 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Meta-Learning in Contextual Bandits
Jun 09, 2020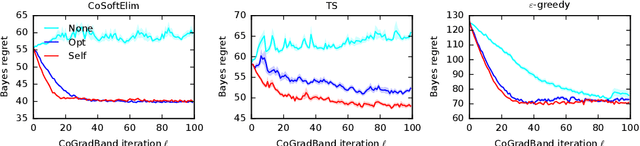
We study a contextual bandit setting where the learning agent has access to sampled bandit instances from an unknown prior distribution $\mathcal{P}$. The goal of the agent is to achieve high reward on average over the instances drawn from $\mathcal{P}$. This setting is of a particular importance because it formalizes the offline optimization of bandit policies, to perform well on average over anticipated bandit instances. The main idea in our work is to optimize differentiable bandit policies by policy gradients. We derive reward gradients that reflect the structure of our problem, and propose contextual policies that are parameterized in a differentiable way and have low regret. Our algorithmic and theoretical contributions are supported by extensive experiments that show the importance of baseline subtraction, learned biases, and the practicality of our approach on a range of classification tasks.
Differentiable Bandit Exploration
Feb 17, 2020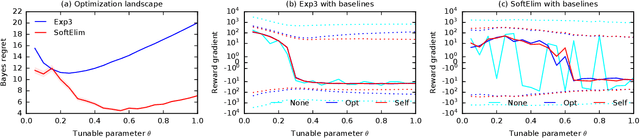
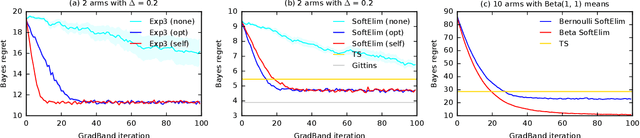
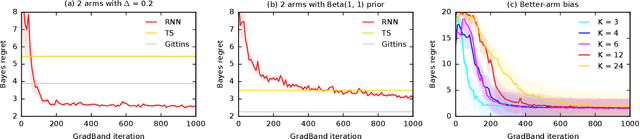
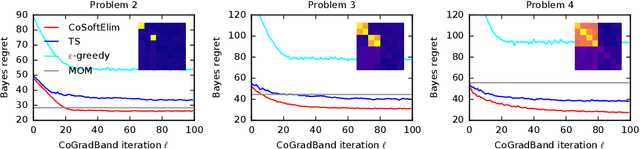
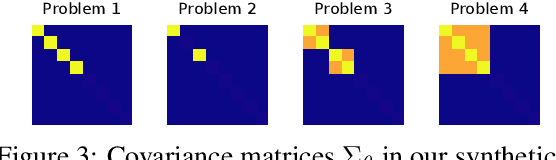
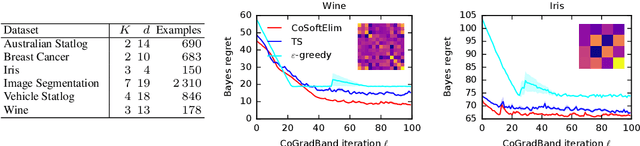
We learn bandit policies that maximize the average reward over bandit instances drawn from an unknown distribution $\mathcal{P}$, from a sample from $\mathcal{P}$. Our approach is an instance of meta-learning and its appeal is that the properties of $\mathcal{P}$ can be exploited without restricting it. We parameterize our policies in a differentiable way and optimize them by policy gradients - an approach that is easy to implement and pleasantly general. Then the challenge is to design effective gradient estimators and good policy classes. To make policy gradients practical, we introduce novel variance reduction techniques. We experiment with various bandit policy classes, including neural networks and a novel soft-elimination policy. The latter has regret guarantees and is a natural starting point for our optimization. Our experiments highlight the versatility of our approach. We also observe that neural network policies can learn implicit biases, which are only expressed through sampled bandit instances during training.
