 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiCE: The Infinitely Differentiable Monte-Carlo Estimator
Sep 19, 2018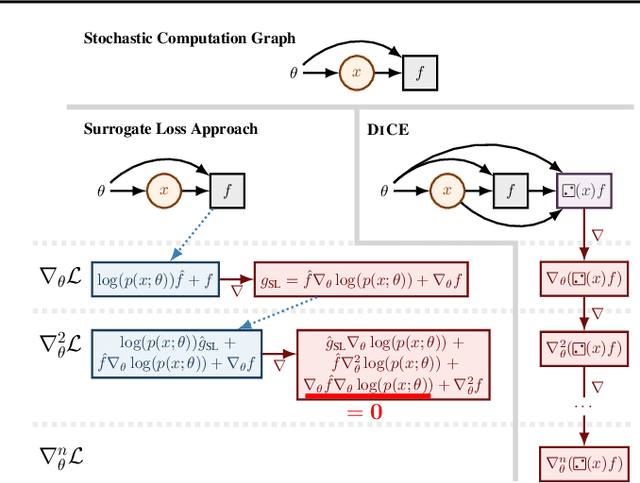
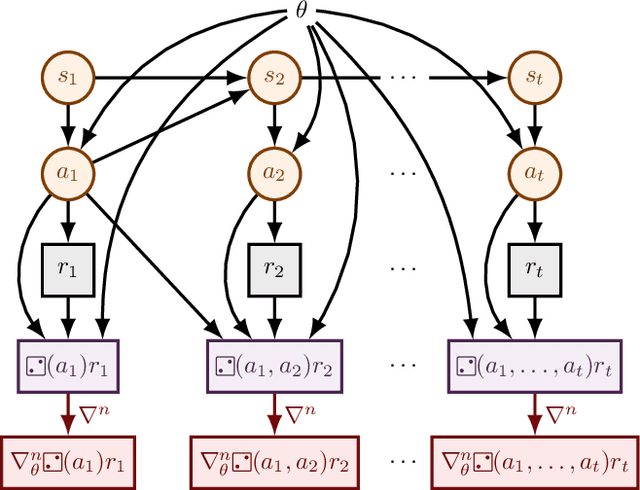
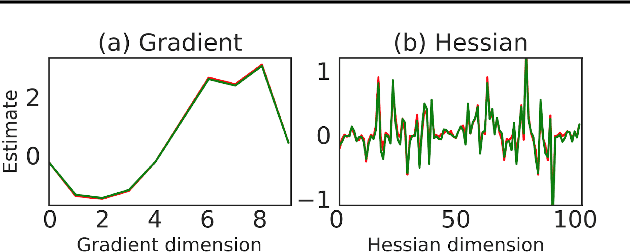
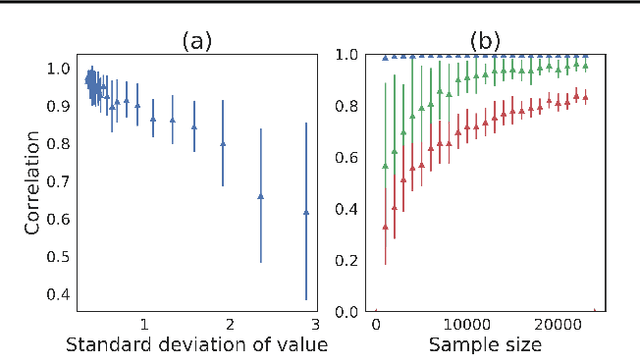
The score function estimator is widely used for estimating gradients of stochastic objectives in stochastic computation graphs (SCG), eg, in reinforcement learning and meta-learning. While deriving the first-order gradient estimators by differentiating a surrogate loss (SL) objective is computationally and conceptually simple, using the same approach for higher-order derivatives is more challenging. Firstly, analytically deriving and implementing such estimators is laborious and not compliant with automatic differentiation. Secondly, repeatedly applying SL to construct new objectives for each order derivative involves increasingly cumbersome graph manipulations. Lastly, to match the first-order gradient under differentiation, SL treats part of the cost as a fixed sample, which we show leads to missing and wrong terms for estimators of higher-order derivatives. To address all these shortcomings in a unified way, we introduce DiCE, which provides a single objective that can be differentiated repeatedly, generating correct estimators of derivatives of any order in SCGs. Unlike SL, DiCE relies on automatic differentiation for performing the requisite graph manipulations. We verify the correctness of DiCE both through a proof and numerical evaluation of the DiCE derivative estimates. We also use DiCE to propose and evaluate a novel approach for multi-agent learning. Our code is available at https://www.github.com/alshedivat/lola.
