 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably End-to-end Label-Noise Learning without Anchor Points
Feb 04, 2021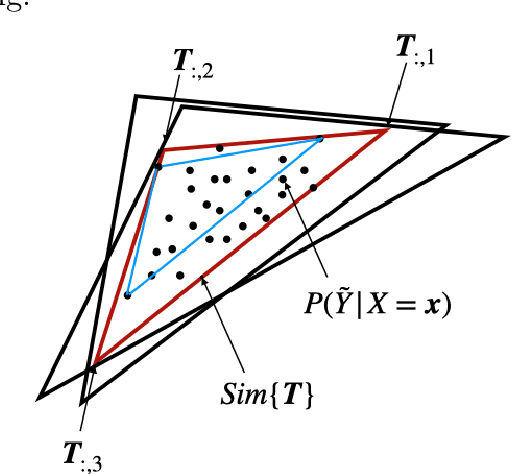
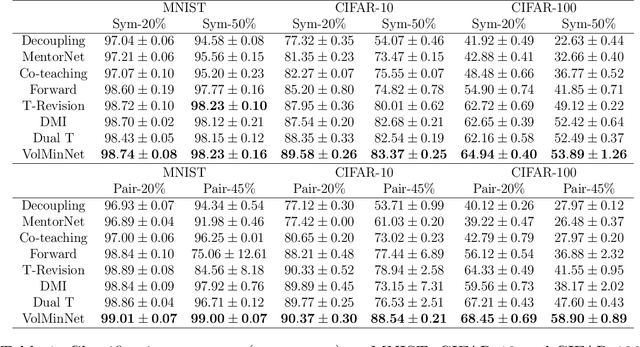
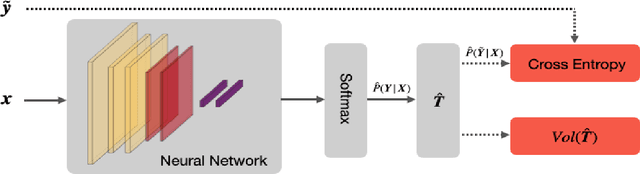
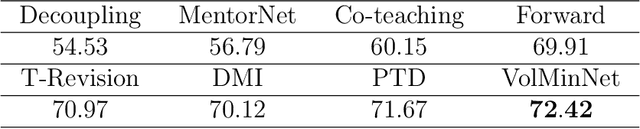
In label-noise learning, the transition matrix plays a key role in building statistically consistent classifiers. Existing consistent estimators for the transition matrix have been developed by exploiting anchor points. However, the anchor-point assumption is not always satisfied in real scenarios. In this paper, we propose an end-to-end framework for solving label-noise learning without anchor points, in which we simultaneously minimize two objectives: the discrepancy between the distribution learned by the neural network and the noisy class-posterior distribution, and the volume of the simplex formed by the columns of the transition matrix. Our proposed framework can identify the transition matrix if the clean class-posterior probabilities are sufficiently scattered. This is by far the mildest assumption under which the transition matrix is provably identifiable and the learned classifier is statistically consistent. Experimental results on benchmark datasets demonstrate the effectiveness and robustness of the proposed method.
