 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Bayes Regret Minimization
Paper and Code
Apr 04, 2019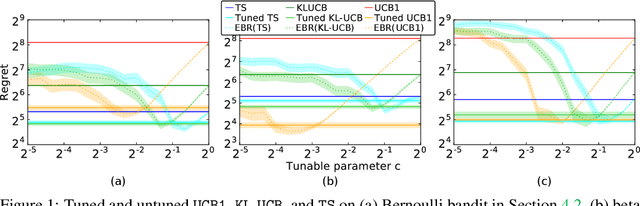

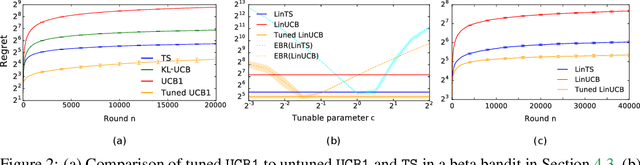
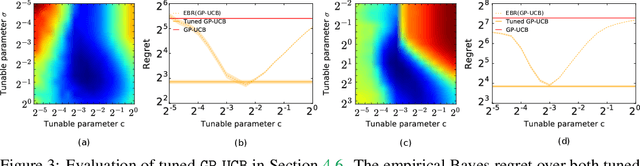
The prevalent approach to bandit algorithm design is to have a low-regret algorithm by design. While celebrated, this approach is often conservative because it ignores many intricate properties of actual problem instances. In this work, we pioneer the idea of minimizing an empirical approximation to the Bayes regret, the expected regret with respect to a distribution over problems. This approach can be viewed as an instance of learning-to-learn, it is conceptually straightforward, and easy to implement. We conduct a comprehensive empirical study of empirical Bayes regret minimization in a wide range of bandit problems, from Bernoulli bandits to structured problems, such as generalized linear and Gaussian process bandits. We report significant improvements over state-of-the-art bandit algorithms, often by an order of magnitude, by simply optimizing over a sample from the distribution.