Learning Policy Representations in Multiagent Systems
Jul 31, 2018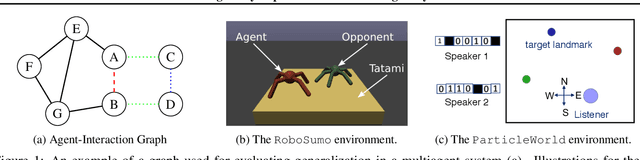
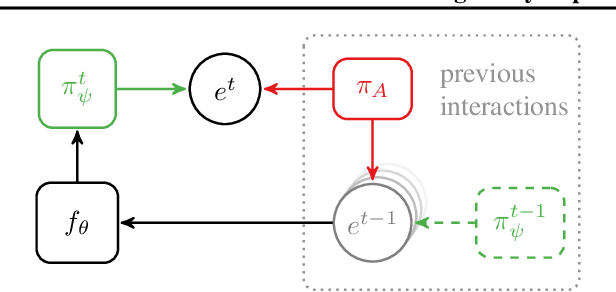
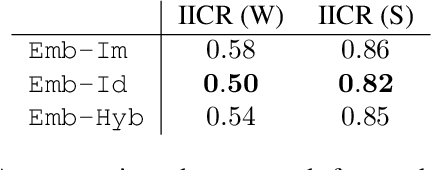
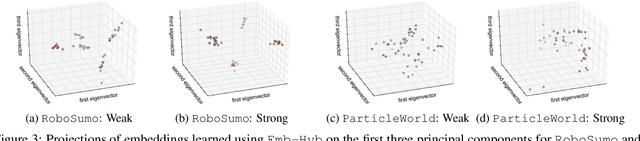
Modeling agent behavior is central to understanding the emergence of complex phenomena in multiagent systems. Prior work in agent modeling has largely been task-specific and driven by hand-engineering domain-specific prior knowledge. We propose a general learning framework for modeling agent behavior in any multiagent system using only a handful of interaction data. Our framework casts agent modeling as a representation learning problem. Consequently, we construct a novel objective inspired by imitation learning and agent identification and design an algorithm for unsupervised learning of representations of agent policies. We demonstrate empirically the utility of the proposed framework in (i) a challenging high-dimensional competitive environment for continuous control and (ii) a cooperative environment for communication, on supervised predictive tasks, unsupervised clustering, and policy optimization using deep reinforcement learning.
Continuous Adaptation via Meta-Learning in Nonstationary and Competitive Environments
Feb 23, 2018


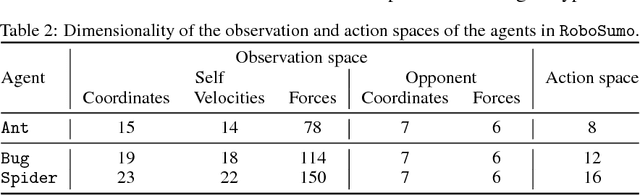
Ability to continuously learn and adapt from limited experience in nonstationary environments is an important milestone on the path towards general intelligence. In this paper, we cast the problem of continuous adaptation into the learning-to-learn framework. We develop a simple gradient-based meta-learning algorithm suitable for adaptation in dynamically changing and adversarial scenarios. Additionally, we design a new multi-agent competitive environment, RoboSumo, and define iterated adaptation games for testing various aspects of continuous adaptation strategies. We demonstrate that meta-learning enables significantly more efficient adaptation than reactive baselines in the few-shot regime. Our experiments with a population of agents that learn and compete suggest that meta-learners are the fittest.