Binary Classification from Multiple Unlabeled Datasets via Surrogate Set Classification
Feb 01, 2021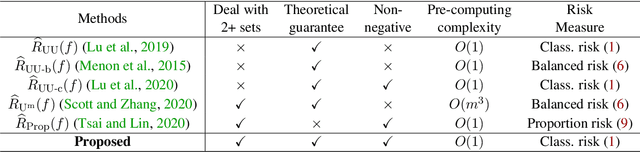
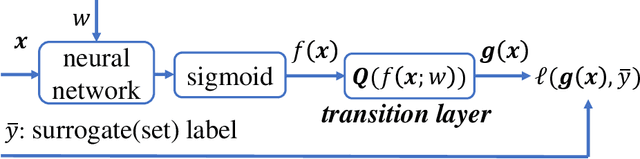
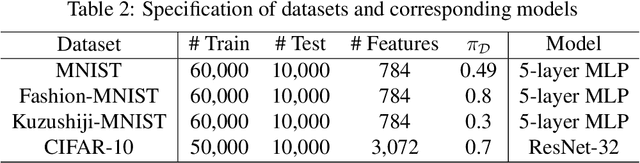
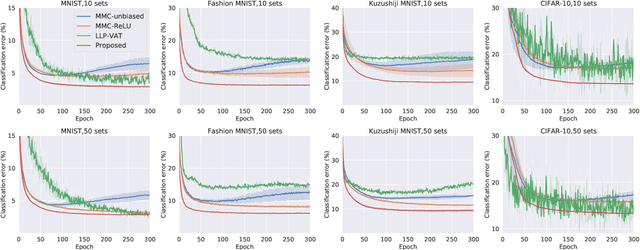
To cope with high annotation costs, training a classifier only from weakly supervised data has attracted a great deal of attention these days. Among various approaches, strengthening supervision from completely unsupervised classification is a promising direction, which typically employs class priors as the only supervision and trains a binary classifier from unlabeled (U) datasets. While existing risk-consistent methods are theoretically grounded with high flexibility, they can learn only from two U sets. In this paper, we propose a new approach for binary classification from m U-sets for $m\ge2$. Our key idea is to consider an auxiliary classification task called surrogate set classification (SSC), which is aimed at predicting from which U set each observed data is drawn. SSC can be solved by a standard (multi-class) classification method, and we use the SSC solution to obtain the final binary classifier through a certain linear-fractional transformation. We built our method in a flexible and efficient end-to-end deep learning framework and prove it to be classifier-consistent. Through experiments, we demonstrate the superiority of our proposed method over state-of-the-art methods.
Source-free Domain Adaptation via Distributional Alignment by Matching Batch Normalization Statistics
Jan 19, 2021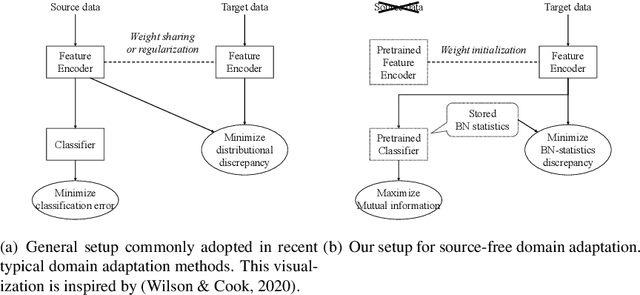
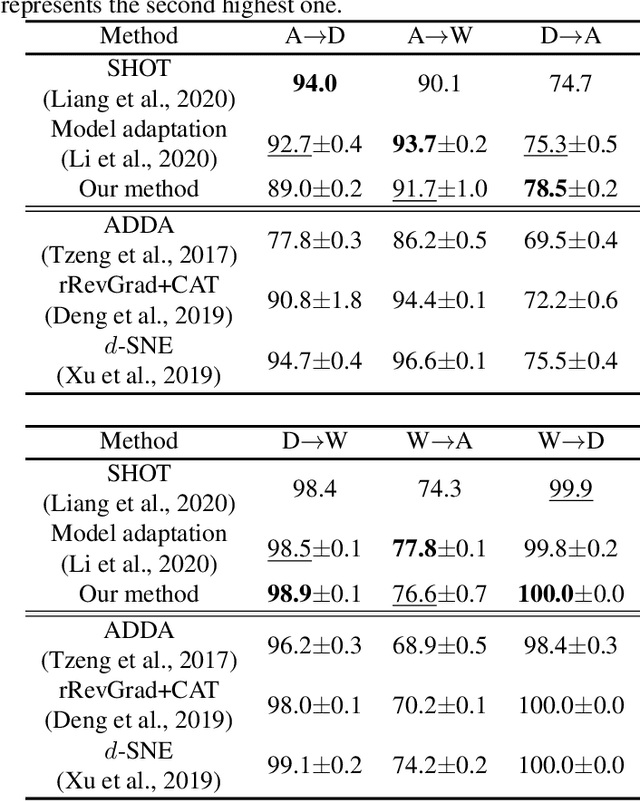
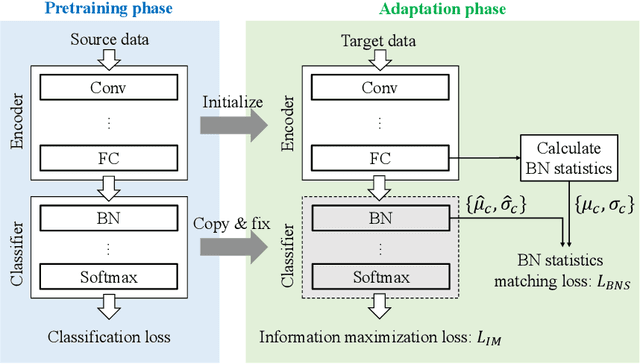

In this paper, we propose a novel domain adaptation method for the source-free setting. In this setting, we cannot access source data during adaptation, while unlabeled target data and a model pretrained with source data are given. Due to lack of source data, we cannot directly match the data distributions between domains unlike typical domain adaptation algorithms. To cope with this problem, we propose utilizing batch normalization statistics stored in the pretrained model to approximate the