RecSim: A Configurable Simulation Platform for Recommender Systems
Sep 26, 2019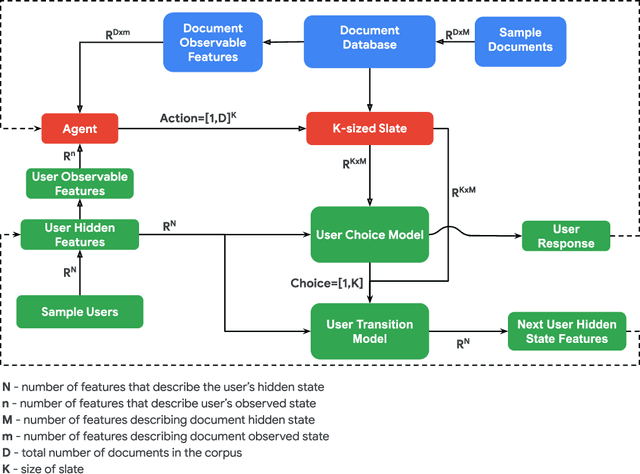
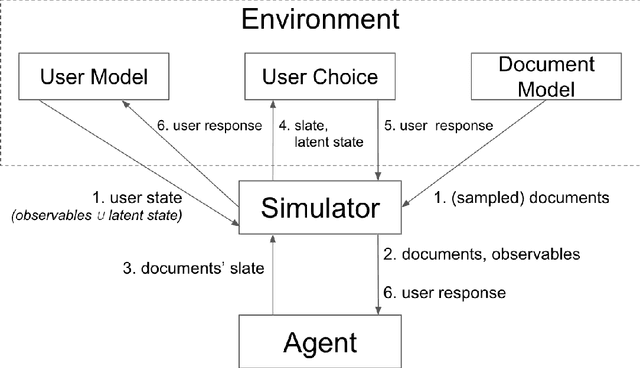
We propose RecSim, a configurable platform for authoring simulation environments for recommender systems (RSs) that naturally supports sequential interaction with users. RecSim allows the creation of new environments that reflect particular aspects of user behavior and item structure at a level of abstraction well-suited to pushing the limits of current reinforcement learning (RL) and RS techniques in sequential interactive recommendation problems. Environments can be easily configured that vary assumptions about: user preferences and item familiarity; user latent state and its dynamics; and choice models and other user response behavior. We outline how RecSim offers value to RL and RS researchers and practitioners, and how it can serve as a vehicle for academic-industrial collaboration.
Advantage Amplification in Slowly Evolving Latent-State Environments
May 29, 2019
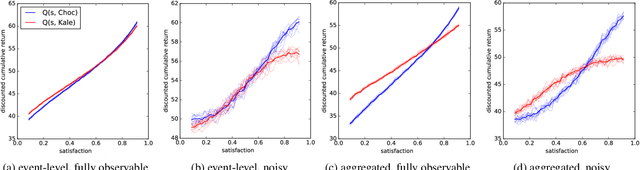
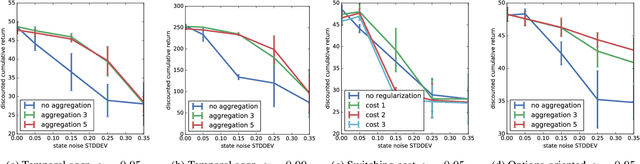
Latent-state environments with long horizons, such as those faced by recommender systems, pose significant challenges for reinforcement learning (RL). In this work, we identify and analyze several key hurdles for RL in such environments, including belief state error and small action advantage. We develop a general principle of advantage amplification that can overcome these hurdles through the use of temporal abstraction. We propose several aggregation methods and prove they induce amplification in certain settings. We also bound the loss in optimality incurred by our methods in environments where latent state evolves slowly and demonstrate their performance empirically in a stylized user-modeling task.
Empirical Bayes Regret Minimization
Apr 04, 2019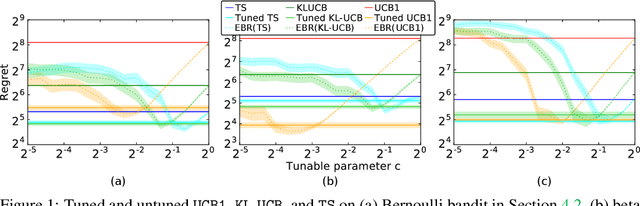

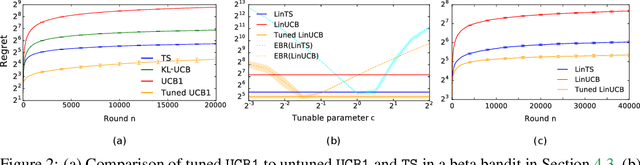
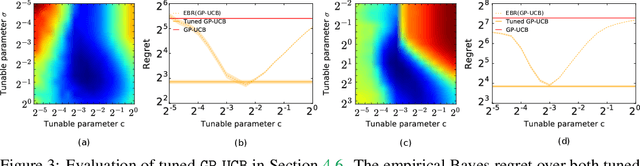
The prevalent approach to bandit algorithm design is to have a low-regret algorithm by design. While celebrated, this approach is often conservative because it ignores many intricate properties of actual problem instances. In this work, we pioneer the idea of minimizing an empirical approximation to the Bayes regret, the expected regret with respect to a distribution over problems. This approach can be viewed as an instance of learning-to-learn, it is conceptually straightforward, and easy to implement. We conduct a comprehensive empirical study of empirical Bayes regret minimization in a wide range of bandit problems, from Bernoulli bandits to structured problems, such as generalized linear and Gaussian process bandits. We report significant improvements over state-of-the-art bandit algorithms, often by an order of magnitude, by simply optimizing over a sample from the distribution.