Personalized Survival Prediction with Contextual Explanation Networks
Jan 30, 2018
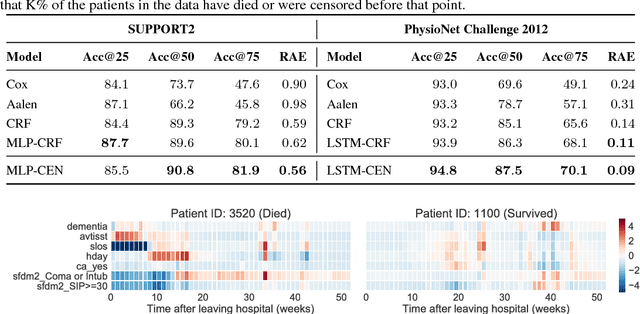
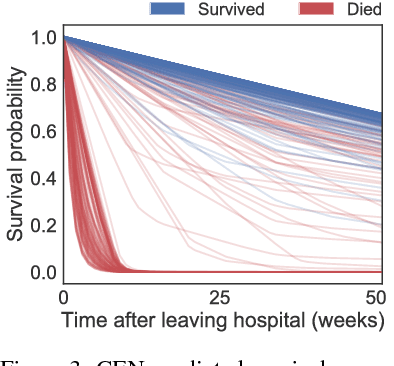
Accurate and transparent prediction of cancer survival times on the level of individual patients can inform and improve patient care and treatment practices. In this paper, we design a model that concurrently learns to accurately predict patient-specific survival distributions and to explain its predictions in terms of patient attributes such as clinical tests or assessments. Our model is flexible and based on a recurrent network, can handle various modalities of data including temporal measurements, and yet constructs and uses simple explanations in the form of patient- and time-specific linear regression. For analysis, we use two publicly available datasets and show that our networks outperform a number of baselines in prediction while providing a way to inspect the reasons behind each prediction.
The Intriguing Properties of Model Explanations
Jan 30, 2018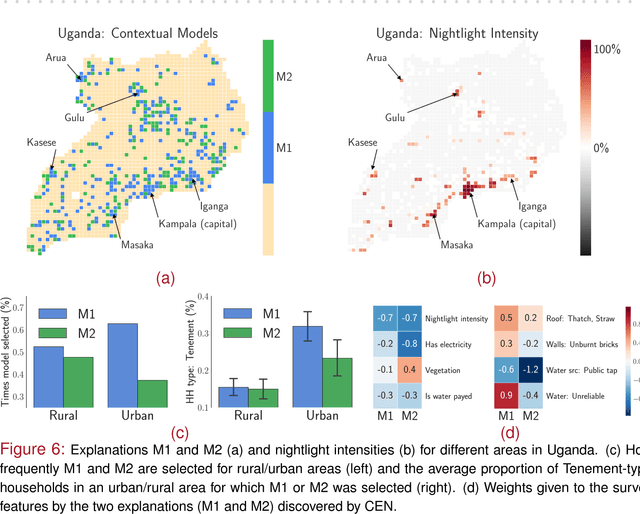
Linear approximations to the decision boundary of a complex model have become one of the most popular tools for interpreting predictions. In this paper, we study such linear explanations produced either post-hoc by a few recent methods or generated along with predictions with contextual explanation networks (CENs). We focus on two questions: (i) whether linear explanations are always consistent or can be misleading, and (ii) when integrated into the prediction process, whether and how explanations affect the performance of the model. Our analysis sheds more light on certain properties of explanations produced by different methods and suggests that learning models that explain and predict jointly is often advantageous.