distribution of unobserved source data. Specifically, we fix the classifier part of the model during adaptation and only fine-tune the remaining feature encoder part so that batch normalization statistics of the features extracted by the encoder match those stored in the fixed classifier. Additionally, we also maximize the mutual information between the features and the classifier's outputs to further boost the classification performance. Experimental results with several benchmark datasets show that our method achieves competitive performance with state-of-the-art domain adaptation methods even though it does not require access to source data.
A Symmetric Loss Perspective of Reliable Machine Learning
Jan 05, 2021
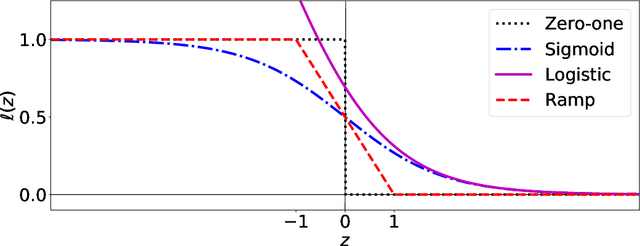
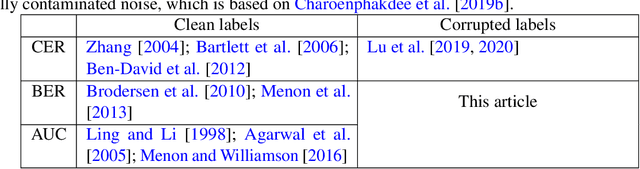
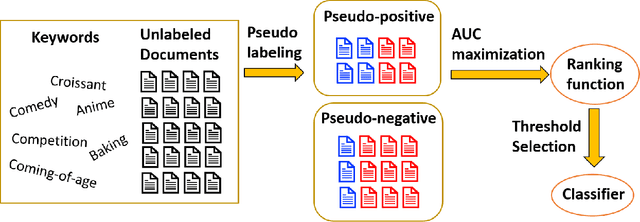
When minimizing the empirical risk in binary classification, it is a common practice to replace the zero-one loss with a surrogate loss to make the learning objective feasible to optimize. Examples of well-known surrogate losses for binary classification include the logistic loss, hinge loss, and sigmoid loss. It is known that the choice of a surrogate loss can highly influence the performance of the trained classifier and therefore it should be carefully chosen. Recently, surrogate losses that satisfy a certain symmetric condition (aka., symmetric losses) have demonstrated their usefulness in learning from corrupted labels. In this article, we provide an overview of symmetric losses and their applications. First, we review how a symmetric loss can yield robust classification from corrupted labels in balanced error rate (BER) minimization and area under the receiver operating characteristic curve (AUC) maximization. Then, we demonstrate how the robust AUC maximization method can benefit natural language processing in the problem where we want to learn only from relevant keywords and unlabeled documents. Finally, we conclude this article by discussing future directions, including potential applications of symmetric losses for reliable machine learning and the design of non-symmetric losses that can benefit from the symmetric condition.