Planning and Learning with Stochastic Action Sets
May 07, 2018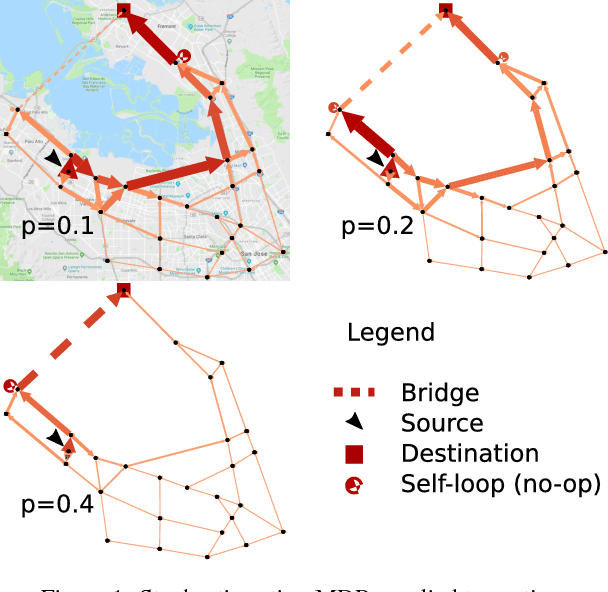
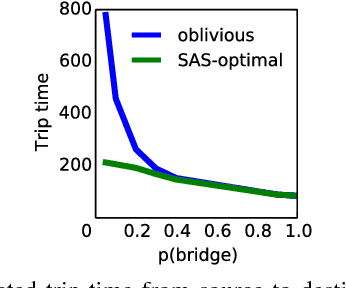
In many practical uses of reinforcement learning (RL) the set of actions available at a given state is a random variable, with realizations governed by an exogenous stochastic process. Somewhat surprisingly, the foundations for such sequential decision processes have been unaddressed. In this work, we formalize and investigate MDPs with stochastic action sets (SAS-MDPs) to provide these foundations. We show that optimal policies and value functions in this model have a structure that admits a compact representation. From an RL perspective, we show that Q-learning with sampled action sets is sound. In model-based settings, we consider two important special cases: when individual actions are available with independent probabilities; and a sampling-based model for unknown distributions. We develop poly-time value and policy iteration methods for both cases; and in the first, we offer a poly-time linear programming solution.
The Symbolic Interior Point Method
Jun 14, 2016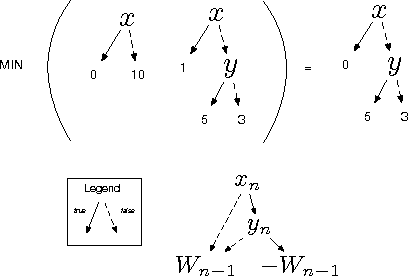
A recent trend in probabilistic inference emphasizes the codification of models in a formal syntax, with suitable high-level features such as individuals, relations, and connectives, enabling descriptive clarity, succinctness and circumventing the need for the modeler to engineer a custom solver. Unfortunately, bringing these linguistic and pragmatic benefits to numerical optimization has proven surprisingly challenging. In this paper, we turn to these challenges: we introduce a rich modeling language, for which an interior-point method computes approximate solutions in a generic way. While logical features easily complicates the underlying model, often yielding intricate dependencies, we exploit and cache local structure using algebraic decision diagrams (ADDs). Indeed, standard matrix-vector algebra is efficiently realizable in ADDs, but we argue and show that well-known optimization methods are not ideal for ADDs. Our engine, therefore, invokes a sophisticated matrix-free approach. We demonstrate the flexibility of the resulting symbolic-numeric optimizer on decision making and compressed sensing tasks with millions of non-zero entries.