Contextual Explanation Networks
Jan 30, 2018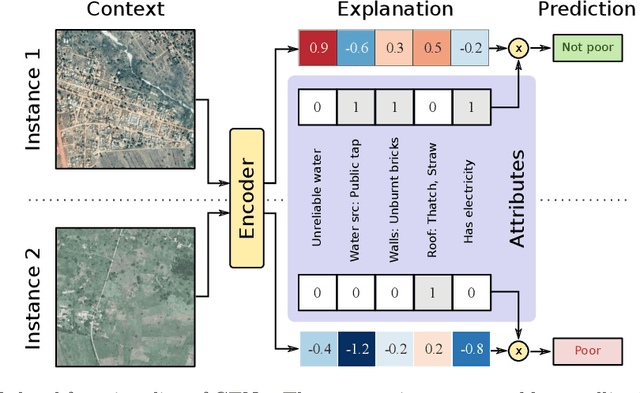

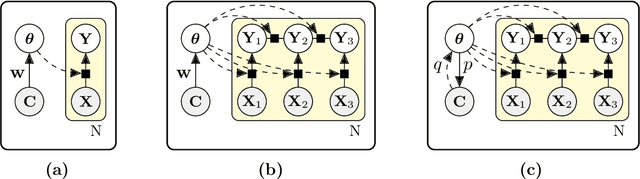
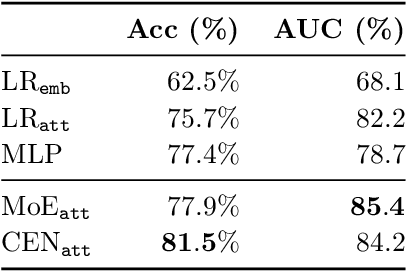
We introduce contextual explanation networks (CENs)---a class of models that learn to predict by generating and leveraging intermediate explanations. CENs are deep networks that generate parameters for context-specific probabilistic graphical models which are further used for prediction and play the role of explanations. Contrary to the existing post-hoc model-explanation tools, CENs learn to predict and to explain jointly. Our approach offers two major advantages: (i) for each prediction, valid instance-specific explanations are generated with no computational overhead and (ii) prediction via explanation acts as a regularization and boosts performance in low-resource settings. We prove that local approximations to the decision boundary of our networks are consistent with the generated explanations. Our results on image and text classification and survival analysis tasks demonstrate that CENs are competitive with the state-of-the-art while offering additional insights behind each prediction, valuable for decision support.
Learning Scalable Deep Kernels with Recurrent Structure
Oct 05, 2017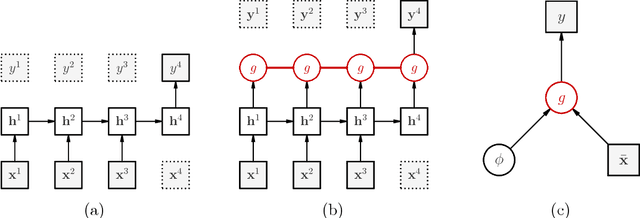
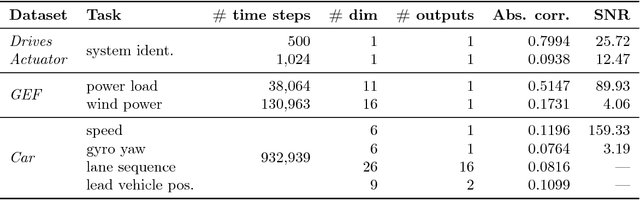
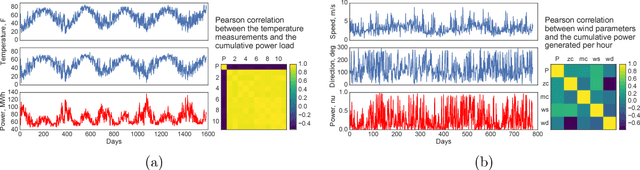
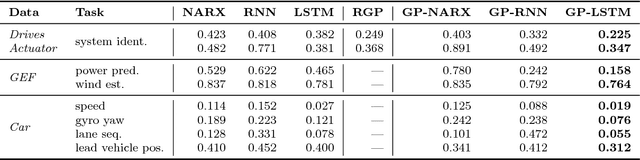
Many applications in speech, robotics, finance, and biology deal with sequential data, where ordering matters and recurrent structures are common. However, this structure cannot be easily captured by standard kernel functions. To model such structure, we propose expressive closed-form kernel functions for Gaussian processes. The resulting model, GP-LSTM, fully encapsulates the inductive biases of long short-term memory (LSTM) recurrent networks, while retaining the non-parametric probabilistic advantages of Gaussian processes. We learn the properties of the proposed kernels by optimizing the Gaussian process marginal likelihood using a new provably convergent semi-stochastic gradient procedure and exploit the structure of these kernels for scalable training and prediction. This approach provides a practical representation for Bayesian LSTMs. We demonstrate state-of-the-art performance on several benchmarks, and thoroughly investigate a consequential autonomous driving application, where the predictive uncertainties provided by GP-LSTM are uniquely valuable.