Combinatorial Pure Exploration with Full-bandit Feedback and Beyond: Solving Combinatorial Optimization under Uncertainty with Limited Observation
Dec 31, 2020
Combinatorial optimization is one of the fundamental research fields that has been extensively studied in theoretical computer science and operations research. When developing an algorithm for combinatorial optimization, it is commonly assumed that parameters such as edge weights are exactly known as inputs. However, this assumption may not be fulfilled since input parameters are often uncertain or initially unknown in many applications such as recommender systems, crowdsourcing, communication networks, and online advertisement. To resolve such uncertainty, the problem of combinatorial pure exploration of multi-armed bandits (CPE) and its variants have recieved increasing attention. Earlier work on CPE has studied the semi-bandit feedback or assumed that the outcome from each individual edge is always accessible at all rounds. However, due to practical constraints such as a budget ceiling or privacy concern, such strong feedback is not always available in recent applications. In this article, we review recently proposed techniques for combinatorial pure exploration problems with limited feedback.
On Focal Loss for Class-Posterior Probability Estimation: A Theoretical Perspective
Dec 14, 2020
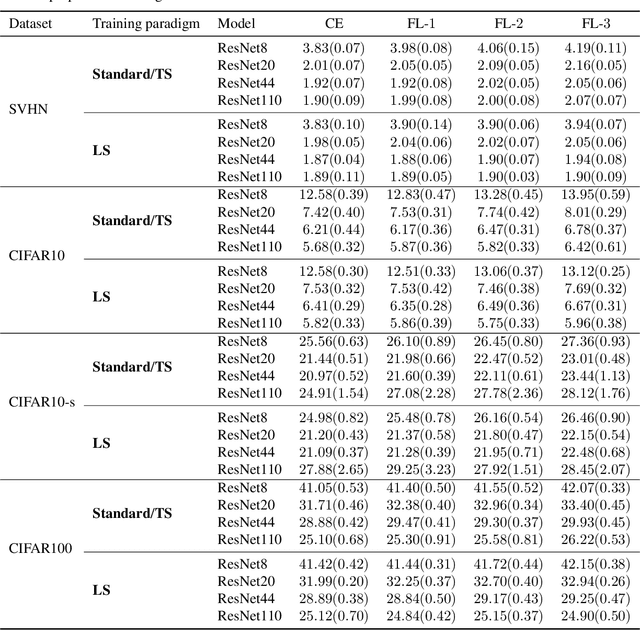
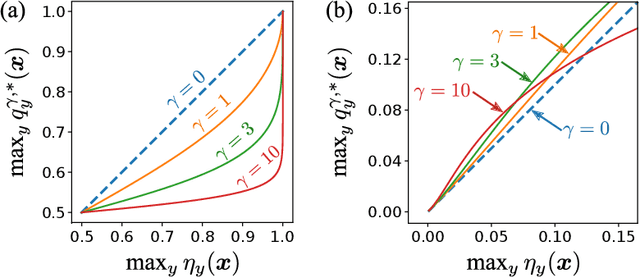
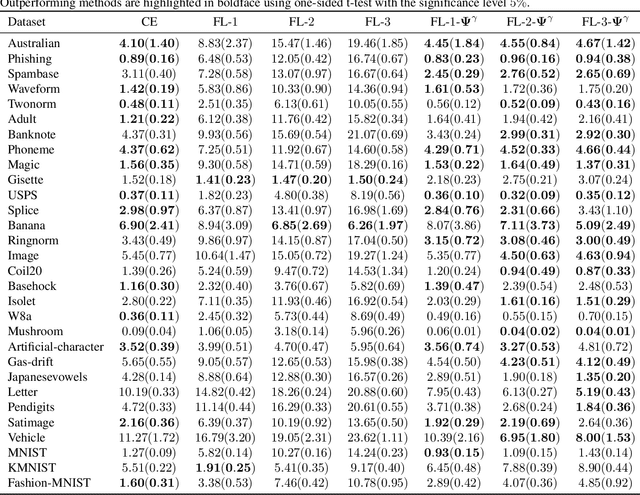
The focal loss has demonstrated its effectiveness in many real-world applications such as object detection and image classification, but its theoretical understanding has been limited so far. In this paper, we first prove that the focal loss is classification-calibrated, i.e., its minimizer surely yields the Bayes-optimal classifier and thus the use of the focal loss in classification can be theoretically justified. However, we also prove a negative fact that the focal