To effectively learn from imperfect demonstrations, we propose a novel approach that utilizes confidence scores, which describe the quality of demonstrations. More specifically, we propose two confidence-based IL methods, namely two-step importance weighting IL (2IWIL) and generative adversarial IL with imperfect demonstration and confidence (IC-GAIL). We show that confidence scores given only to a small portion of sub-optimal demonstrations significantly improve the performance of IL both theoretically and empirically.
Revisiting Sample Selection Approach to Positive-Unlabeled Learning: Turning Unlabeled Data into Positive rather than Negative
Jan 29, 2019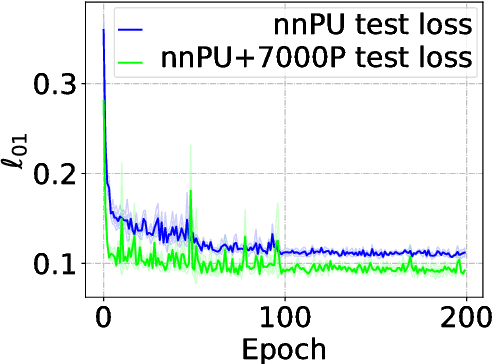

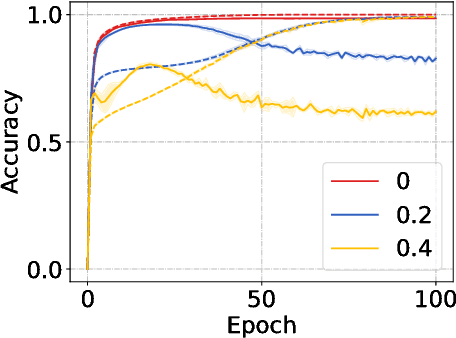
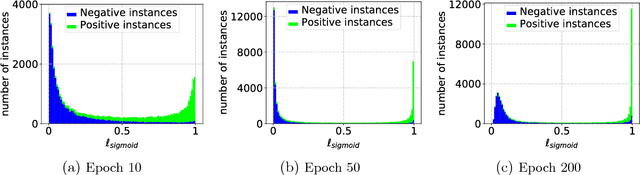
In the early history of positive-unlabeled (PU) learning, the sample selection approach, which heuristically selects negative (N) data from U data, was explored extensively. However, this approach was later dominated by the importance reweighting approach, which carefully treats all U data as N data. May there be a new sample selection method that can outperform the latest importance reweighting method in the deep learning age? This paper is devoted to answering this question affirmatively---we propose to label large-loss U data as P, based on the memorization properties of deep networks. Since P data selected in such a way are biased, we develop a novel learning objective that can handle such biased P data properly. Experiments confirm the superiority of the proposed method.
Normalized Flat Minima: Exploring Scale Invariant Definition of Flat Minima for Neural Networks using PAC-Bayesian Analysis
Jan 28, 2019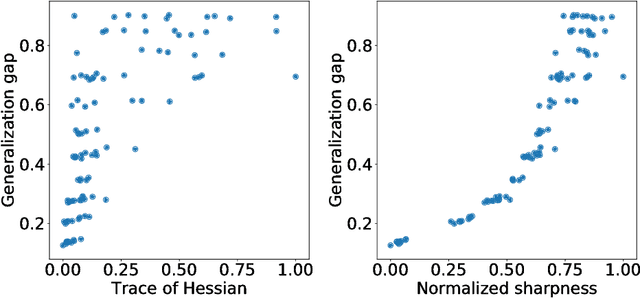


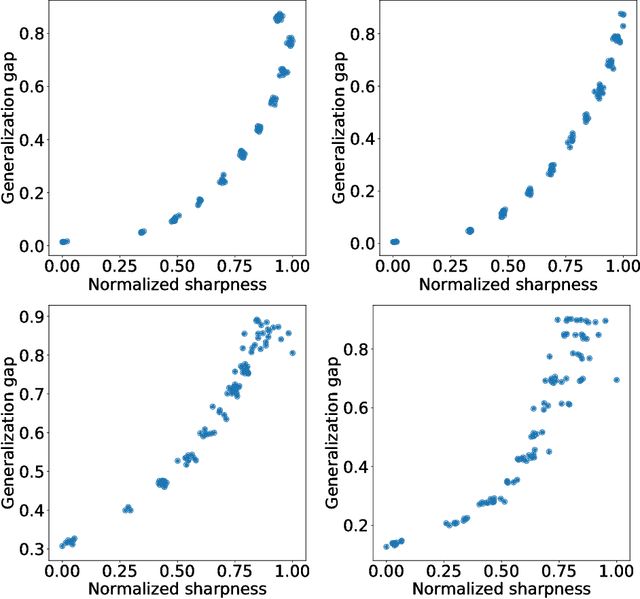
The notion of flat minima has played a key role in the generalization studies of deep learning models. However, existing definitions of the flatness are known to be sensitive to the rescaling of parameters. The issue suggests that the previous definitions of the flatness might not be a good measure of generalization, because generalization is invariant to such rescalings. In this paper, from the PAC-Bayesian perspective, we scrutinize the discussion concerning the flat minima and introduce the notion of normalized flat minima, which is free from the known scale dependence issues. Additionally, we highlight the scale dependence of existing matrix-norm based generalization error bounds similar to the existing flat minima definitions. Our modified notion of the flatness does not suffer from the insufficiency, either, suggesting it might provide better hierarchy in the hypothesis class.