Lifted Convex Quadratic Programming
Jun 14, 2016

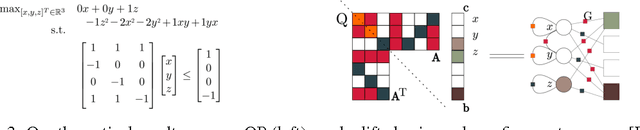

Symmetry is the essential element of lifted inference that has recently demon- strated the possibility to perform very efficient inference in highly-connected, but symmetric probabilistic models models. This raises the question, whether this holds for optimisation problems in general. Here we show that for a large class of optimisation methods this is actually the case. More precisely, we introduce the concept of fractional symmetries of convex quadratic programs (QPs), which lie at the heart of many machine learning approaches, and exploit it to lift, i.e., to compress QPs. These lifted QPs can then be tackled with the usual optimization toolbox (off-the-shelf solvers, cutting plane algorithms, stochastic gradients etc.). If the original QP exhibits symmetry, then the lifted one will generally be more compact, and hence their optimization is likely to be more efficient.
Relational Linear Programs
Oct 12, 2014
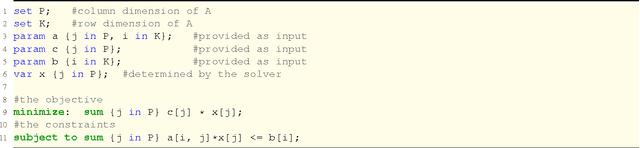


We propose relational linear programming, a simple framework for combing linear programs (LPs) and logic programs. A relational linear program (RLP) is a declarative LP template defining the objective and the constraints through the logical concepts of objects, relations, and quantified variables. This allows one to express the LP objective and constraints relationally for a varying number of individuals and relations among them without enumerating them. Together with a logical knowledge base, effectively a logical program consisting of logical facts and rules, it induces a ground LP. This ground LP is solved using lifted linear programming. That is, symmetries within the ground LP are employed to reduce its dimensionality, if possible, and the reduced program is solved using any off-the-shelf LP solver. In contrast to mainstream LP template languages like AMPL, which features a mixture of declarative and imperative programming styles, RLP's relational nature allows a more intuitive representation of optimization problems over relational domains. We illustrate this empirically by experiments on approximate inference in Markov logic networks using LP relaxations, on solving Markov decision processes, and on collective inference using LP support vector machines.
Dimension Reduction via Colour Refinement
Apr 30, 2014
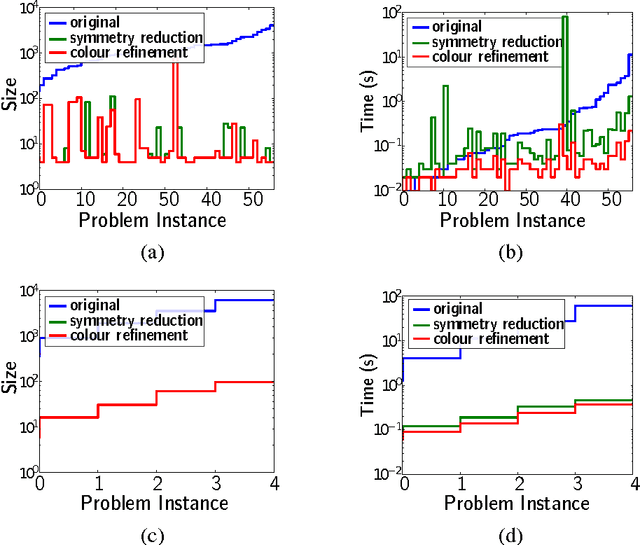
Colour refinement is a basic algorithmic routine for graph isomorphism testing, appearing as a subroutine in almost all practical isomorphism solvers. It partitions the vertices of a graph into "colour classes" in such a way that all vertices in the same colour class have the same number of neighbours in every colour class. Tinhofer (Disc. App. Math., 1991), Ramana, Scheinerman, and Ullman (Disc. Math., 1994) and Godsil (Lin. Alg. and its App., 1997) established a tight correspondence between colour refinement and fractional isomorphisms of graphs, which are solutions to the LP relaxation of a natural ILP formulation of graph isomorphism. We introduce a version of colour refinement for matrices and extend existing quasilinear algorithms for computing the colour classes. Then we generalise the correspondence between colour refinement and fractional automorphisms and develop a theory of fractional automorphisms and isomorphisms of matrices. We apply our results to reduce the dimensions of systems of linear equations and linear programs. Specifically, we show that any given LP L can efficiently be transformed into a (potentially) smaller LP L' whose number of variables and constraints is the number of colour classes of the colour refinement algorithm, applied to a matrix associated with the LP. The transformation is such that we can easily (by a linear mapping) map both feasible and optimal solutions back and forth between the two LPs. We demonstrate empirically that colour refinement can indeed greatly reduce the cost of solving linear programs.