loss is not strictly proper, i.e., the confidence score of the classifier obtained by focal loss minimization does not match the true class-posterior probability and thus it is not reliable as a class-posterior probability estimator. To mitigate this problem, we next prove that a particular closed-form transformation of the confidence score allows us to recover the true class-posterior probability. Through experiments on benchmark datasets, we demonstrate that our proposed transformation significantly improves the accuracy of class-posterior probability estimation.
Stable Weight Decay Regularization
Nov 24, 2020
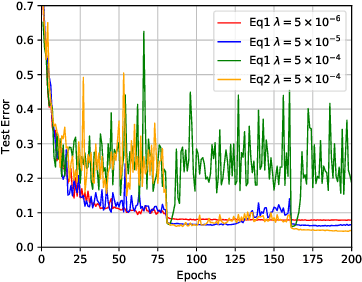
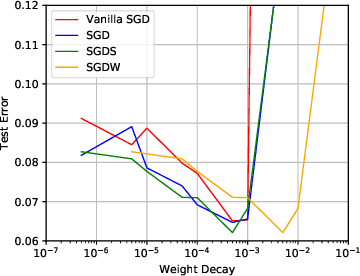

Weight decay is a popular regularization technique for training of deep neural networks. Modern deep learning libraries mainly use $L_{2}$ regularization as the default implementation of weight decay. \citet{loshchilov2018decoupled} demonstrated that $L_{2}$ regularization is not identical to weight decay for adaptive gradient methods, such as Adaptive Momentum Estimation (Adam), and proposed Adam with Decoupled Weight Decay (AdamW). However, we found that the popular implementations of weight decay, including $L_{2}$ regularization and decoupled weight decay, in modern deep learning libraries usually damage performance. First, the $L_{2}$ regularization is unstable weight decay for all optimizers that use Momentum, such as stochastic gradient descent (SGD). Second, decoupled weight decay is highly unstable for all adaptive gradient methods. We further propose the Stable Weight Decay (SWD) method to fix the unstable weight decay problem from a dynamical perspective. The proposed SWD method makes significant improvements over $L_{2}$ regularization and decoupled weight decay in our experiments. Simply fixing weight decay in Adam by SWD, with no extra hyperparameter, can usually outperform complex Adam variants, which have more hyperparameters.