* 37 pages, 7 figures, 5 tables. Updated to the final version that appears in JMLR, 18(82):1-37, 2017
Stochastic Synapses Enable Efficient Brain-Inspired Learning Machines
Dec 15, 2016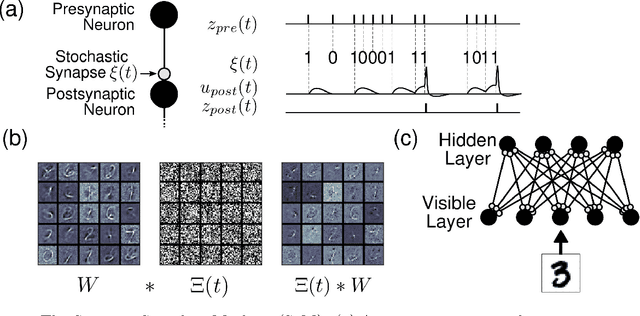
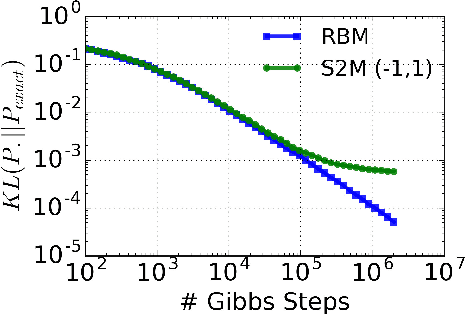
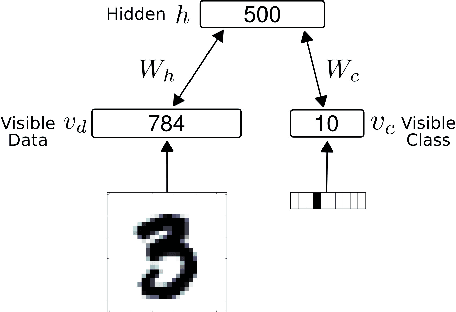
Recent studies have shown that synaptic unreliability is a robust and sufficient mechanism for inducing the stochasticity observed in cortex. Here, we introduce Synaptic Sampling Machines, a class of neural network models that uses synaptic stochasticity as a means to Monte Carlo sampling and unsupervised learning. Similar to the original formulation of Boltzmann machines, these models can be viewed as a stochastic counterpart of Hopfield networks, but where stochasticity is induced by a random mask over the connections. Synaptic stochasticity plays the dual role of an efficient mechanism for sampling, and a regularizer during learning akin to DropConnect. A local synaptic plasticity rule implementing an event-driven form of contrastive divergence enables the learning of generative models in an on-line fashion. Synaptic sampling machines perform equally well using discrete-timed artificial units (as in Hopfield networks) or continuous-timed leaky integrate & fire neurons. The learned representations are remarkably sparse and robust to reductions in bit precision and synapse pruning: removal of more than 75% of the weakest connections followed by cursory re-learning causes a negligible performance loss on benchmark classification tasks. The spiking neuron-based synaptic sampling machines outperform existing spike-based unsupervised learners, while potentially offering substantial advantages in terms of power and complexity, and are thus promising models for on-line learning in brain-inspired hardware.