Artificial Neural Variability for Deep Learning: On Overfitting, Noise Memorization, and Catastrophic Forgetting
Nov 24, 2020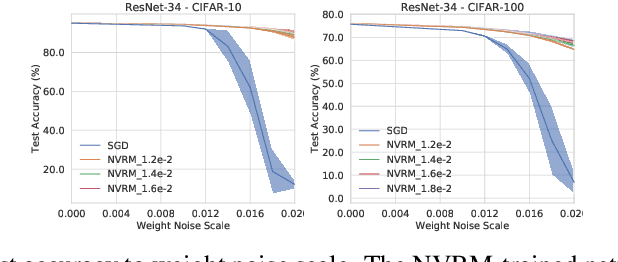
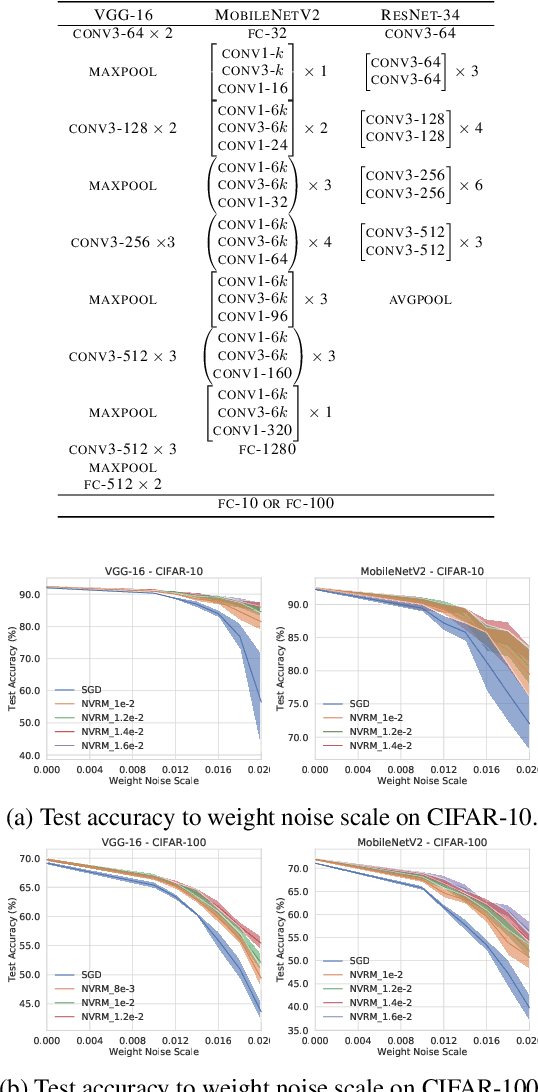
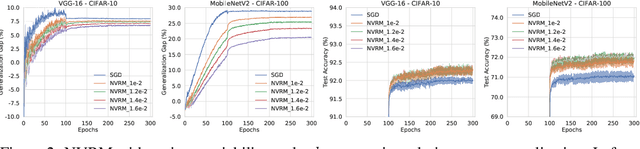
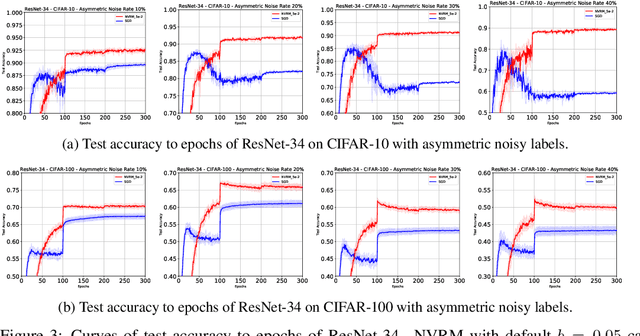
Deep learning is often criticized by two serious issues which rarely exist in natural nervous systems: overfitting and catastrophic forgetting. It can even memorize randomly labelled data, which has little knowledge behind the instance-label pairs. When a deep network continually learns over time by accommodating new tasks, it usually quickly overwrites the knowledge learned from previous tasks. Referred to as the neural variability, it is well-known in neuroscience that human brain reactions exhibit substantial variability even in response to the same stimulus. This mechanism balances accuracy and plasticity/flexibility in the motor learning of natural nervous systems. Thus it motivates us to design a similar mechanism named artificial neural variability (ANV), which helps artificial neural networks learn some advantages from "natural" neural networks. We rigorously prove that ANV plays as an implicit regularizer of the mutual information between the training data and the learned model. This result theoretically guarantees ANV a strictly improved generalizability, robustness to label noise, and robustness to catastrophic forgetting. We then devise a neural variable risk minimization (NVRM) framework and neural variable optimizers to achieve ANV for conventional network architectures in practice. The empirical studies demonstrate that NVRM can effectively relieve overfitting, label noise memorization, and catastrophic forgetting at negligible costs.
A Survey of Label-noise Representation Learning: Past, Present and Future
Nov 09, 2020
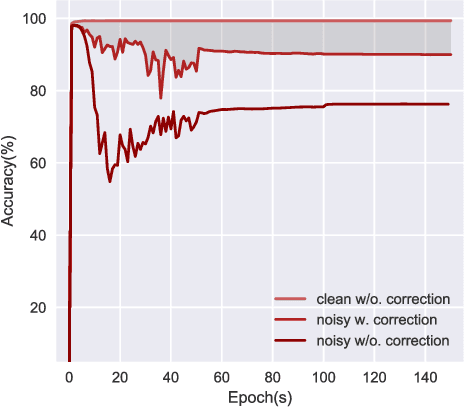
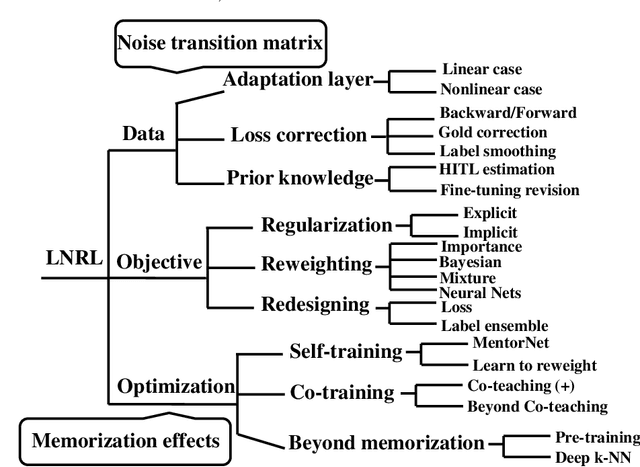
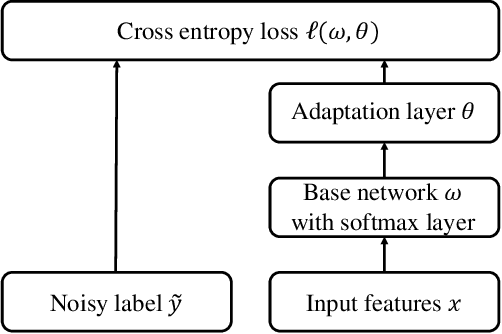
Classical machine learning implicitly assumes that labels of the training data are sampled from a clean distribution, which can be too restrictive for real-world scenarios. However, statistical learning-based methods may not train deep learning models robustly with these noisy labels. Therefore, it is urgent to design Label-Noise Representation Learning (LNRL) methods for robustly training deep models with noisy labels. To fully understand LNRL, we conduct a survey study. We first clarify a formal definition for LNRL from the perspective of machine learning. Then, via the lens of learning theory and empirical study, we figure out why noisy labels affect deep models' performance. Based on the theoretical guidance, we categorize different LNRL methods into three directions. Under this unified taxonomy, we provide a thorough discussion of the pros and cons of different categories. More importantly, we summarize the essential components of robust LNRL, which can spark new directions. Lastly, we propose possible research directions within LNRL, such as new datasets, instance-dependent LNRL, and adversarial LNRL. Finally, we envision potential directions beyond LNRL, such as learning with feature-noise, preference-noise, domain-noise, similarity-noise, graph-noise, and demonstration-noise.