Learning HMMs with Nonparametric Emissions via Spectral Decompositions of Continuous Matrices
Sep 21, 2016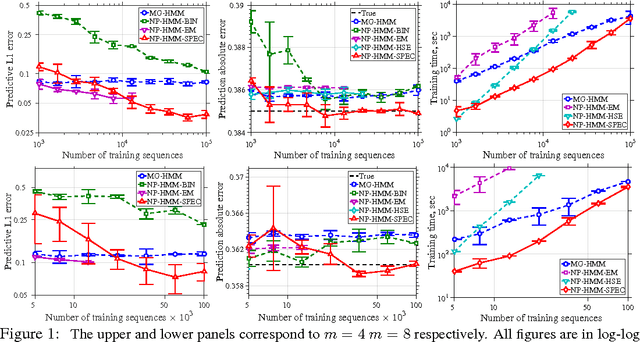


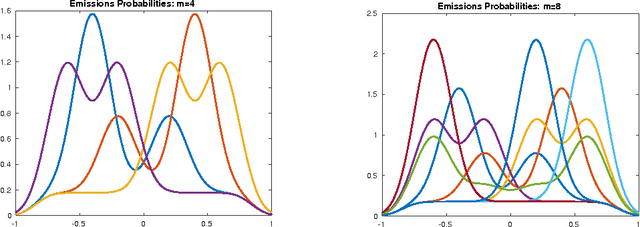
Recently, there has been a surge of interest in using spectral methods for estimating latent variable models. However, it is usually assumed that the distribution of the observations conditioned on the latent variables is either discrete or belongs to a parametric family. In this paper, we study the estimation of an $m$-state hidden Markov model (HMM) with only smoothness assumptions, such as H\"olderian conditions, on the emission densities. By leveraging some recent advances in continuous linear algebra and numerical analysis, we develop a computationally efficient spectral algorithm for learning nonparametric HMMs. Our technique is based on computing an SVD on nonparametric estimates of density functions by viewing them as \emph{continuous matrices}. We derive sample complexity bounds via concentration results for nonparametric density estimation and novel perturbation theory results for continuous matrices. We implement our method using Chebyshev polynomial approximations. Our method is competitive with other baselines on synthetic and real problems and is also very computationally efficient.
Learning Non-deterministic Representations with Energy-based Ensembles
Apr 22, 2015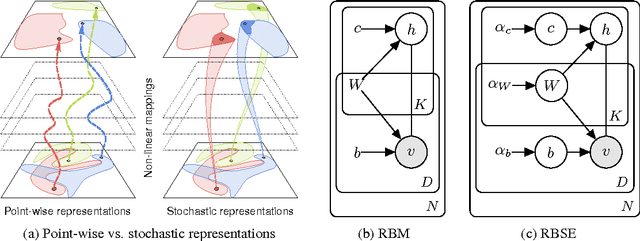
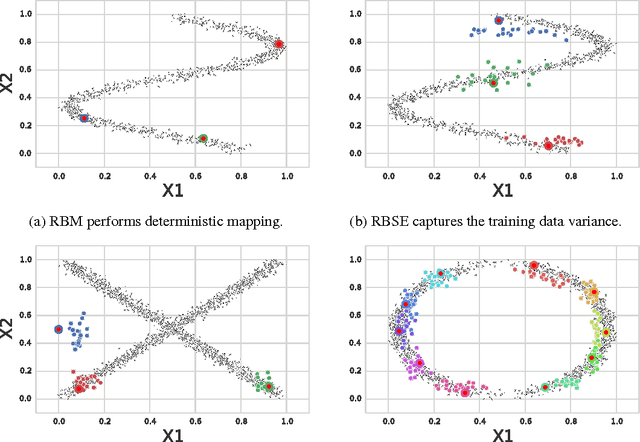
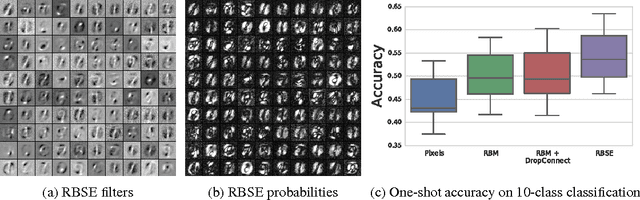
The goal of a generative model is to capture the distribution underlying the data, typically through latent variables. After training, these variables are often used as a new representation, more effective than the original features in a variety of learning tasks. However, the representations constructed by contemporary generative models are usually point-wise deterministic mappings from the original feature space. Thus, even with representations robust to class-specific transformations, statistically driven models trained on them would not be able to generalize when the labeled data is scarce. Inspired by the stochasticity of the synaptic connections in the brain, we introduce Energy-based Stochastic Ensembles. These ensembles can learn non-deterministic representations, i.e., mappings from the feature space to a family of distributions in the latent space. These mappings are encoded in a distribution over a (possibly infinite) collection of models. By conditionally sampling models from the ensemble, we obtain multiple representations for every input example and effectively augment the data. We propose an algorithm similar to contrastive divergence for training restricted Boltzmann stochastic ensembles. Finally, we demonstrate the concept of the stochastic representations on a synthetic dataset as well as test them in the one-shot learning scenario on MNIST.