Binary classification with ambiguous training data
Nov 05, 2020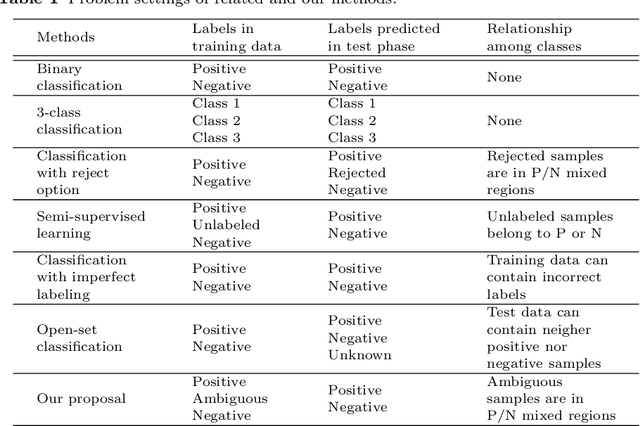
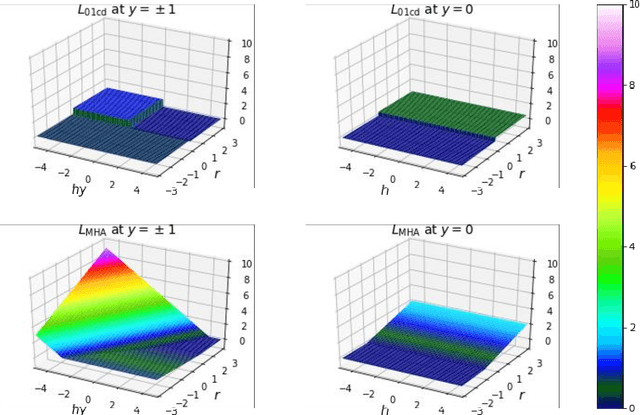
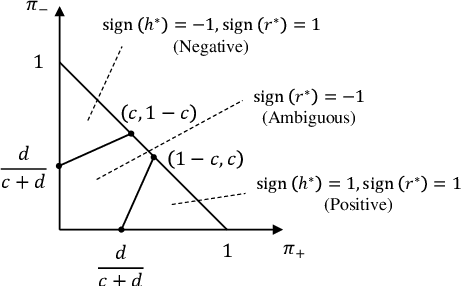
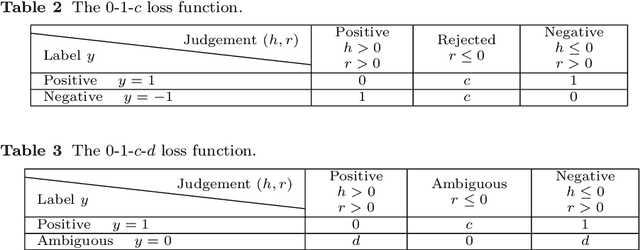
In supervised learning, we often face with ambiguous (A) samples that are difficult to label even by domain experts. In this paper, we consider a binary classification problem in the presence of such A samples. This problem is substantially different from semi-supervised learning since unlabeled samples are not necessarily difficult samples. Also, it is different from 3-class classification with the positive (P), negative (N), and A classes since we do not want to classify test samples into the A class. Our proposed method extends binary classification with reject option, which trains a classifier and a rejector simultaneously using P and N samples based on the 0-1-$c$ loss with rejection cost $c$. More specifically, we propose to train a classifier and a rejector under the 0-1-$c$-$d$ loss using P, N, and A samples, where $d$ is the misclassification penalty for ambiguous samples. In our practical implementation, we use a convex upper bound of the 0-1-$c$-$d$ loss for computational tractability. Numerical experiments demonstrate that our method can successfully utilize the additional information brought by such A training data.
* 20 pages, 6 figures, accepted at the 12th Asian Conference on Machine Learning (ACML 2020)